 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETT: Expanding the Long Context Understanding Capability of LLMs at Test-Time
Jul 08, 2025Transformer-based Language Models' computation and memory overhead increase quadratically as a function of sequence length. The quadratic cost poses challenges when employing LLMs for processing long sequences. In this work, we introduce \ourmodelacronym~(Extend at Test-Time), method for extending the context length of short context Transformer-based LLMs, with constant memory requirement and linear computation overhead. ETT enable the extension of the context length at test-time by efficient fine-tuning the model's parameters on the input context, chunked into overlapping small subsequences. We evaluate ETT on LongBench by extending the context length of GPT-Large and Phi-2 up to 32 times, increasing from 1k to 32k tokens. This results in up to a 30 percent improvement in the model's accuracy. We also study how context can be stored in LLM's weights effectively and efficiently. Through a detailed ablation study, we examine which Transformer modules are most beneficial to fine-tune at test-time. Interestingly, we find that fine-tuning the second layer of the FFNs is more effective than full fine-tuning, leading to a further improvement in the models' accuracy.
A Fourier Space Perspective on Diffusion Models
May 16, 2025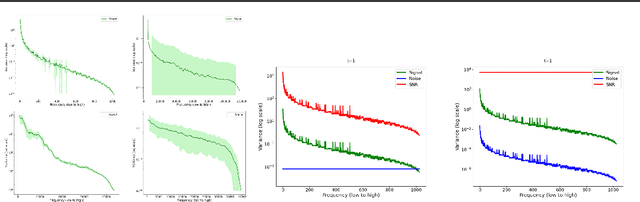

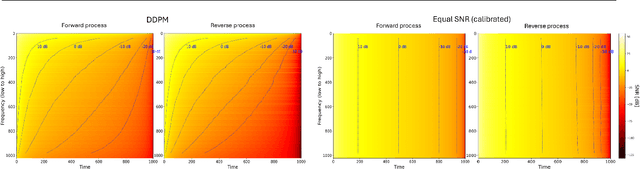
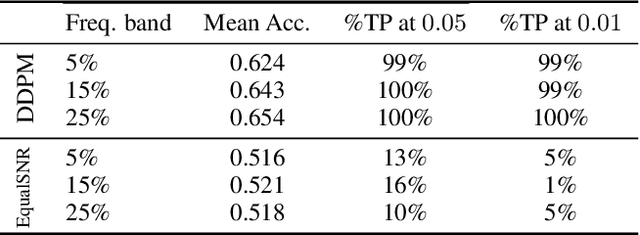
Diffusion models are state-of-the-art generative models on data modalities such as images, audio, proteins and materials. These modalities share the property of exponentially decaying variance and magnitude in the Fourier domain. Under the standard Denoising Diffusion Probabilistic Models (DDPM) forward process of additive white noise, this property results in high-frequency components being corrupted faster and earlier in terms of their Signal-to-Noise Ratio (SNR) than low-frequency ones. The reverse process then generates low-frequency information before high-frequency details. In this work, we study the inductive bias of the forward process of diffusion models in Fourier space. We theoretically analyse and empirically demonstrate that the faster noising of high-frequency components in DDPM results in violations of the normality assumption in the reverse process. Our experiments show that this leads to degraded generation quality of high-frequency components. We then study an alternate forward process in Fourier space which corrupts all frequencies at the same rate, removing the typical frequency hierarchy during generation, and demonstrate marked performance improvements on datasets where high frequencies are primary, while performing on par with DDPM on standard imaging benchmarks.
Deep Generative Models for Subgraph Prediction
Aug 07, 2024Graph Neural Networks (GNNs) are important across different domains, such as social network analysis and recommendation systems, due to their ability to model complex relational data. This paper introduces subgraph queries as a new task for deep graph learning. Unlike traditional graph prediction tasks that focus on individual components like link prediction or node classification, subgraph queries jointly predict the components of a target subgraph based on evidence that is represented by an observed subgraph. For instance, a subgraph query can predict a set of target links and/or node labels. To answer subgraph queries, we utilize a probabilistic deep Graph Generative Model. Specifically, we inductively train a Variational Graph Auto-Encoder (VGAE) model, augmented to represent a joint distribution over links, node features and labels. Bayesian optimization is used to tune a weighting for the relative importance of links, node features and labels in a specific domain. We describe a deterministic and a sampling-based inference method for estimating subgraph probabilities from the VGAE generative graph distribution, without retraining, in zero-shot fashion. For evaluation, we apply the inference methods on a range of subgraph queries on six benchmark datasets. We find that inference from a model achieves superior predictive performance, surpassing independent prediction baselines with improvements in AUC scores ranging from 0.06 to 0.2 points, depending on the dataset.
Micro and Macro Level Graph Modeling for Graph Variational Auto-Encoders
Oct 30, 2022



Generative models for graph data are an important research topic in machine learning. Graph data comprise two levels that are typically analyzed separately: node-level properties such as the existence of a link between a pair of nodes, and global aggregate graph-level statistics, such as motif counts. This paper proposes a new multi-level framework that jointly models node-level properties and graph-level statistics, as mutually reinforcing sources of information. We introduce a new micro-macro training objective for graph generation that combines node-level and graph-level losses. We utilize the micro-macro objective to improve graph generation with a GraphVAE, a well-established model based on graph-level latent variables, that provides fast training and generation time for medium-sized graphs. Our experiments show that adding micro-macro modeling to the GraphVAE model improves graph quality scores up to 2 orders of magnitude on five benchmark datasets, while maintaining the GraphVAE generation speed advantage.
Generating the Graph Gestalt: Kernel-Regularized Graph Representation Learning
Jun 29, 2021

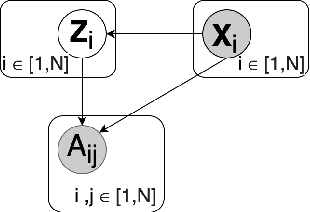

Recent work on graph generative models has made remarkable progress towards generating increasingly realistic graphs, as measured by global graph features such as degree distribution, density, and clustering coefficients. Deep generative models have also made significant advances through better modelling of the local correlations in the graph topology, which have been very useful for predicting unobserved graph components, such as the existence of a link or the class of a node, from nearby observed graph components. A complete scientific understanding of graph data should address both global and local structure. In this paper, we propose a joint model for both as complementary objectives in a graph VAE framework. Global structure is captured by incorporating graph kernels in a probabilistic model whose loss function is closely related to the maximum mean discrepancy(MMD) between the global structures of the reconstructed and the input graphs. The ELBO objective derived from the model regularizes a standard local link reconstruction term with an MMD term. Our experiments demonstrate a significant improvement in the realism of the generated graph structures, typically by 1-2 orders of magnitude of graph structure metrics, compared to leading graph VAEand GAN models. Local link reconstruction improves as well in many cases.