Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing View-Based and Map-Based Semantic Labelling in Real-Time SLAM
Paper and Code
Feb 24, 2020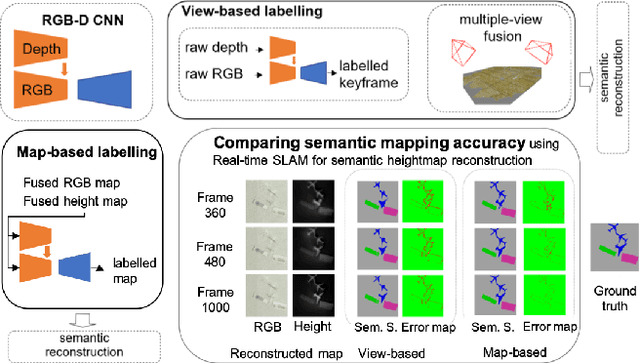
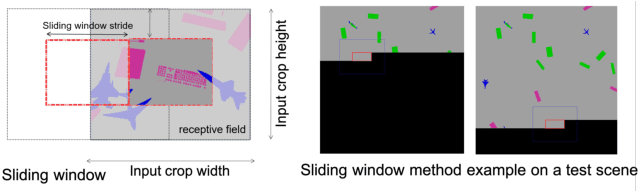
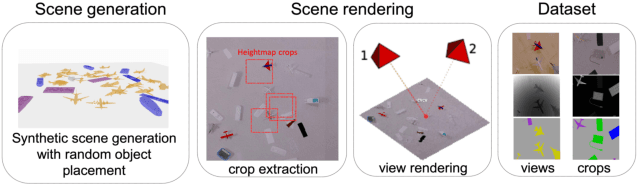
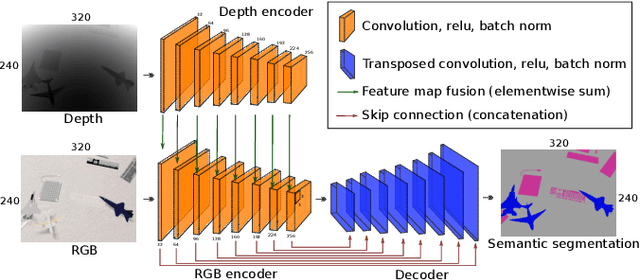
Generally capable Spatial AI systems must build persistent scene representations where geometric models are combined with meaningful semantic labels. The many approaches to labelling scenes can be divided into two clear groups: view-based which estimate labels from the input view-wise data and then incrementally fuse them into the scene model as it is built; and map-based which label the generated scene model. However, there has so far been no attempt to quantitatively compare view-based and map-based labelling. Here, we present an experimental framework and comparison which uses real-time height map fusion as an accessible platform for a fair comparison, opening up the route to further systematic research in this area.
* ICRA 2020
View paper on