 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRE-IMAGINE: Symbolic Benchmark Synthesis for Reasoning Evaluation
Jun 18, 2025Recent Large Language Models (LLMs) have reported high accuracy on reasoning benchmarks. However, it is still unclear whether the observed results arise from true reasoning or from statistical recall of the training set. Inspired by the ladder of causation (Pearl, 2009) and its three levels (associations, interventions and counterfactuals), this paper introduces RE-IMAGINE, a framework to characterize a hierarchy of reasoning ability in LLMs, alongside an automated pipeline to generate problem variations at different levels of the hierarchy. By altering problems in an intermediate symbolic representation, RE-IMAGINE generates arbitrarily many problems that are not solvable using memorization alone. Moreover, the framework is general and can work across reasoning domains, including math, code, and logic. We demonstrate our framework on four widely-used benchmarks to evaluate several families of LLMs, and observe reductions in performance when the models are queried with problem variations. These assessments indicate a degree of reliance on statistical recall for past performance, and open the door to further research targeting skills across the reasoning hierarchy.
A Fourier Space Perspective on Diffusion Models
May 16, 2025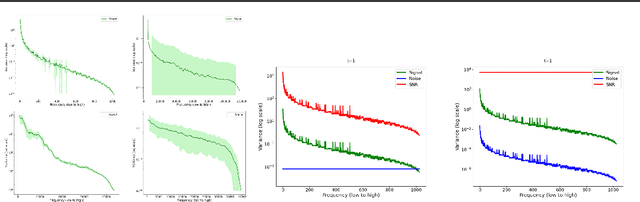

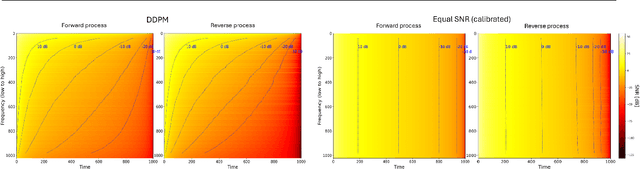
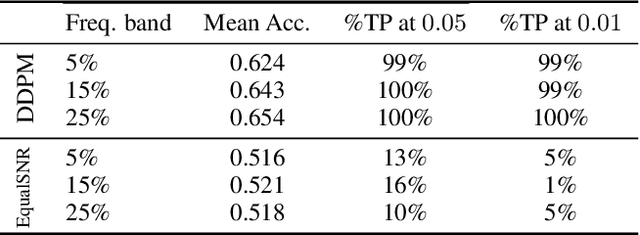
Diffusion models are state-of-the-art generative models on data modalities such as images, audio, proteins and materials. These modalities share the property of exponentially decaying variance and magnitude in the Fourier domain. Under the standard Denoising Diffusion Probabilistic Models (DDPM) forward process of additive white noise, this property results in high-frequency components being corrupted faster and earlier in terms of their Signal-to-Noise Ratio (SNR) than low-frequency ones. The reverse process then generates low-frequency information before high-frequency details. In this work, we study the inductive bias of the forward process of diffusion models in Fourier space. We theoretically analyse and empirically demonstrate that the faster noising of high-frequency components in DDPM results in violations of the normality assumption in the reverse process. Our experiments show that this leads to degraded generation quality of high-frequency components. We then study an alternate forward process in Fourier space which corrupts all frequencies at the same rate, removing the typical frequency hierarchy during generation, and demonstrate marked performance improvements on datasets where high frequencies are primary, while performing on par with DDPM on standard imaging benchmarks.
Implicit Language Models are RNNs: Balancing Parallelization and Expressivity
Feb 10, 2025State-space models (SSMs) and transformers dominate the language modeling landscape. However, they are constrained to a lower computational complexity than classical recurrent neural networks (RNNs), limiting their expressivity. In contrast, RNNs lack parallelization during training, raising fundamental questions about the trade off between parallelization and expressivity. We propose implicit SSMs, which iterate a transformation until convergence to a fixed point. Theoretically, we show that implicit SSMs implement the non-linear state-transitions of RNNs. Empirically, we find that only approximate fixed-point convergence suffices, enabling the design of a scalable training curriculum that largely retains parallelization, with full convergence required only for a small subset of tokens. Our approach demonstrates superior state-tracking capabilities on regular languages, surpassing transformers and SSMs. We further scale implicit SSMs to natural language reasoning tasks and pretraining of large-scale language models up to 1.3B parameters on 207B tokens - representing, to our knowledge, the largest implicit model trained to date. Notably, our implicit models outperform their explicit counterparts on standard benchmarks.
