 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForward-Learned Discrete Diffusion: Learning how to noise to denoise faster
May 18, 2026Discrete diffusion models are a powerful class of generative models with strong performance across many domains. For efficiency, however, discrete diffusion typically parameterizes the generative (reverse) process with factorized distributions, which makes it difficult for the model to learn the target process in a small number of steps and necessitates a long, computationally expensive sampling procedure. To reduce the gap between the target and model distributions and enable few-step generation, we propose Forward-Learned Discrete Diffusion (FLDD), which introduces discrete diffusion with a learnable forward (noising) process. Rather than fixing a Markovian forward chain, we adopt a non-Markovian formulation with learnable marginal and posterior distributions. This allows the generative process to remain factorized while matching the target defined by the noising process. We train all parameters end-to-end under the standard variational objective. Experiments on various benchmarks show that, for a given number of sampling steps, our approach produces a higher quality samples than conventional discrete diffusion models using the same reverse parameterization.
Do Transformers Use their Depth Adaptively? Evidence from a Relational Reasoning Task
Apr 14, 2026We investigate whether transformers use their depth adaptively across tasks of increasing difficulty. Using a controlled multi-hop relational reasoning task based on family stories, where difficulty is determined by the number of relationship hops that must be composed, we monitor (i) how predictions evolve across layers via early readouts (the logit lens) and (ii) how task-relevant information is integrated across tokens via causal patching. For pretrained models, we find some limited evidence for adaptive depth use: some larger models need fewer layers to arrive at plausible answers for easier tasks, and models generally use more layers to integrate information across tokens as chain length increases. For models finetuned on the task, we find clearer and more consistent evidence of adaptive depth use, with the effect being stronger for less constrained finetuning regimes that do not preserve general language modeling abilities.
Robust Learning of a Group DRO Neuron
Jan 26, 2026We study the problem of learning a single neuron under standard squared loss in the presence of arbitrary label noise and group-level distributional shifts, for a broad family of covariate distributions. Our goal is to identify a ''best-fit'' neuron parameterized by $\mathbf{w}_*$ that performs well under the most challenging reweighting of the groups. Specifically, we address a Group Distributionally Robust Optimization problem: given sample access to $K$ distinct distributions $\mathcal p_{[1]},\dots,\mathcal p_{[K]}$, we seek to approximate $\mathbf{w}_*$ that minimizes the worst-case objective over convex combinations of group distributions $\boldsymbolλ \in Δ_K$, where the objective is $\sum_{i \in [K]}λ_{[i]}\,\mathbb E_{(\mathbf x,y)\sim\mathcal p_{[i]}}(σ(\mathbf w\cdot\mathbf x)-y)^2 - νd_f(\boldsymbolλ,\frac{1}{K}\mathbf1)$ and $d_f$ is an $f$-divergence that imposes (optional) penalty on deviations from uniform group weights, scaled by a parameter $ν\geq 0$. We develop a computationally efficient primal-dual algorithm that outputs a vector $\widehat{\mathbf w}$ that is constant-factor competitive with $\mathbf{w}_*$ under the worst-case group weighting. Our analytical framework directly confronts the inherent nonconvexity of the loss function, providing robust learning guarantees in the face of arbitrary label corruptions and group-specific distributional shifts. The implementation of the dual extrapolation update motivated by our algorithmic framework shows promise on LLM pre-training benchmarks.
