 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCover meets Robbins while Betting on Bounded Data: $\ln n$ Regret and Almost Sure $\ln\ln n$ Regret
Apr 22, 2026Consider betting against a sequence of data in $[0,1]$, where one is allowed to make any bet that is fair if the data have a conditional mean $m_0 \in (0,1)$. Cover's universal portfolio algorithm delivers a worst-case regret of $O(\ln n)$ compared to the best constant bet in hindsight, and this bound is unimprovable against adversarially generated data. In this work, we present a novel mixture betting strategy that combines insights from Robbins and Cover, and exhibits a different behavior: it eventually produces a regret of $O(\ln \ln n)$ on \emph{almost} all paths (a measure-one set of paths if each conditional mean equals $m_0$ and intrinsic variance increases to $\infty$), but has an $O(\log n)$ regret on the complement (a measure zero set of paths). Our paper appears to be the first to point out the value in hedging two very different strategies to achieve a best-of-both-worlds adaptivity to stochastic data and protection against adversarial data. We contrast our results to those in~\cite{agrawal2025regret} for a sub-Gaussian mixture on unbounded data: their worst-case regret has to be unbounded, but a similar hedging delivers both an optimal betting growth-rate and an almost sure $\ln\ln n$ regret on stochastic data. Finally, our strategy witnesses a sharp game-theoretic upper law of the iterated logarithm, analogous to~\cite{shafer2005probability}.
Power one sequential tests exist for weakly compact $\mathscr P$ against $\mathscr P^c$
Apr 03, 2026Suppose we observe data from a distribution $P$ and we wish to test the composite null hypothesis that $P\in\mathscr P$ against a composite alternative $P\in \mathscr Q\subseteq \mathscr P^c$. Herbert Robbins and coauthors pointed out around 1970 that, while no batch test can have a level $α\in(0,1)$ and power equal to one, sequential tests can be constructed with this fantastic property. Since then, and especially in the last decade, a plethora of sequential tests have been developed for a wide variety of settings. However, the literature has not yet provided a clean and general answer as to when such power-one sequential tests exist. This paper provides a remarkably general sufficient condition (that we also prove is not necessary). Focusing on i.i.d. laws in Polish spaces without any further restriction, we show that there exists a level-$α$ sequential test for any weakly compact $\mathscr P$, that is power-one against $\mathscr P^c$ (or any subset thereof). We show how to aggregate such tests into an $e$-process for $\mathscr P$ that increases to infinity under $\mathscr P^c$. We conclude by building an $e$-process that is asymptotically relatively growth rate optimal against $\mathscr P^c$, an extremely powerful result.
Online monotone density estimation and log-optimal calibration
Feb 09, 2026We study the problem of online monotone density estimation, where density estimators must be constructed in a predictable manner from sequentially observed data. We propose two online estimators: an online analogue of the classical Grenander estimator, and an expert aggregation estimator inspired by exponential weighting methods from the online learning literature. In the well-specified stochastic setting, where the underlying density is monotone, we show that the expected cumulative log-likelihood gap between the online estimators and the true density admits an $O(n^{1/3})$ bound. We further establish a $\sqrt{n\log{n}}$ pathwise regret bound for the expert aggregation estimator relative to the best offline monotone estimator chosen in hindsight, under minimal regularity assumptions on the observed sequence. As an application of independent interest, we show that the problem of constructing log-optimal p-to-e calibrators for sequential hypothesis testing can be formulated as an online monotone density estimation problem. We adapt the proposed estimators to build empirically adaptive p-to-e calibrators and establish their optimality. Numerical experiments illustrate the theoretical results.
Operationalizing Stein's Method for Online Linear Optimization: CLT-Based Optimal Tradeoffs
Feb 06, 2026Adversarial online linear optimization (OLO) is essentially about making performance tradeoffs with respect to the unknown difficulty of the adversary. In the setting of one-dimensional fixed-time OLO on a bounded domain, it has been observed since Cover (1966) that achievable tradeoffs are governed by probabilistic inequalities, and these descriptive results can be converted into algorithms via dynamic programming, which, however, is not computationally efficient. We address this limitation by showing that Stein's method, a classical framework underlying the proofs of probabilistic limit theorems, can be operationalized as computationally efficient OLO algorithms. The associated regret and total loss upper bounds are "additively sharp", meaning that they surpass the conventional big-O optimality and match normal-approximation-based lower bounds by additive lower order terms. Our construction is inspired by the remarkably clean proof of a Wasserstein martingale central limit theorem (CLT) due to Röllin (2018). Several concrete benefits can be obtained from this general technique. First, with the same computational complexity, the proposed algorithm improves upon the total loss upper bounds of online gradient descent (OGD) and multiplicative weight update (MWU). Second, our algorithm can realize a continuum of optimal two-point tradeoffs between the total loss and the maximum regret over comparators, improving upon prior works in parameter-free online learning. Third, by allowing the adversary to randomize on an unbounded support, we achieve sharp in-expectation performance guarantees for OLO with noisy feedback.