MAIRA-Seg: Enhancing Radiology Report Generation with Segmentation-Aware Multimodal Large Language Models
Nov 18, 2024



There is growing interest in applying AI to radiology report generation, particularly for chest X-rays (CXRs). This paper investigates whether incorporating pixel-level information through segmentation masks can improve fine-grained image interpretation of multimodal large language models (MLLMs) for radiology report generation. We introduce MAIRA-Seg, a segmentation-aware MLLM framework designed to utilize semantic segmentation masks alongside CXRs for generating radiology reports. We train expert segmentation models to obtain mask pseudolabels for radiology-specific structures in CXRs. Subsequently, building on the architectures of MAIRA, a CXR-specialised model for report generation, we integrate a trainable segmentation tokens extractor that leverages these mask pseudolabels, and employ mask-aware prompting to generate draft radiology reports. Our experiments on the publicly available MIMIC-CXR dataset show that MAIRA-Seg outperforms non-segmentation baselines. We also investigate set-of-marks prompting with MAIRA and find that MAIRA-Seg consistently demonstrates comparable or superior performance. The results confirm that using segmentation masks enhances the nuanced reasoning of MLLMs, potentially contributing to better clinical outcomes.
Identifying treatment response subgroups in observational time-to-event data
Aug 06, 2024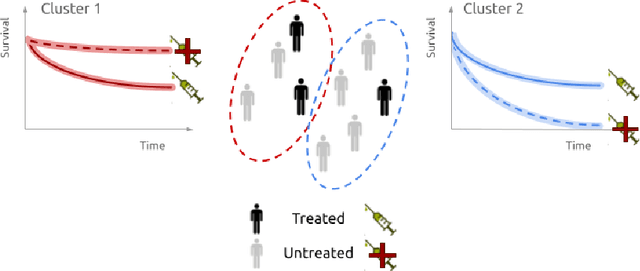
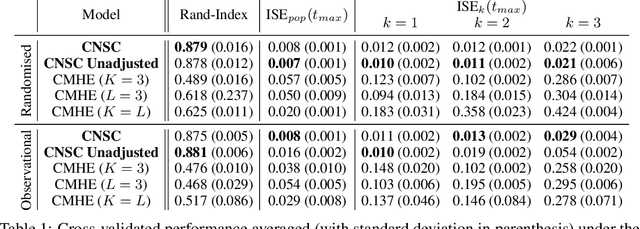
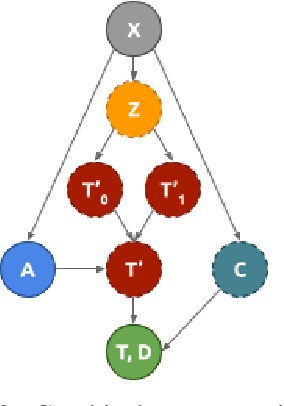
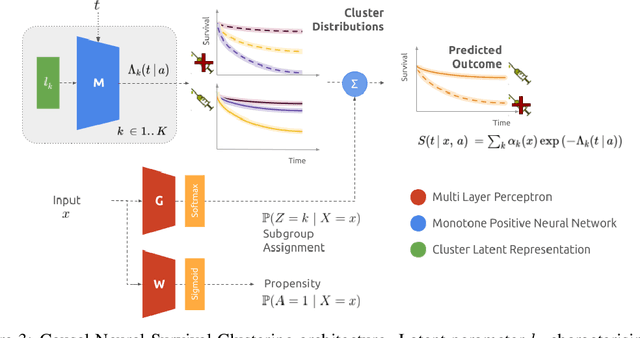
Identifying patient subgroups with different treatment responses is an important task to inform medical recommendations, guidelines, and the design of future clinical trials. Existing approaches for subgroup analysis primarily focus on Randomised Controlled Trials (RCTs), in which treatment assignment is randomised. Furthermore, the patient cohort of an RCT is often constrained by cost, and is not representative of the heterogeneity of patients likely to receive treatment in real-world clinical practice. Therefore, when applied to observational studies, such approaches suffer from significant statistical biases because of the non-randomisation of treatment. Our work introduces a novel, outcome-guided method for identifying treatment response subgroups in observational studies. Our approach assigns each patient to a subgroup associated with two time-to-event distributions: one under treatment and one under control regime. It hence positions itself in between individualised and average treatment effect estimation. The assumptions of our model result in a simple correction of the statistical bias from treatment non-randomisation through inverse propensity weighting. In experiments, our approach significantly outperforms the current state-of-the-art method for outcome-guided subgroup analysis in both randomised and observational treatment regimes.
