 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Learning Drifting Halfspaces with Massart Noise
Jun 09, 2026We study the problem of learning a drifting concept in the presence of Massart noise. In this framework, an online learner has access to a history of independent samples whose labels are noisy versions of a target concept that may change from round to round. The goal is to output, in each round, a hypothesis with small prediction error. We study the complexity of this learning problem for the fundamental class of margin-separable linear classifiers (halfspaces). On the positive side, we give a computationally efficient learner achieving error $η+ \tilde O(Δ^{1/3}/γ)$, where $η$ upper bounds the Massart noise rate, $Δ$ is the drift rate, and $γ$ is the margin. Interestingly, in the realizable setting, an adaptation of our techniques yields an efficient learner with an improved error rate over prior work. On the lower-bound side, we provide formal evidence of an information-computation tradeoff, strongly suggesting that our algorithm's performance is essentially optimal. Specifically, while the information-theoretically optimal error scales with $Δ^{1/2}$, we prove that $Δ^{1/3}$-scaling is unavoidable for low-degree polynomial tests, even in the special case of random classification noise.
Robust Regression of General ReLUs with Queries
Jun 09, 2026We study the task of agnostically learning general (as opposed to homogeneous) ReLUs under the Gaussian distribution with respect to the squared loss. In the passive learning setting, recent work gave a computationally efficient algorithm that uses $poly(d,1/ε)$ labeled examples and outputs a hypothesis with error $O(opt)+ε$, where $opt$ is the squared loss of the best fit ReLU. Here we focus on the interactive setting, where the learner has some form of query access to the labels of unlabeled examples. Our main result is the first computationally efficient learner that uses $d polylog(1/ε)+\tilde{O}(\min\{1/p, 1/ε\})$ black-box label queries, where $p$ is the bias of the target function, and achieves error $O(opt)+ε$. We complement our algorithmic result by showing that its query complexity bound is qualitatively near-optimal, even ignoring computational constraints. Finally, we establish that query access is essentially necessary to improve on the label complexity of passive learning. Specifically, for pool-based active learning, any active learner requires $\tildeΩ(d/ε)$ labels, unless it draws a super-polynomial number of unlabeled examples.
Polynomial-Time Robust Multiclass Linear Classification under Gaussian Marginals
May 20, 2026We study the task of agnostic learning of multiclass linear classifiers under the Gaussian distribution. Given labeled examples $(x, y)$ from a distribution over $\mathbb{R}^d \times [k]$, with Gaussian $x$-marginal, the goal is to output a hypothesis whose error is comparable to that of the best $k$-class linear classifier. While the binary case $k=2$ has a well-developed algorithmic theory, much less is known for $k \ge 3$. Even for $k=3$, prior robust algorithms incur exponential dependence on the inverse of the desired accuracy in both complexity and representation size. In this work, we develop new structural results for multiclass linear classifiers and use them to design fully polynomial-time robust learners with dimension-independent error guarantees. Our first result shows that the standard multiclass perceptron algorithm requires super-polynomially many samples and updates, even with clean labels and Gaussian marginals, revealing a basic obstruction absent in the binary case. Our main positive result is a pairwise improper-learning framework which yields an efficient learner with error $\widetilde O(k^{3/2}\sqrt{\mathrm{opt}})+ε$ for general $k$. Additionally, we develop a sharper localization-based framework which leads to error $O(\mathrm{opt})+ε$ for $k=3$, and error $\mathrm{poly}(k)\mathrm{opt}+ε$ for geometrically regular $k$-class linear classifiers.
Robust Regression with Adaptive Contamination in Response: Optimal Rates and Computational Barriers
Apr 05, 2026We study robust regression under a contamination model in which covariates are clean while the responses may be corrupted in an adaptive manner. Unlike the classical Huber's contamination model, where both covariates and responses may be contaminated and consistent estimation is impossible when the contamination proportion is a non-vanishing constant, it turns out that the clean-covariate setting admits strictly improved statistical guarantees. Specifically, we show that the additional information in the clean covariates can be carefully exploited to construct an estimator that achieves a better estimation rate than that attainable under Huber contamination. In contrast to the Huber model, this improved rate implies consistency even when the contamination is a constant. A matching minimax lower bound is established using Fano's inequality together with the construction of contamination processes that match $m> 2$ distributions simultaneously, extending the previous two-point lower bound argument in Huber's setting. Despite the improvement over the Huber model from an information-theoretic perspective, we provide formal evidence -- in the form of Statistical Query and Low-Degree Polynomial lower bounds -- that the problem exhibits strong information-computation gaps. Our results strongly suggest that the information-theoretic improvements cannot be achieved by polynomial-time algorithms, revealing a fundamental gap between information-theoretic and computational limits in robust regression with clean covariates.
