 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Intersections of Two Margin Halfspaces under Factorizable Distributions
Nov 16, 2025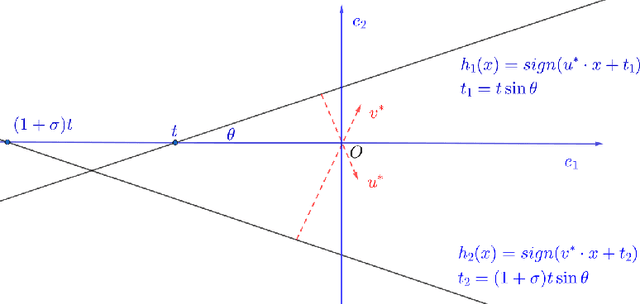
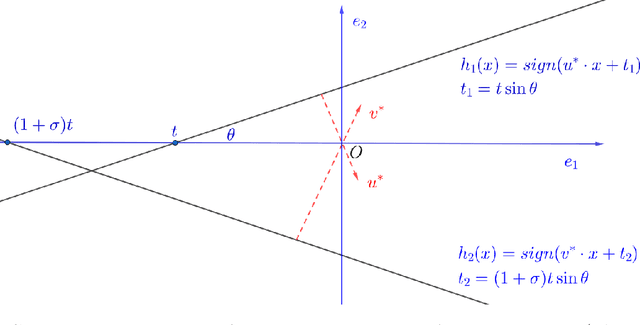
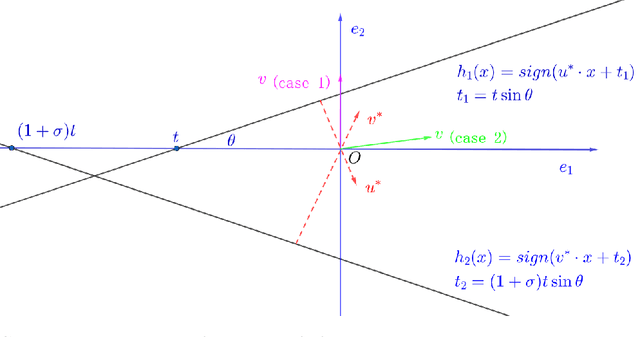

Learning intersections of halfspaces is a central problem in Computational Learning Theory. Even for just two halfspaces, it remains a major open question whether learning is possible in polynomial time with respect to the margin $γ$ of the data points and their dimensionality $d$. The best-known algorithms run in quasi-polynomial time $d^{O(\log(1/γ))}$, and it has been shown that this complexity is unavoidable for any algorithm relying solely on correlational statistical queries (CSQ). In this work, we introduce a novel algorithm that provably circumvents the CSQ hardness barrier. Our approach applies to a broad class of distributions satisfying a natural, previously studied, factorizability assumption. Factorizable distributions lie between distribution-specific and distribution-free settings, and significantly extend previously known tractable cases. Under these distributions, we show that CSQ-based methods still require quasipolynomial time even for weakly learning, whereas our algorithm achieves $poly(d,1/γ)$ time by leveraging more general statistical queries (SQ), establishing a strong separation between CSQ and SQ for this simple realizable PAC learning problem. Our result is grounded in a rigorous analysis utilizing a novel duality framework that characterizes the moment tensor structure induced by the marginal distributions. Building on these structural insights, we propose new, efficient learning algorithms. These algorithms combine a refined variant of Jennrich's Algorithm with PCA over random projections of the moment tensor, along with a gradient-descent-based non-convex optimization framework.
Teaching Transformers to Solve Combinatorial Problems through Efficient Trial & Error
Sep 26, 2025Despite their proficiency in various language tasks, Large Language Models (LLMs) struggle with combinatorial problems like Satisfiability, Traveling Salesman Problem, or even basic arithmetic. We address this gap through a novel approach for solving problems in the class NP. We focus on the paradigmatic task of Sudoku and achieve state-of-the-art accuracy (99\%) compared to prior neuro-symbolic approaches. Unlike prior work that used custom architectures, our method employs a vanilla decoder-only Transformer (GPT-2) without external tools or function calling. Our method integrates imitation learning of simple Sudoku rules with an explicit Depth-First Search (DFS) exploration strategy involving informed guessing and backtracking. Moving beyond imitation learning, we seek to minimize the number of guesses until reaching a solution. We provide a rigorous analysis of this setup formalizing its connection to a contextual variant of Min-Sum Set Cover, a well-studied problem in algorithms and stochastic optimization.