A Critical Review of Causal Reasoning Benchmarks for Large Language Models
Jul 10, 2024


Numerous benchmarks aim to evaluate the capabilities of Large Language Models (LLMs) for causal inference and reasoning. However, many of them can likely be solved through the retrieval of domain knowledge, questioning whether they achieve their purpose. In this review, we present a comprehensive overview of LLM benchmarks for causality. We highlight how recent benchmarks move towards a more thorough definition of causal reasoning by incorporating interventional or counterfactual reasoning. We derive a set of criteria that a useful benchmark or set of benchmarks should aim to satisfy. We hope this work will pave the way towards a general framework for the assessment of causal understanding in LLMs and the design of novel benchmarks.
MAIRA-2: Grounded Radiology Report Generation
Jun 06, 2024



Radiology reporting is a complex task that requires detailed image understanding, integration of multiple inputs, including comparison with prior imaging, and precise language generation. This makes it ideal for the development and use of generative multimodal models. Here, we extend report generation to include the localisation of individual findings on the image - a task we call grounded report generation. Prior work indicates that grounding is important for clarifying image understanding and interpreting AI-generated text. Therefore, grounded reporting stands to improve the utility and transparency of automated report drafting. To enable evaluation of grounded reporting, we propose a novel evaluation framework - RadFact - leveraging the reasoning capabilities of large language models (LLMs). RadFact assesses the factuality of individual generated sentences, as well as correctness of generated spatial localisations when present. We introduce MAIRA-2, a large multimodal model combining a radiology-specific image encoder with a LLM, and trained for the new task of grounded report generation on chest X-rays. MAIRA-2 uses more comprehensive inputs than explored previously: the current frontal image, the current lateral image, the prior frontal image and prior report, as well as the Indication, Technique and Comparison sections of the current report. We demonstrate that these additions significantly improve report quality and reduce hallucinations, establishing a new state of the art on findings generation (without grounding) on MIMIC-CXR while demonstrating the feasibility of grounded reporting as a novel and richer task.
Is In-Context Learning in Large Language Models Bayesian? A Martingale Perspective
Jun 02, 2024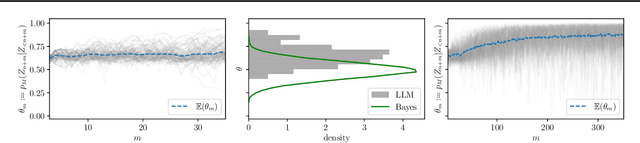
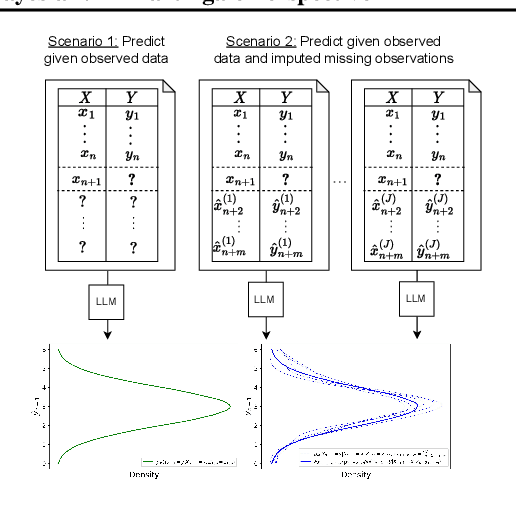
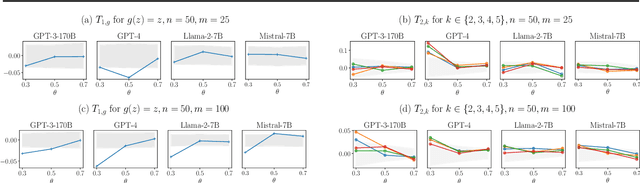
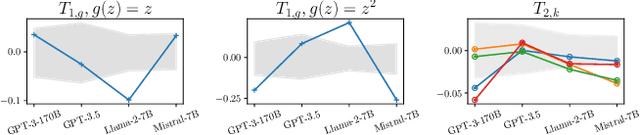
In-context learning (ICL) has emerged as a particularly remarkable characteristic of Large Language Models (LLM): given a pretrained LLM and an observed dataset, LLMs can make predictions for new data points from the same distribution without fine-tuning. Numerous works have postulated ICL as approximately Bayesian inference, rendering this a natural hypothesis. In this work, we analyse this hypothesis from a new angle through the martingale property, a fundamental requirement of a Bayesian learning system for exchangeable data. We show that the martingale property is a necessary condition for unambiguous predictions in such scenarios, and enables a principled, decomposed notion of uncertainty vital in trustworthy, safety-critical systems. We derive actionable checks with corresponding theory and test statistics which must hold if the martingale property is satisfied. We also examine if uncertainty in LLMs decreases as expected in Bayesian learning when more data is observed. In three experiments, we provide evidence for violations of the martingale property, and deviations from a Bayesian scaling behaviour of uncertainty, falsifying the hypothesis that ICL is Bayesian.