High-Dimensional Gaussian Mean Estimation under Realizable Contamination
Mar 17, 2026We study mean estimation for a Gaussian distribution with identity covariance in $\mathbb{R}^d$ under a missing data scheme termed realizable $ε$-contamination model. In this model an adversary can choose a function $r(x)$ between 0 and $ε$ and each sample $x$ goes missing with probability $r(x)$. Recent work Ma et al., 2024 proposed this model as an intermediate-strength setting between Missing Completely At Random (MCAR) -- where missingness is independent of the data -- and Missing Not At Random (MNAR) -- where missingness may depend arbitrarily on the sample values and can lead to non-identifiability issues. That work established information-theoretic upper and lower bounds for mean estimation in the realizable contamination model. Their proposed estimators incur runtime exponential in the dimension, leaving open the possibility of computationally efficient algorithms in high dimensions. In this work, we establish an information-computation gap in the Statistical Query model (and, as a corollary, for Low-Degree Polynomials and PTF tests), showing that algorithms must either use substantially more samples than information-theoretically necessary or incur exponential runtime. We complement our SQ lower bound with an algorithm whose sample-time tradeoff nearly matches our lower bound. Together, these results qualitatively characterize the complexity of Gaussian mean estimation under $ε$-realizable contamination.
Expressivity-Efficiency Tradeoffs for Hybrid Sequence Models
Mar 09, 2026Hybrid sequence models--combining Transformer and state-space model layers--seek to gain the expressive versatility of attention as well as the computational efficiency of state-space model layers. Despite burgeoning interest in hybrid models, we lack a basic understanding of the settings where--and underlying mechanisms through which--they offer benefits over their constituent models. In this paper, we study this question, focusing on a broad family of core synthetic tasks. For this family of tasks, we prove the existence of fundamental limitations for non-hybrid models. Specifically, any Transformer or state-space model that solves the underlying task requires either a large number of parameters or a large working memory. On the other hand, for two prototypical tasks within this family--namely selective copying and associative recall--we construct hybrid models of small size and working memory that provably solve these tasks, thus achieving the best of both worlds. Our experimental evaluation empirically validates our theoretical findings. Importantly, going beyond the settings in our theoretical analysis, we empirically show that learned--rather than constructed--hybrids outperform non-hybrid models with up to 6x as many parameters. We additionally demonstrate that hybrid models exhibit stronger length generalization and out-of-distribution robustness than non-hybrids.
Sample Complexity Bounds for Robust Mean Estimation with Mean-Shift Contamination
Feb 25, 2026We study the basic task of mean estimation in the presence of mean-shift contamination. In the mean-shift contamination model, an adversary is allowed to replace a small constant fraction of the clean samples by samples drawn from arbitrarily shifted versions of the base distribution. Prior work characterized the sample complexity of this task for the special cases of the Gaussian and Laplace distributions. Specifically, it was shown that consistent estimation is possible in these cases, a property that is provably impossible in Huber's contamination model. An open question posed in earlier work was to determine the sample complexity of mean estimation in the mean-shift contamination model for general base distributions. In this work, we study and essentially resolve this open question. Specifically, we show that, under mild spectral conditions on the characteristic function of the (potentially multivariate) base distribution, there exists a sample-efficient algorithm that estimates the target mean to any desired accuracy. We complement our upper bound with a qualitatively matching sample complexity lower bound. Our techniques make critical use of Fourier analysis, and in particular introduce the notion of a Fourier witness as an essential ingredient of our upper and lower bounds.
Testable Learning of General Halfspaces under Massart Noise
Feb 25, 2026We study the algorithmic task of testably learning general Massart halfspaces under the Gaussian distribution. In the testable learning setting, the aim is the design of a tester-learner pair satisfying the following properties: (1) if the tester accepts, the learner outputs a hypothesis and a certificate that it achieves near-optimal error, and (2) it is highly unlikely that the tester rejects if the data satisfies the underlying assumptions. Our main result is the first testable learning algorithm for general halfspaces with Massart noise and Gaussian marginals. The complexity of our algorithm is $d^{\mathrm{polylog}(\min\{1/γ, 1/ε\})}$, where $ε$ is the excess error and $γ$ is the bias of the target halfspace, which qualitatively matches the known quasi-polynomial Statistical Query lower bound for the non-testable setting. The analysis of our algorithm hinges on a novel sandwiching polynomial approximation to the sign function with multiplicative error that may be of broader interest.