A Fourier Space Perspective on Diffusion Models
May 16, 2025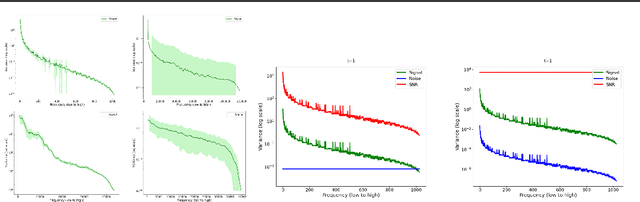

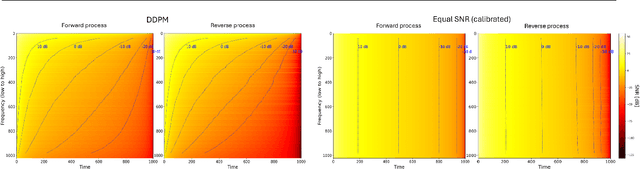
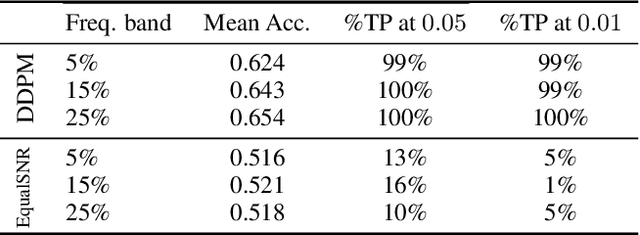
Diffusion models are state-of-the-art generative models on data modalities such as images, audio, proteins and materials. These modalities share the property of exponentially decaying variance and magnitude in the Fourier domain. Under the standard Denoising Diffusion Probabilistic Models (DDPM) forward process of additive white noise, this property results in high-frequency components being corrupted faster and earlier in terms of their Signal-to-Noise Ratio (SNR) than low-frequency ones. The reverse process then generates low-frequency information before high-frequency details. In this work, we study the inductive bias of the forward process of diffusion models in Fourier space. We theoretically analyse and empirically demonstrate that the faster noising of high-frequency components in DDPM results in violations of the normality assumption in the reverse process. Our experiments show that this leads to degraded generation quality of high-frequency components. We then study an alternate forward process in Fourier space which corrupts all frequencies at the same rate, removing the typical frequency hierarchy during generation, and demonstrate marked performance improvements on datasets where high frequencies are primary, while performing on par with DDPM on standard imaging benchmarks.
On Learning Parallel Pancakes with Mostly Uniform Weights
Apr 21, 2025We study the complexity of learning $k$-mixtures of Gaussians ($k$-GMMs) on $\mathbb{R}^d$. This task is known to have complexity $d^{\Omega(k)}$ in full generality. To circumvent this exponential lower bound on the number of components, research has focused on learning families of GMMs satisfying additional structural properties. A natural assumption posits that the component weights are not exponentially small and that the components have the same unknown covariance. Recent work gave a $d^{O(\log(1/w_{\min}))}$-time algorithm for this class of GMMs, where $w_{\min}$ is the minimum weight. Our first main result is a Statistical Query (SQ) lower bound showing that this quasi-polynomial upper bound is essentially best possible, even for the special case of uniform weights. Specifically, we show that it is SQ-hard to distinguish between such a mixture and the standard Gaussian. We further explore how the distribution of weights affects the complexity of this task. Our second main result is a quasi-polynomial upper bound for the aforementioned testing task when most of the weights are uniform while a small fraction of the weights are potentially arbitrary.
Batch List-Decodable Linear Regression via Higher Moments
Mar 12, 2025We study the task of list-decodable linear regression using batches. A batch is called clean if it consists of i.i.d. samples from an unknown linear regression distribution. For a parameter $\alpha \in (0, 1/2)$, an unknown $\alpha$-fraction of the batches are clean and no assumptions are made on the remaining ones. The goal is to output a small list of vectors at least one of which is close to the true regressor vector in $\ell_2$-norm. [DJKS23] gave an efficient algorithm, under natural distributional assumptions, with the following guarantee. Assuming that the batch size $n$ satisfies $n \geq \tilde{\Omega}(\alpha^{-1})$ and the number of batches is $m = \mathrm{poly}(d, n, 1/\alpha)$, their algorithm runs in polynomial time and outputs a list of $O(1/\alpha^2)$ vectors at least one of which is $\tilde{O}(\alpha^{-1/2}/\sqrt{n})$ close to the target regressor. Here we design a new polynomial time algorithm with significantly stronger guarantees under the assumption that the low-degree moments of the covariates distribution are Sum-of-Squares (SoS) certifiably bounded. Specifically, for any constant $\delta>0$, as long as the batch size is $n \geq \Omega_{\delta}(\alpha^{-\delta})$ and the degree-$\Theta(1/\delta)$ moments of the covariates are SoS certifiably bounded, our algorithm uses $m = \mathrm{poly}((dn)^{1/\delta}, 1/\alpha)$ batches, runs in polynomial-time, and outputs an $O(1/\alpha)$-sized list of vectors one of which is $O(\alpha^{-\delta/2}/\sqrt{n})$ close to the target. That is, our algorithm achieves substantially smaller minimum batch size and final error, while achieving the optimal list size. Our approach uses higher-order moment information by carefully combining the SoS paradigm interleaved with an iterative method and a novel list pruning procedure. In the process, we give an SoS proof of the Marcinkiewicz-Zygmund inequality that may be of broader applicability.