Approximations to the Fisher Information Metric of Deep Generative Models for Out-Of-Distribution Detection
Mar 03, 2024Likelihood-based deep generative models such as score-based diffusion models and variational autoencoders are state-of-the-art machine learning models approximating high-dimensional distributions of data such as images, text, or audio. One of many downstream tasks they can be naturally applied to is out-of-distribution (OOD) detection. However, seminal work by Nalisnick et al. which we reproduce showed that deep generative models consistently infer higher log-likelihoods for OOD data than data they were trained on, marking an open problem. In this work, we analyse using the gradient of a data point with respect to the parameters of the deep generative model for OOD detection, based on the simple intuition that OOD data should have larger gradient norms than training data. We formalise measuring the size of the gradient as approximating the Fisher information metric. We show that the Fisher information matrix (FIM) has large absolute diagonal values, motivating the use of chi-square distributed, layer-wise gradient norms as features. We combine these features to make a simple, model-agnostic and hyperparameter-free method for OOD detection which estimates the joint density of the layer-wise gradient norms for a given data point. We find that these layer-wise gradient norms are weakly correlated, rendering their combined usage informative, and prove that the layer-wise gradient norms satisfy the principle of (data representation) invariance. Our empirical results indicate that this method outperforms the Typicality test for most deep generative models and image dataset pairings.
A Unified Framework for U-Net Design and Analysis
May 31, 2023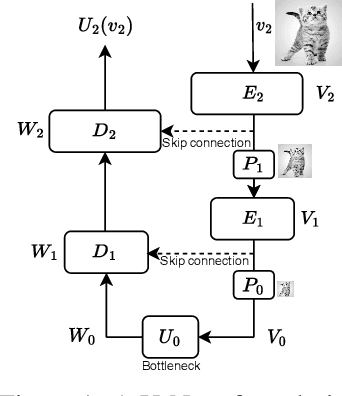
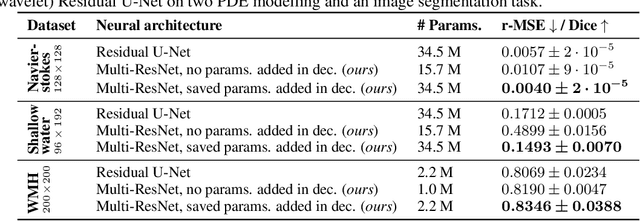
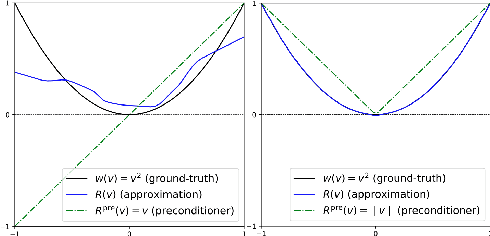

U-Nets are a go-to, state-of-the-art neural architecture across numerous tasks for continuous signals on a square such as images and Partial Differential Equations (PDE), however their design and architecture is understudied. In this paper, we provide a framework for designing and analysing general U-Net architectures. We present theoretical results which characterise the role of the encoder and decoder in a U-Net, their high-resolution scaling limits and their conjugacy to ResNets via preconditioning. We propose Multi-ResNets, U-Nets with a simplified, wavelet-based encoder without learnable parameters. Further, we show how to design novel U-Net architectures which encode function constraints, natural bases, or the geometry of the data. In diffusion models, our framework enables us to identify that high-frequency information is dominated by noise exponentially faster, and show how U-Nets with average pooling exploit this. In our experiments, we demonstrate how Multi-ResNets achieve competitive and often superior performance compared to classical U-Nets in image segmentation, PDE surrogate modelling, and generative modelling with diffusion models. Our U-Net framework paves the way to study the theoretical properties of U-Nets and design natural, scalable neural architectures for a multitude of problems beyond the square.