Statistical Query Lower Bounds for Smoothed Agnostic Learning
Feb 24, 2026We study the complexity of smoothed agnostic learning, recently introduced by~\cite{CKKMS24}, in which the learner competes with the best classifier in a target class under slight Gaussian perturbations of the inputs. Specifically, we focus on the prototypical task of agnostically learning halfspaces under subgaussian distributions in the smoothed model. The best known upper bound for this problem relies on $L_1$-polynomial regression and has complexity $d^{\tilde{O}(1/σ^2) \log(1/ε)}$, where $σ$ is the smoothing parameter and $ε$ is the excess error. Our main result is a Statistical Query (SQ) lower bound providing formal evidence that this upper bound is close to best possible. In more detail, we show that (even for Gaussian marginals) any SQ algorithm for smoothed agnostic learning of halfspaces requires complexity $d^{Ω(1/σ^{2}+\log(1/ε))}$. This is the first non-trivial lower bound on the complexity of this task and nearly matches the known upper bound. Roughly speaking, we show that applying $L_1$-polynomial regression to a smoothed version of the function is essentially best possible. Our techniques involve finding a moment-matching hard distribution by way of linear programming duality. This dual program corresponds exactly to finding a low-degree approximating polynomial to the smoothed version of the target function (which turns out to be the same condition required for the $L_1$-polynomial regression to work). Our explicit SQ lower bound then comes from proving lower bounds on this approximation degree for the class of halfspaces.
Learning Intersections of Two Margin Halfspaces under Factorizable Distributions
Nov 16, 2025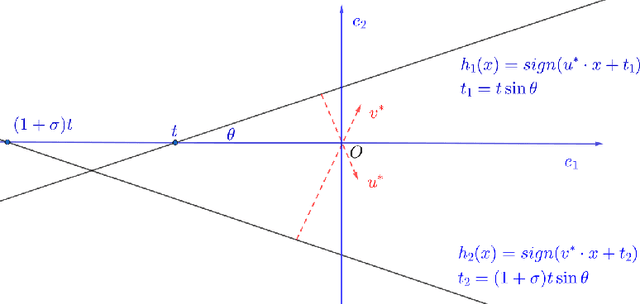
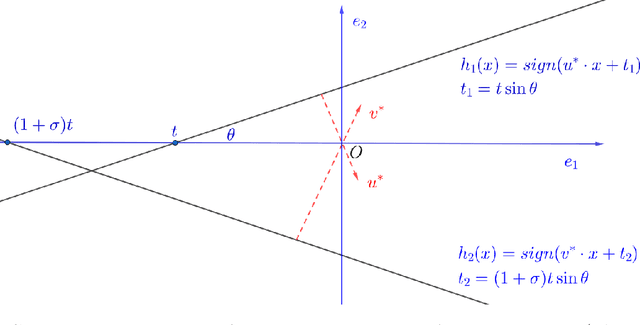
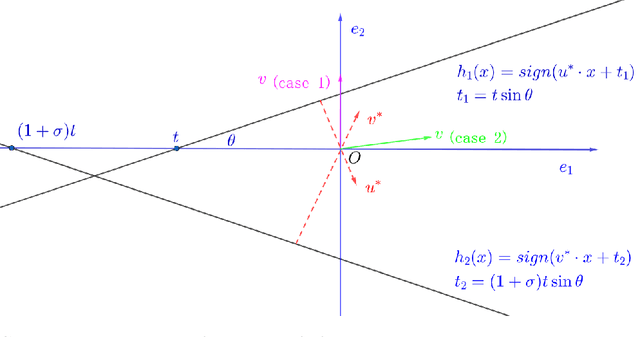

Learning intersections of halfspaces is a central problem in Computational Learning Theory. Even for just two halfspaces, it remains a major open question whether learning is possible in polynomial time with respect to the margin $γ$ of the data points and their dimensionality $d$. The best-known algorithms run in quasi-polynomial time $d^{O(\log(1/γ))}$, and it has been shown that this complexity is unavoidable for any algorithm relying solely on correlational statistical queries (CSQ). In this work, we introduce a novel algorithm that provably circumvents the CSQ hardness barrier. Our approach applies to a broad class of distributions satisfying a natural, previously studied, factorizability assumption. Factorizable distributions lie between distribution-specific and distribution-free settings, and significantly extend previously known tractable cases. Under these distributions, we show that CSQ-based methods still require quasipolynomial time even for weakly learning, whereas our algorithm achieves $poly(d,1/γ)$ time by leveraging more general statistical queries (SQ), establishing a strong separation between CSQ and SQ for this simple realizable PAC learning problem. Our result is grounded in a rigorous analysis utilizing a novel duality framework that characterizes the moment tensor structure induced by the marginal distributions. Building on these structural insights, we propose new, efficient learning algorithms. These algorithms combine a refined variant of Jennrich's Algorithm with PCA over random projections of the moment tensor, along with a gradient-descent-based non-convex optimization framework.