 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Intersections of Two Margin Halfspaces under Factorizable Distributions
Nov 16, 2025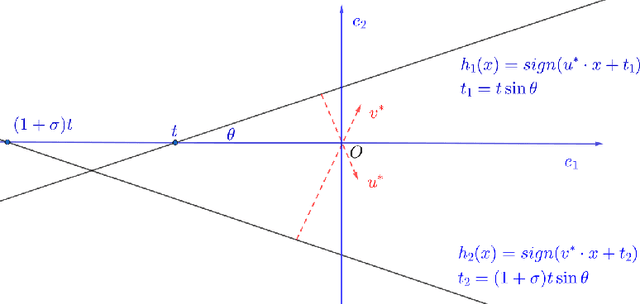

Learning intersections of halfspaces is a central problem in Computational Learning Theory. Even for just two halfspaces, it remains a major open question whether learning is possible in polynomial time with respect to the margin $γ$ of the data points and their dimensionality $d$. The best-known algorithms run in quasi-polynomial time $d^{O(\log(1/γ))}$, and it has been shown that this complexity is unavoidable for any algorithm relying solely on correlational statistical queries (CSQ). In this work, we introduce a novel algorithm that provably circumvents the CSQ hardness barrier. Our approach applies to a broad class of distributions satisfying a natural, previously studied, factorizability assumption. Factorizable distributions lie between distribution-specific and distribution-free settings, and significantly extend previously known tractable cases. Under these distributions, we show that CSQ-based methods still require quasipolynomial time even for weakly learning, whereas our algorithm achieves $poly(d,1/γ)$ time by leveraging more general statistical queries (SQ), establishing a strong separation between CSQ and SQ for this simple realizable PAC learning problem. Our result is grounded in a rigorous analysis utilizing a novel duality framework that characterizes the moment tensor structure induced by the marginal distributions. Building on these structural insights, we propose new, efficient learning algorithms. These algorithms combine a refined variant of Jennrich's Algorithm with PCA over random projections of the moment tensor, along with a gradient-descent-based non-convex optimization framework.
Algorithms and SQ Lower Bounds for Robustly Learning Real-valued Multi-index Models
May 27, 2025We study the complexity of learning real-valued Multi-Index Models (MIMs) under the Gaussian distribution. A $K$-MIM is a function $f:\mathbb{R}^d\to \mathbb{R}$ that depends only on the projection of its input onto a $K$-dimensional subspace. We give a general algorithm for PAC learning a broad class of MIMs with respect to the square loss, even in the presence of adversarial label noise. Moreover, we establish a nearly matching Statistical Query (SQ) lower bound, providing evidence that the complexity of our algorithm is qualitatively optimal as a function of the dimension. Specifically, we consider the class of bounded variation MIMs with the property that degree at most $m$ distinguishing moments exist with respect to projections onto any subspace. In the presence of adversarial label noise, the complexity of our learning algorithm is $d^{O(m)}2^{\mathrm{poly}(K/\epsilon)}$. For the realizable and independent noise settings, our algorithm incurs complexity $d^{O(m)}2^{\mathrm{poly}(K)}(1/\epsilon)^{O(K)}$. To complement our upper bound, we show that if for some subspace degree-$m$ distinguishing moments do not exist, then any SQ learner for the corresponding class of MIMs requires complexity $d^{\Omega(m)}$. As an application, we give the first efficient learner for the class of positive-homogeneous $L$-Lipschitz $K$-MIMs. The resulting algorithm has complexity $\mathrm{poly}(d) 2^{\mathrm{poly}(KL/\epsilon)}$. This gives a new PAC learning algorithm for Lipschitz homogeneous ReLU networks with complexity independent of the network size, removing the exponential dependence incurred in prior work.
Faster Algorithms for Agnostically Learning Disjunctions and their Implications
Apr 21, 2025We study the algorithmic task of learning Boolean disjunctions in the distribution-free agnostic PAC model. The best known agnostic learner for the class of disjunctions over $\{0, 1\}^n$ is the $L_1$-polynomial regression algorithm, achieving complexity $2^{\tilde{O}(n^{1/2})}$. This complexity bound is known to be nearly best possible within the class of Correlational Statistical Query (CSQ) algorithms. In this work, we develop an agnostic learner for this concept class with complexity $2^{\tilde{O}(n^{1/3})}$. Our algorithm can be implemented in the Statistical Query (SQ) model, providing the first separation between the SQ and CSQ models in distribution-free agnostic learning.