Statistical Query Hardness of Multiclass Linear Classification with Random Classification Noise
Feb 17, 2025

We study the task of Multiclass Linear Classification (MLC) in the distribution-free PAC model with Random Classification Noise (RCN). Specifically, the learner is given a set of labeled examples $(x, y)$, where $x$ is drawn from an unknown distribution on $R^d$ and the labels are generated by a multiclass linear classifier corrupted with RCN. That is, the label $y$ is flipped from $i$ to $j$ with probability $H_{ij}$ according to a known noise matrix $H$ with non-negative separation $\sigma: = \min_{i \neq j} H_{ii}-H_{ij}$. The goal is to compute a hypothesis with small 0-1 error. For the special case of two labels, prior work has given polynomial-time algorithms achieving the optimal error. Surprisingly, little is known about the complexity of this task even for three labels. As our main contribution, we show that the complexity of MLC with RCN becomes drastically different in the presence of three or more labels. Specifically, we prove super-polynomial Statistical Query (SQ) lower bounds for this problem. In more detail, even for three labels and constant separation, we give a super-polynomial lower bound on the complexity of any SQ algorithm achieving optimal error. For a larger number of labels and smaller separation, we show a super-polynomial SQ lower bound even for the weaker goal of achieving any constant factor approximation to the optimal loss or even beating the trivial hypothesis.
Optimization Can Learn Johnson Lindenstrauss Embeddings
Dec 10, 2024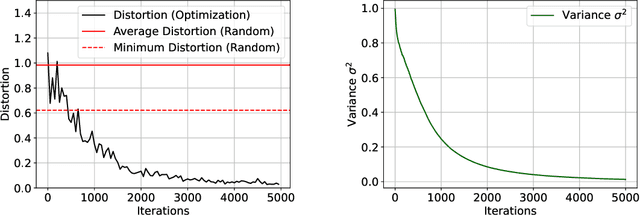
Embeddings play a pivotal role across various disciplines, offering compact representations of complex data structures. Randomized methods like Johnson-Lindenstrauss (JL) provide state-of-the-art and essentially unimprovable theoretical guarantees for achieving such representations. These guarantees are worst-case and in particular, neither the analysis, nor the algorithm, takes into account any potential structural information of the data. The natural question is: must we randomize? Could we instead use an optimization-based approach, working directly with the data? A first answer is no: as we show, the distance-preserving objective of JL has a non-convex landscape over the space of projection matrices, with many bad stationary points. But this is not the final answer. We present a novel method motivated by diffusion models, that circumvents this fundamental challenge: rather than performing optimization directly over the space of projection matrices, we use optimization over the larger space of random solution samplers, gradually reducing the variance of the sampler. We show that by moving through this larger space, our objective converges to a deterministic (zero variance) solution, avoiding bad stationary points. This method can also be seen as an optimization-based derandomization approach and is an idea and method that we believe can be applied to many other problems.
Online Learning of Halfspaces with Massart Noise
May 21, 2024We study the task of online learning in the presence of Massart noise. Instead of assuming that the online adversary chooses an arbitrary sequence of labels, we assume that the context $\mathbf{x}$ is selected adversarially but the label $y$ presented to the learner disagrees with the ground-truth label of $\mathbf{x}$ with unknown probability at most $\eta$. We study the fundamental class of $\gamma$-margin linear classifiers and present a computationally efficient algorithm that achieves mistake bound $\eta T + o(T)$. Our mistake bound is qualitatively tight for efficient algorithms: it is known that even in the offline setting achieving classification error better than $\eta$ requires super-polynomial time in the SQ model. We extend our online learning model to a $k$-arm contextual bandit setting where the rewards -- instead of satisfying commonly used realizability assumptions -- are consistent (in expectation) with some linear ranking function with weight vector $\mathbf{w}^\ast$. Given a list of contexts $\mathbf{x}_1,\ldots \mathbf{x}_k$, if $\mathbf{w}^*\cdot \mathbf{x}_i > \mathbf{w}^* \cdot \mathbf{x}_j$, the expected reward of action $i$ must be larger than that of $j$ by at least $\Delta$. We use our Massart online learner to design an efficient bandit algorithm that obtains expected reward at least $(1-1/k)~ \Delta T - o(T)$ bigger than choosing a random action at every round.
