 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-Scores for (In)Correctness Assessment of Generative Model Outputs
Oct 29, 2025While generative models, especially large language models (LLMs), are ubiquitous in today's world, principled mechanisms to assess their (in)correctness are limited. Using the conformal prediction framework, previous works construct sets of LLM responses where the probability of including an incorrect response, or error, is capped at a desired user-defined tolerance level. However, since these methods are based on p-values, they are susceptible to p-hacking, i.e., choosing the tolerance level post-hoc can invalidate the guarantees. We therefore leverage e-values to complement generative model outputs with e-scores as a measure of incorrectness. In addition to achieving the same statistical guarantees as before, e-scores provide users flexibility in adaptively choosing tolerance levels after observing the e-scores themselves, by upper bounding a post-hoc notion of error called size distortion. We experimentally demonstrate their efficacy in assessing LLM outputs for different correctness types: mathematical factuality and property constraints satisfaction.
A Fourier Space Perspective on Diffusion Models
May 16, 2025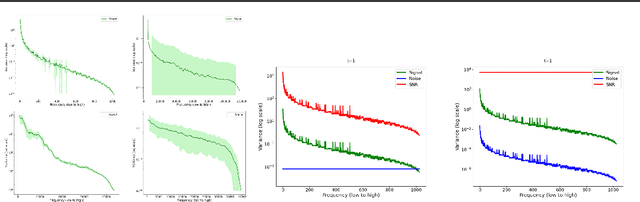

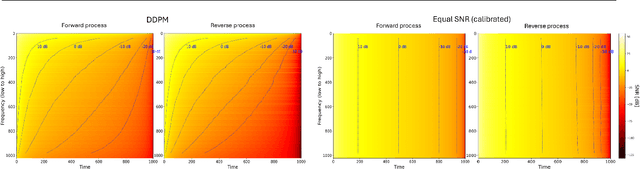
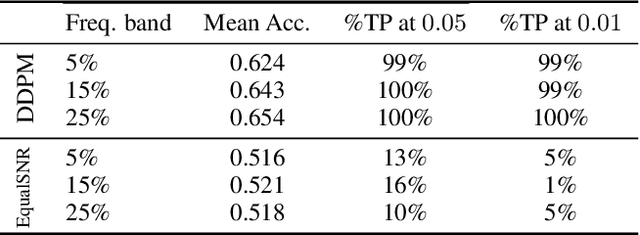
Diffusion models are state-of-the-art generative models on data modalities such as images, audio, proteins and materials. These modalities share the property of exponentially decaying variance and magnitude in the Fourier domain. Under the standard Denoising Diffusion Probabilistic Models (DDPM) forward process of additive white noise, this property results in high-frequency components being corrupted faster and earlier in terms of their Signal-to-Noise Ratio (SNR) than low-frequency ones. The reverse process then generates low-frequency information before high-frequency details. In this work, we study the inductive bias of the forward process of diffusion models in Fourier space. We theoretically analyse and empirically demonstrate that the faster noising of high-frequency components in DDPM results in violations of the normality assumption in the reverse process. Our experiments show that this leads to degraded generation quality of high-frequency components. We then study an alternate forward process in Fourier space which corrupts all frequencies at the same rate, removing the typical frequency hierarchy during generation, and demonstrate marked performance improvements on datasets where high frequencies are primary, while performing on par with DDPM on standard imaging benchmarks.
Robust Multi-view Co-expression Network Inference
Sep 30, 2024



Unraveling the co-expression of genes across studies enhances the understanding of cellular processes. Inferring gene co-expression networks from transcriptome data presents many challenges, including spurious gene correlations, sample correlations, and batch effects. To address these complexities, we introduce a robust method for high-dimensional graph inference from multiple independent studies. We base our approach on the premise that each dataset is essentially a noisy linear mixture of gene loadings that follow a multivariate $t$-distribution with a sparse precision matrix, which is shared across studies. This allows us to show that we can identify the co-expression matrix up to a scaling factor among other model parameters. Our method employs an Expectation-Maximization procedure for parameter estimation. Empirical evaluation on synthetic and gene expression data demonstrates our method's improved ability to learn the underlying graph structure compared to baseline methods.