Statistical Query Hardness of Multiclass Linear Classification with Random Classification Noise
Feb 17, 2025

We study the task of Multiclass Linear Classification (MLC) in the distribution-free PAC model with Random Classification Noise (RCN). Specifically, the learner is given a set of labeled examples $(x, y)$, where $x$ is drawn from an unknown distribution on $R^d$ and the labels are generated by a multiclass linear classifier corrupted with RCN. That is, the label $y$ is flipped from $i$ to $j$ with probability $H_{ij}$ according to a known noise matrix $H$ with non-negative separation $\sigma: = \min_{i \neq j} H_{ii}-H_{ij}$. The goal is to compute a hypothesis with small 0-1 error. For the special case of two labels, prior work has given polynomial-time algorithms achieving the optimal error. Surprisingly, little is known about the complexity of this task even for three labels. As our main contribution, we show that the complexity of MLC with RCN becomes drastically different in the presence of three or more labels. Specifically, we prove super-polynomial Statistical Query (SQ) lower bounds for this problem. In more detail, even for three labels and constant separation, we give a super-polynomial lower bound on the complexity of any SQ algorithm achieving optimal error. For a larger number of labels and smaller separation, we show a super-polynomial SQ lower bound even for the weaker goal of achieving any constant factor approximation to the optimal loss or even beating the trivial hypothesis.
Reliable Learning of Halfspaces under Gaussian Marginals
Nov 18, 2024We study the problem of PAC learning halfspaces in the reliable agnostic model of Kalai et al. (2012). The reliable PAC model captures learning scenarios where one type of error is costlier than the others. Our main positive result is a new algorithm for reliable learning of Gaussian halfspaces on $\mathbb{R}^d$ with sample and computational complexity $$d^{O(\log (\min\{1/\alpha, 1/\epsilon\}))}\min (2^{\log(1/\epsilon)^{O(\log (1/\alpha))}},2^{\mathrm{poly}(1/\epsilon)})\;,$$ where $\epsilon$ is the excess error and $\alpha$ is the bias of the optimal halfspace. We complement our upper bound with a Statistical Query lower bound suggesting that the $d^{\Omega(\log (1/\alpha))}$ dependence is best possible. Conceptually, our results imply a strong computational separation between reliable agnostic learning and standard agnostic learning of halfspaces in the Gaussian setting.
SQ Lower Bounds for Non-Gaussian Component Analysis with Weaker Assumptions
Mar 07, 2024We study the complexity of Non-Gaussian Component Analysis (NGCA) in the Statistical Query (SQ) model. Prior work developed a general methodology to prove SQ lower bounds for this task that have been applicable to a wide range of contexts. In particular, it was known that for any univariate distribution $A$ satisfying certain conditions, distinguishing between a standard multivariate Gaussian and a distribution that behaves like $A$ in a random hidden direction and like a standard Gaussian in the orthogonal complement, is SQ-hard. The required conditions were that (1) $A$ matches many low-order moments with the standard univariate Gaussian, and (2) the chi-squared norm of $A$ with respect to the standard Gaussian is finite. While the moment-matching condition is necessary for hardness, the chi-squared condition was only required for technical reasons. In this work, we establish that the latter condition is indeed not necessary. In particular, we prove near-optimal SQ lower bounds for NGCA under the moment-matching condition only. Our result naturally generalizes to the setting of a hidden subspace. Leveraging our general SQ lower bound, we obtain near-optimal SQ lower bounds for a range of concrete estimation tasks where existing techniques provide sub-optimal or even vacuous guarantees.