Learning a Single Neuron Robustly to Distributional Shifts and Adversarial Label Noise
Nov 11, 2024We study the problem of learning a single neuron with respect to the $L_2^2$-loss in the presence of adversarial distribution shifts, where the labels can be arbitrary, and the goal is to find a ``best-fit'' function. More precisely, given training samples from a reference distribution $\mathcal{p}_0$, the goal is to approximate the vector $\mathbf{w}^*$ which minimizes the squared loss with respect to the worst-case distribution that is close in $\chi^2$-divergence to $\mathcal{p}_{0}$. We design a computationally efficient algorithm that recovers a vector $ \hat{\mathbf{w}}$ satisfying $\mathbb{E}_{\mathcal{p}^*} (\sigma(\hat{\mathbf{w}} \cdot \mathbf{x}) - y)^2 \leq C \, \mathbb{E}_{\mathcal{p}^*} (\sigma(\mathbf{w}^* \cdot \mathbf{x}) - y)^2 + \epsilon$, where $C>1$ is a dimension-independent constant and $(\mathbf{w}^*, \mathcal{p}^*)$ is the witness attaining the min-max risk $\min_{\mathbf{w}~:~\|\mathbf{w}\| \leq W} \max_{\mathcal{p}} \mathbb{E}_{(\mathbf{x}, y) \sim \mathcal{p}} (\sigma(\mathbf{w} \cdot \mathbf{x}) - y)^2 - \nu \chi^2(\mathcal{p}, \mathcal{p}_0)$. Our algorithm follows a primal-dual framework and is designed by directly bounding the risk with respect to the original, nonconvex $L_2^2$ loss. From an optimization standpoint, our work opens new avenues for the design of primal-dual algorithms under structured nonconvexity.
Sum-of-squares lower bounds for Non-Gaussian Component Analysis
Oct 28, 2024
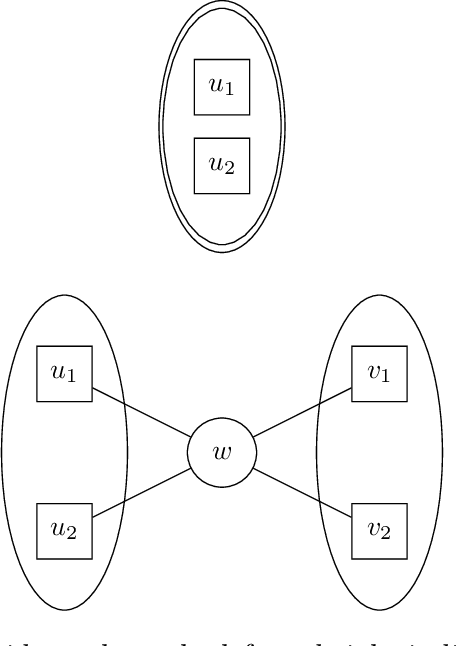

Non-Gaussian Component Analysis (NGCA) is the statistical task of finding a non-Gaussian direction in a high-dimensional dataset. Specifically, given i.i.d.\ samples from a distribution $P^A_{v}$ on $\mathbb{R}^n$ that behaves like a known distribution $A$ in a hidden direction $v$ and like a standard Gaussian in the orthogonal complement, the goal is to approximate the hidden direction. The standard formulation posits that the first $k-1$ moments of $A$ match those of the standard Gaussian and the $k$-th moment differs. Under mild assumptions, this problem has sample complexity $O(n)$. On the other hand, all known efficient algorithms require $\Omega(n^{k/2})$ samples. Prior work developed sharp Statistical Query and low-degree testing lower bounds suggesting an information-computation tradeoff for this problem. Here we study the complexity of NGCA in the Sum-of-Squares (SoS) framework. Our main contribution is the first super-constant degree SoS lower bound for NGCA. Specifically, we show that if the non-Gaussian distribution $A$ matches the first $(k-1)$ moments of $\mathcal{N}(0, 1)$ and satisfies other mild conditions, then with fewer than $n^{(1 - \varepsilon)k/2}$ many samples from the normal distribution, with high probability, degree $(\log n)^{{1\over 2}-o_n(1)}$ SoS fails to refute the existence of such a direction $v$. Our result significantly strengthens prior work by establishing a super-polynomial information-computation tradeoff against a broader family of algorithms. As corollaries, we obtain SoS lower bounds for several problems in robust statistics and the learning of mixture models. Our SoS lower bound proof introduces a novel technique, that we believe may be of broader interest, and a number of refinements over existing methods.