Deep anytime-valid hypothesis testing
Oct 30, 2023



We propose a general framework for constructing powerful, sequential hypothesis tests for a large class of nonparametric testing problems. The null hypothesis for these problems is defined in an abstract form using the action of two known operators on the data distribution. This abstraction allows for a unified treatment of several classical tasks, such as two-sample testing, independence testing, and conditional-independence testing, as well as modern problems, such as testing for adversarial robustness of machine learning (ML) models. Our proposed framework has the following advantages over classical batch tests: 1) it continuously monitors online data streams and efficiently aggregates evidence against the null, 2) it provides tight control over the type I error without the need for multiple testing correction, 3) it adapts the sample size requirement to the unknown hardness of the problem. We develop a principled approach of leveraging the representation capability of ML models within the testing-by-betting framework, a game-theoretic approach for designing sequential tests. Empirical results on synthetic and real-world datasets demonstrate that tests instantiated using our general framework are competitive against specialized baselines on several tasks.
E-Valuating Classifier Two-Sample Tests
Oct 24, 2022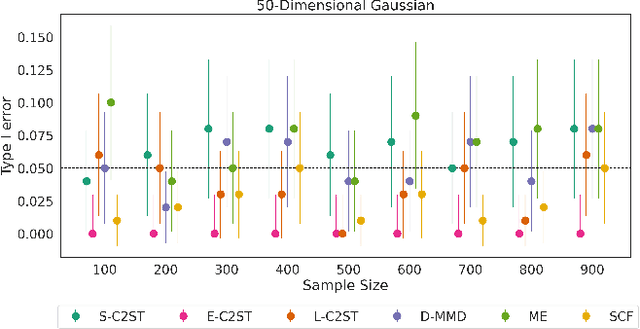
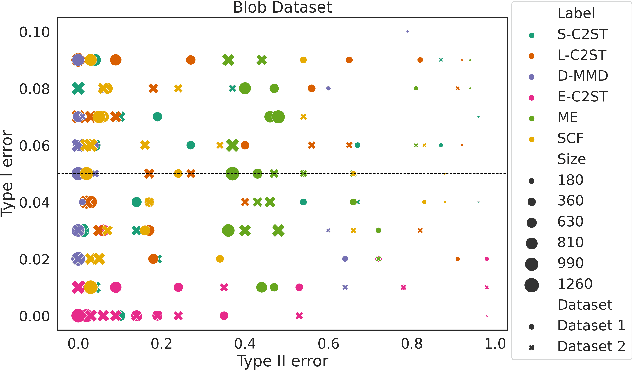
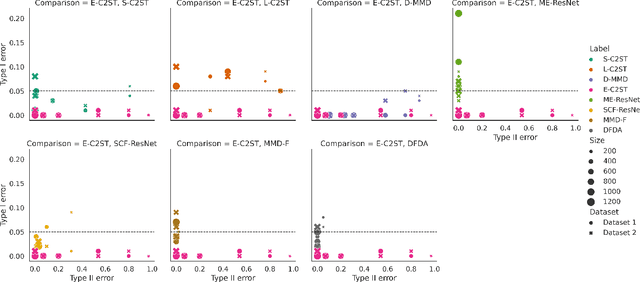
We propose E-C2ST, a classifier two-sample test for high-dimensional data based on E-values. Compared to $p$-values-based tests, tests with E-values have finite sample guarantees for the type I error. E-C2ST combines ideas from existing work on split likelihood ratio tests and predictive independence testing. The resulting E-values incorporate information about the alternative hypothesis. We demonstrate the utility of E-C2ST on simulated and real-life data. In all experiments, we observe that when going from small to large sample sizes, as expected, E-C2ST starts with lower power compared to other methods but eventually converges towards one. Simultaneously, E-C2ST's type I error stays substantially below the chosen significance level, which is not always the case for the baseline methods. Finally, we use an MRI dataset to demonstrate that multiplying E-values from multiple independently conducted studies leads to a combined E-value that retains the finite sample type I error guarantees while increasing the power.
Multi-View Independent Component Analysis with Shared and Individual Sources
Oct 05, 2022



Independent component analysis (ICA) is a blind source separation method for linear disentanglement of independent latent sources from observed data. We investigate the special setting of noisy linear ICA where the observations are split among different views, each receiving a mixture of shared and individual sources. We prove that the corresponding linear structure is identifiable, and the shared sources can be recovered, provided that sufficiently many diverse views and data points are available. To computationally estimate the sources, we optimize a constrained form of the joint log-likelihood of the observed data among all views. We show empirically that our objective recovers the sources in high dimensional settings, also in the case when the measurements are corrupted by noise. Finally, we apply the proposed model in a challenging real-life application, where the estimated shared sources from two large transcriptome datasets (observed data) provided by two different labs (two different views) lead to a more plausible representation of the underlying graph structure than existing baselines.