Near-Optimal Cryptographic Hardness of Agnostically Learning Halfspaces and ReLU Regression under Gaussian Marginals
Feb 13, 2023We study the task of agnostically learning halfspaces under the Gaussian distribution. Specifically, given labeled examples $(\mathbf{x},y)$ from an unknown distribution on $\mathbb{R}^n \times \{ \pm 1\}$, whose marginal distribution on $\mathbf{x}$ is the standard Gaussian and the labels $y$ can be arbitrary, the goal is to output a hypothesis with 0-1 loss $\mathrm{OPT}+\epsilon$, where $\mathrm{OPT}$ is the 0-1 loss of the best-fitting halfspace. We prove a near-optimal computational hardness result for this task, under the widely believed sub-exponential time hardness of the Learning with Errors (LWE) problem. Prior hardness results are either qualitatively suboptimal or apply to restricted families of algorithms. Our techniques extend to yield near-optimal lower bounds for related problems, including ReLU regression.
SQ Lower Bounds for Learning Single Neurons with Massart Noise
Oct 18, 2022We study the problem of PAC learning a single neuron in the presence of Massart noise. Specifically, for a known activation function $f: \mathbb{R} \to \mathbb{R}$, the learner is given access to labeled examples $(\mathbf{x}, y) \in \mathbb{R}^d \times \mathbb{R}$, where the marginal distribution of $\mathbf{x}$ is arbitrary and the corresponding label $y$ is a Massart corruption of $f(\langle \mathbf{w}, \mathbf{x} \rangle)$. The goal of the learner is to output a hypothesis $h: \mathbb{R}^d \to \mathbb{R}$ with small squared loss. For a range of activation functions, including ReLUs, we establish super-polynomial Statistical Query (SQ) lower bounds for this learning problem. In more detail, we prove that no efficient SQ algorithm can approximate the optimal error within any constant factor. Our main technical contribution is a novel SQ-hard construction for learning $\{ \pm 1\}$-weight Massart halfspaces on the Boolean hypercube that is interesting on its own right.
Cryptographic Hardness of Learning Halfspaces with Massart Noise
Jul 28, 2022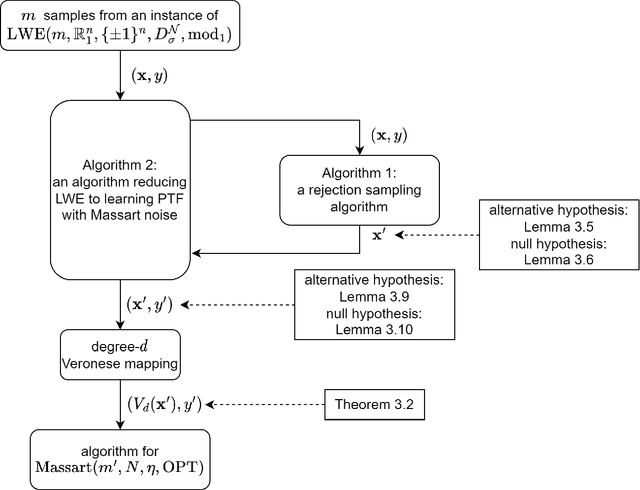
We study the complexity of PAC learning halfspaces in the presence of Massart noise. In this problem, we are given i.i.d. labeled examples $(\mathbf{x}, y) \in \mathbb{R}^N \times \{ \pm 1\}$, where the distribution of $\mathbf{x}$ is arbitrary and the label $y$ is a Massart corruption of $f(\mathbf{x})$, for an unknown halfspace $f: \mathbb{R}^N \to \{ \pm 1\}$, with flipping probability $\eta(\mathbf{x}) \leq \eta < 1/2$. The goal of the learner is to compute a hypothesis with small 0-1 error. Our main result is the first computational hardness result for this learning problem. Specifically, assuming the (widely believed) subexponential-time hardness of the Learning with Errors (LWE) problem, we show that no polynomial-time Massart halfspace learner can achieve error better than $\Omega(\eta)$, even if the optimal 0-1 error is small, namely $\mathrm{OPT} = 2^{-\log^{c} (N)}$ for any universal constant $c \in (0, 1)$. Prior work had provided qualitatively similar evidence of hardness in the Statistical Query model. Our computational hardness result essentially resolves the polynomial PAC learnability of Massart halfspaces, by showing that known efficient learning algorithms for the problem are nearly best possible.