Active Learning with Simple Questions
May 13, 2024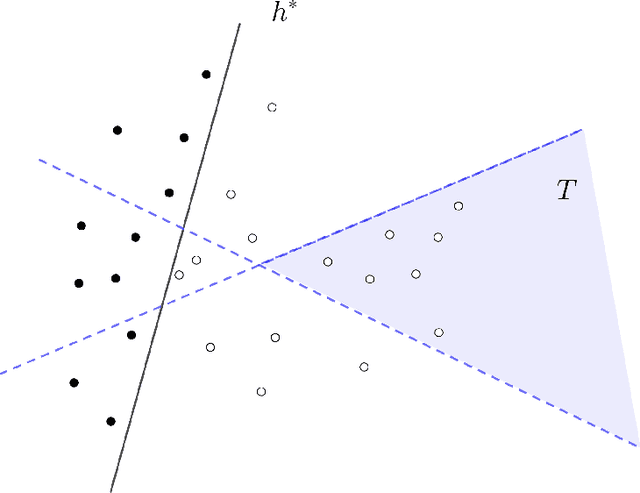

We consider an active learning setting where a learner is presented with a pool S of n unlabeled examples belonging to a domain X and asks queries to find the underlying labeling that agrees with a target concept h^* \in H. In contrast to traditional active learning that queries a single example for its label, we study more general region queries that allow the learner to pick a subset of the domain T \subset X and a target label y and ask a labeler whether h^*(x) = y for every example in the set T \cap S. Such more powerful queries allow us to bypass the limitations of traditional active learning and use significantly fewer rounds of interactions to learn but can potentially lead to a significantly more complex query language. Our main contribution is quantifying the trade-off between the number of queries and the complexity of the query language used by the learner. We measure the complexity of the region queries via the VC dimension of the family of regions. We show that given any hypothesis class H with VC dimension d, one can design a region query family Q with VC dimension O(d) such that for every set of n examples S \subset X and every h^* \in H, a learner can submit O(d log n) queries from Q to a labeler and perfectly label S. We show a matching lower bound by designing a hypothesis class H with VC dimension d and a dataset S \subset X of size n such that any learning algorithm using any query class with VC dimension O(d) must make poly(n) queries to label S perfectly. Finally, we focus on well-studied hypothesis classes including unions of intervals, high-dimensional boxes, and d-dimensional halfspaces, and obtain stronger results. In particular, we design learning algorithms that (i) are computationally efficient and (ii) work even when the queries are not answered based on the learner's pool of examples S but on some unknown superset L of S
Agnostically Learning Multi-index Models with Queries
Dec 27, 2023


We study the power of query access for the task of agnostic learning under the Gaussian distribution. In the agnostic model, no assumptions are made on the labels and the goal is to compute a hypothesis that is competitive with the {\em best-fit} function in a known class, i.e., it achieves error $\mathrm{opt}+\epsilon$, where $\mathrm{opt}$ is the error of the best function in the class. We focus on a general family of Multi-Index Models (MIMs), which are $d$-variate functions that depend only on few relevant directions, i.e., have the form $g(\mathbf{W} \mathbf{x})$ for an unknown link function $g$ and a $k \times d$ matrix $\mathbf{W}$. Multi-index models cover a wide range of commonly studied function classes, including constant-depth neural networks with ReLU activations, and intersections of halfspaces. Our main result shows that query access gives significant runtime improvements over random examples for agnostically learning MIMs. Under standard regularity assumptions for the link function (namely, bounded variation or surface area), we give an agnostic query learner for MIMs with complexity $O(k)^{\mathrm{poly}(1/\epsilon)} \; \mathrm{poly}(d) $. In contrast, algorithms that rely only on random examples inherently require $d^{\mathrm{poly}(1/\epsilon)}$ samples and runtime, even for the basic problem of agnostically learning a single ReLU or a halfspace. Our algorithmic result establishes a strong computational separation between the agnostic PAC and the agnostic PAC+Query models under the Gaussian distribution. Prior to our work, no such separation was known -- even for the special case of agnostically learning a single halfspace, for which it was an open problem first posed by Feldman. Our results are enabled by a general dimension-reduction technique that leverages query access to estimate gradients of (a smoothed version of) the underlying label function.
