 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization Can Learn Johnson Lindenstrauss Embeddings
Dec 10, 2024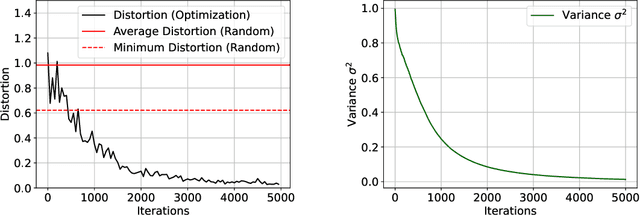
Embeddings play a pivotal role across various disciplines, offering compact representations of complex data structures. Randomized methods like Johnson-Lindenstrauss (JL) provide state-of-the-art and essentially unimprovable theoretical guarantees for achieving such representations. These guarantees are worst-case and in particular, neither the analysis, nor the algorithm, takes into account any potential structural information of the data. The natural question is: must we randomize? Could we instead use an optimization-based approach, working directly with the data? A first answer is no: as we show, the distance-preserving objective of JL has a non-convex landscape over the space of projection matrices, with many bad stationary points. But this is not the final answer. We present a novel method motivated by diffusion models, that circumvents this fundamental challenge: rather than performing optimization directly over the space of projection matrices, we use optimization over the larger space of random solution samplers, gradually reducing the variance of the sampler. We show that by moving through this larger space, our objective converges to a deterministic (zero variance) solution, avoiding bad stationary points. This method can also be seen as an optimization-based derandomization approach and is an idea and method that we believe can be applied to many other problems.