Robust Sparse Estimation for Gaussians with Optimal Error under Huber Contamination
Mar 15, 2024We study Gaussian sparse estimation tasks in Huber's contamination model with a focus on mean estimation, PCA, and linear regression. For each of these tasks, we give the first sample and computationally efficient robust estimators with optimal error guarantees, within constant factors. All prior efficient algorithms for these tasks incur quantitatively suboptimal error. Concretely, for Gaussian robust $k$-sparse mean estimation on $\mathbb{R}^d$ with corruption rate $\epsilon>0$, our algorithm has sample complexity $(k^2/\epsilon^2)\mathrm{polylog}(d/\epsilon)$, runs in sample polynomial time, and approximates the target mean within $\ell_2$-error $O(\epsilon)$. Previous efficient algorithms inherently incur error $\Omega(\epsilon \sqrt{\log(1/\epsilon)})$. At the technical level, we develop a novel multidimensional filtering method in the sparse regime that may find other applications.
Multi-Model 3D Registration: Finding Multiple Moving Objects in Cluttered Point Clouds
Feb 16, 2024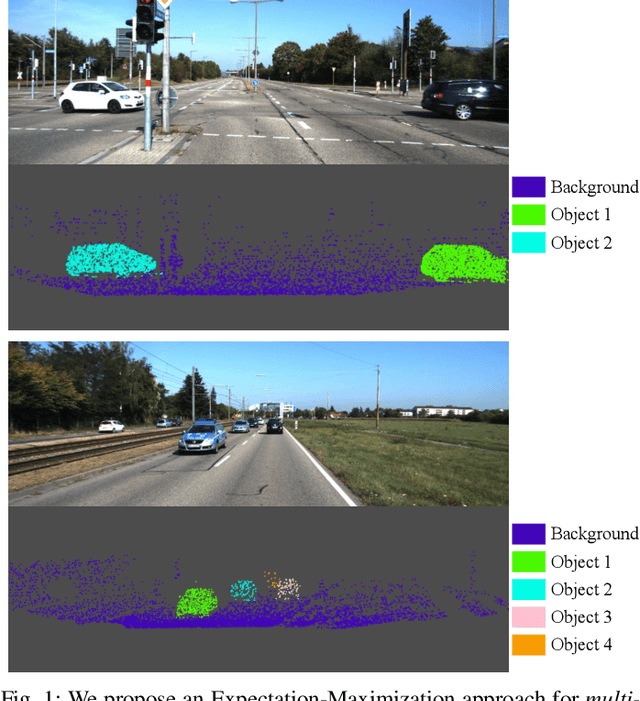
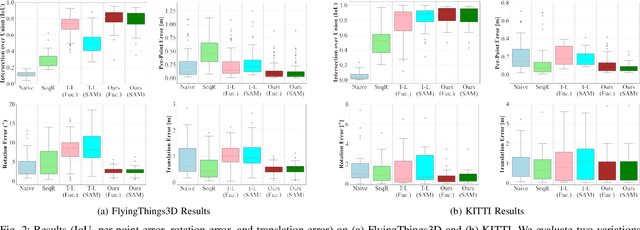
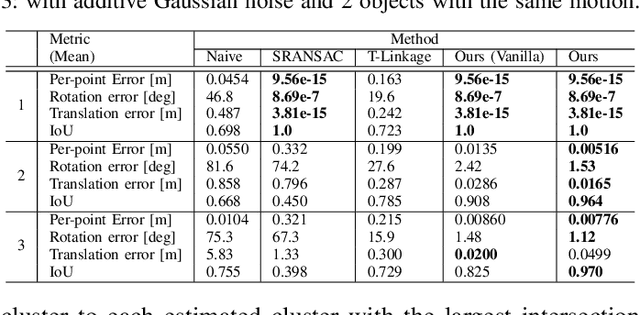
We investigate a variation of the 3D registration problem, named multi-model 3D registration. In the multi-model registration problem, we are given two point clouds picturing a set of objects at different poses (and possibly including points belonging to the background) and we want to simultaneously reconstruct how all objects moved between the two point clouds. This setup generalizes standard 3D registration where one wants to reconstruct a single pose, e.g., the motion of the sensor picturing a static scene. Moreover, it provides a mathematically grounded formulation for relevant robotics applications, e.g., where a depth sensor onboard a robot perceives a dynamic scene and has the goal of estimating its own motion (from the static portion of the scene) while simultaneously recovering the motion of all dynamic objects. We assume a correspondence-based setup where we have putative matches between the two point clouds and consider the practical case where these correspondences are plagued with outliers. We then propose a simple approach based on Expectation-Maximization (EM) and establish theoretical conditions under which the EM approach converges to the ground truth. We evaluate the approach in simulated and real datasets ranging from table-top scenes to self-driving scenarios and demonstrate its effectiveness when combined with state-of-the-art scene flow methods to establish dense correspondences.