MMGAN: Generative Adversarial Networks for Multi-Modal Distributions
Nov 15, 2019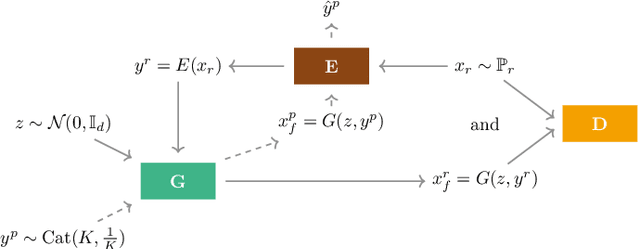
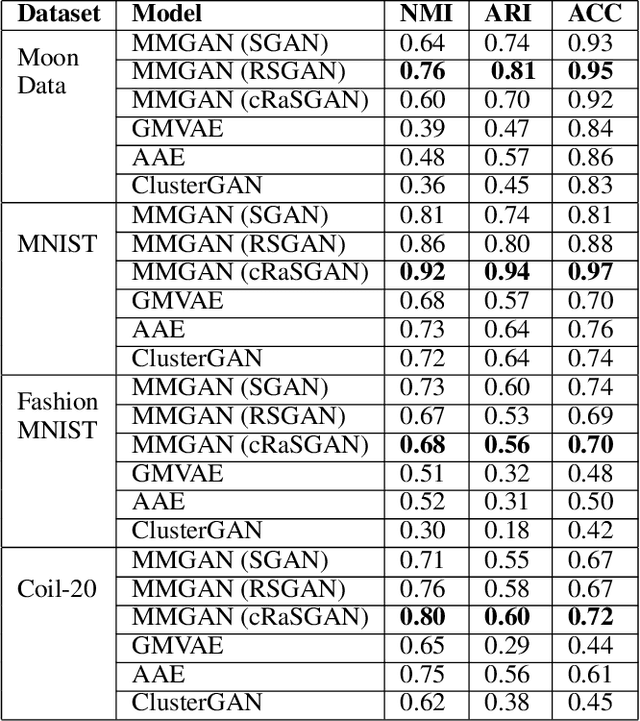
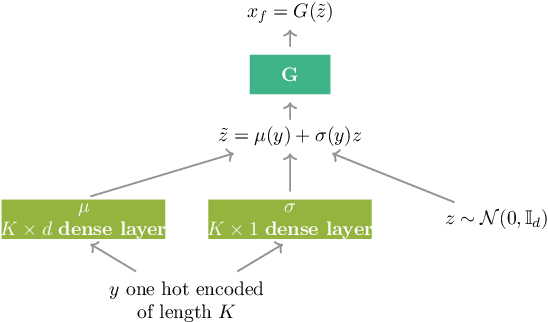
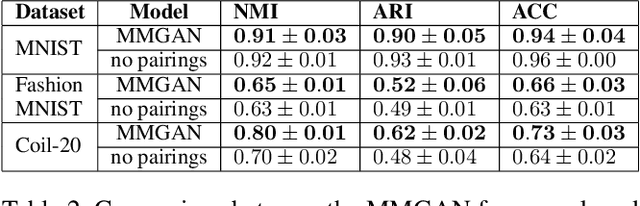
Over the past years, Generative Adversarial Networks (GANs) have shown a remarkable generation performance especially in image synthesis. Unfortunately, they are also known for having an unstable training process and might loose parts of the data distribution for heterogeneous input data. In this paper, we propose a novel GAN extension for multi-modal distribution learning (MMGAN). In our approach, we model the latent space as a Gaussian mixture model with a number of clusters referring to the number of disconnected data manifolds in the observation space, and include a clustering network, which relates each data manifold to one Gaussian cluster. Thus, the training gets more stable. Moreover, MMGAN allows for clustering real data according to the learned data manifold in the latent space. By a series of benchmark experiments, we illustrate that MMGAN outperforms competitive state-of-the-art models in terms of clustering performance.