Optimizing Solution-Samplers for Combinatorial Problems: The Landscape of Policy-Gradient Methods
Oct 08, 2023Deep Neural Networks and Reinforcement Learning methods have empirically shown great promise in tackling challenging combinatorial problems. In those methods a deep neural network is used as a solution generator which is then trained by gradient-based methods (e.g., policy gradient) to successively obtain better solution distributions. In this work we introduce a novel theoretical framework for analyzing the effectiveness of such methods. We ask whether there exist generative models that (i) are expressive enough to generate approximately optimal solutions; (ii) have a tractable, i.e, polynomial in the size of the input, number of parameters; (iii) their optimization landscape is benign in the sense that it does not contain sub-optimal stationary points. Our main contribution is a positive answer to this question. Our result holds for a broad class of combinatorial problems including Max- and Min-Cut, Max-$k$-CSP, Maximum-Weight-Bipartite-Matching, and the Traveling Salesman Problem. As a byproduct of our analysis we introduce a novel regularization process over vanilla gradient descent and provide theoretical and experimental evidence that it helps address vanishing-gradient issues and escape bad stationary points.
Distribution-Independent Regression for Generalized Linear Models with Oblivious Corruptions
Sep 27, 2023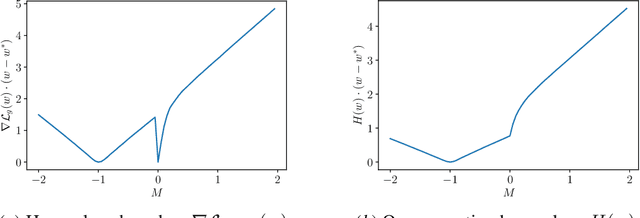
We demonstrate the first algorithms for the problem of regression for generalized linear models (GLMs) in the presence of additive oblivious noise. We assume we have sample access to examples $(x, y)$ where $y$ is a noisy measurement of $g(w^* \cdot x)$. In particular, \new{the noisy labels are of the form} $y = g(w^* \cdot x) + \xi + \epsilon$, where $\xi$ is the oblivious noise drawn independently of $x$ \new{and satisfies} $\Pr[\xi = 0] \geq o(1)$, and $\epsilon \sim \mathcal N(0, \sigma^2)$. Our goal is to accurately recover a \new{parameter vector $w$ such that the} function $g(w \cdot x)$ \new{has} arbitrarily small error when compared to the true values $g(w^* \cdot x)$, rather than the noisy measurements $y$. We present an algorithm that tackles \new{this} problem in its most general distribution-independent setting, where the solution may not \new{even} be identifiable. \new{Our} algorithm returns \new{an accurate estimate of} the solution if it is identifiable, and otherwise returns a small list of candidates, one of which is close to the true solution. Furthermore, we \new{provide} a necessary and sufficient condition for identifiability, which holds in broad settings. \new{Specifically,} the problem is identifiable when the quantile at which $\xi + \epsilon = 0$ is known, or when the family of hypotheses does not contain candidates that are nearly equal to a translated $g(w^* \cdot x) + A$ for some real number $A$, while also having large error when compared to $g(w^* \cdot x)$. This is the first \new{algorithmic} result for GLM regression \new{with oblivious noise} which can handle more than half the samples being arbitrarily corrupted. Prior work focused largely on the setting of linear regression, and gave algorithms under restrictive assumptions.
Self-Directed Linear Classification
Aug 06, 2023
In online classification, a learner is presented with a sequence of examples and aims to predict their labels in an online fashion so as to minimize the total number of mistakes. In the self-directed variant, the learner knows in advance the pool of examples and can adaptively choose the order in which predictions are made. Here we study the power of choosing the prediction order and establish the first strong separation between worst-order and random-order learning for the fundamental task of linear classification. Prior to our work, such a separation was known only for very restricted concept classes, e.g., one-dimensional thresholds or axis-aligned rectangles. We present two main results. If $X$ is a dataset of $n$ points drawn uniformly at random from the $d$-dimensional unit sphere, we design an efficient self-directed learner that makes $O(d \log \log(n))$ mistakes and classifies the entire dataset. If $X$ is an arbitrary $d$-dimensional dataset of size $n$, we design an efficient self-directed learner that predicts the labels of $99\%$ of the points in $X$ with mistake bound independent of $n$. In contrast, under a worst- or random-ordering, the number of mistakes must be at least $\Omega(d \log n)$, even when the points are drawn uniformly from the unit sphere and the learner only needs to predict the labels for $1\%$ of them.