Asymptotically optimal sequential change detection for bounded means
Feb 05, 2026We consider the problem of quickest changepoint detection under the Average Run Length (ARL) constraint where the pre-change and post-change laws lie in composite families $\mathscr{P}$ and $\mathscr{Q}$ respectively. In such a problem, a massive challenge is characterizing the best possible detection delay when the "hardest" pre-change law in $\mathscr{P}$ depends on the unknown post-change law $Q\in\mathscr{Q}$. And typical simple-hypothesis likelihood-ratio arguments for Page-CUSUM and Shiryaev-Roberts do not at all apply here. To that end, we derive a universal sharp lower bound in full generality for any ARL-calibrated changepoint detector in the low type-I error ($γ\to\infty$ regime) of the order $\log(γ)/\mathrm{KL}_{\mathrm{inf}}(Q,\mathscr{P})$. We show achievability of this universal lower bound by proving a tight matching upper bound (with the same sharp $\logγ$ constant) in the important bounded mean detection setting. In addition, for separated mean shifts, we also we derive a uniform minimax guarantee of this achievability over the alternatives.
An Asymptotic Law of the Iterated Logarithm for $\mathrm{KL}_{\inf}$
Feb 05, 2026The population $\mathrm{KL}_{\inf}$ is a fundamental quantity that appears in lower bounds for (asymptotically) optimal regret of pure-exploration stochastic bandit algorithms, and optimal stopping time of sequential tests. Motivated by this, an empirical $\mathrm{KL}_{\inf}$ statistic is frequently used in the design of (asymptotically) optimal bandit algorithms and sequential tests. While nonasymptotic concentration bounds for the empirical $\mathrm{KL}_{\inf}$ have been developed, their optimality in terms of constants and rates is questionable, and their generality is limited (usually to bounded observations). The fundamental limits of nonasymptotic concentration are often described by the asymptotic fluctuations of the statistics. With that motivation, this paper presents a tight (upper and lower) law of the iterated logarithm for empirical $\mathrm{KL}_{\inf}$ applying to extremely general (unbounded) data.
Eventually LIL Regret: Almost Sure $\ln\ln T$ Regret for a sub-Gaussian Mixture on Unbounded Data
Dec 13, 2025We prove that a classic sub-Gaussian mixture proposed by Robbins in a stochastic setting actually satisfies a path-wise (deterministic) regret bound. For every path in a natural ``Ville event'' $E_α$, this regret till time $T$ is bounded by $\ln^2(1/α)/V_T + \ln (1/α) + \ln \ln V_T$ up to universal constants, where $V_T$ is a nonnegative, nondecreasing, cumulative variance process. (The bound reduces to $\ln(1/α) + \ln \ln V_T$ if $V_T \geq \ln(1/α)$.) If the data were stochastic, then one can show that $E_α$ has probability at least $1-α$ under a wide class of distributions (eg: sub-Gaussian, symmetric, variance-bounded, etc.). In fact, we show that on the Ville event $E_0$ of probability one, the regret on every path in $E_0$ is eventually bounded by $\ln \ln V_T$ (up to constants). We explain how this work helps bridge the world of adversarial online learning (which usually deals with regret bounds for bounded data), with game-theoretic statistics (which can handle unbounded data, albeit using stochastic assumptions). In short, conditional regret bounds serve as a bridge between stochastic and adversarial betting.
Vector-valued self-normalized concentration inequalities beyond sub-Gaussianity
Nov 05, 2025
The study of self-normalized processes plays a crucial role in a wide range of applications, from sequential decision-making to econometrics. While the behavior of self-normalized concentration has been widely investigated for scalar-valued processes, vector-valued processes remain comparatively underexplored, especially outside of the sub-Gaussian framework. In this contribution, we provide concentration bounds for self-normalized processes with light tails beyond sub-Gaussianity (such as Bennett or Bernstein bounds). We illustrate the relevance of our results in the context of online linear regression, with applications in (kernelized) linear bandits.
Adaptive Off-Policy Inference for M-Estimators Under Model Misspecification
Sep 17, 2025When data are collected adaptively, such as in bandit algorithms, classical statistical approaches such as ordinary least squares and $M$-estimation will often fail to achieve asymptotic normality. Although recent lines of work have modified the classical approaches to ensure valid inference on adaptively collected data, most of these works assume that the model is correctly specified. We propose a method that provides valid inference for M-estimators that use adaptively collected bandit data with a (possibly) misspecified working model. A key ingredient in our approach is the use of flexible machine learning approaches to stabilize the variance induced by adaptive data collection. A major novelty is that our procedure enables the construction of valid confidence sets even in settings where treatment policies are unstable and non-converging, such as when there is no unique optimal arm and standard bandit algorithms are used. Empirical results on semi-synthetic datasets constructed from the Osteoarthritis Initiative demonstrate that the method maintains type I error control, while existing methods for inference in adaptive settings do not cover in the misspecified case.
Sequentially Auditing Differential Privacy
Sep 08, 2025
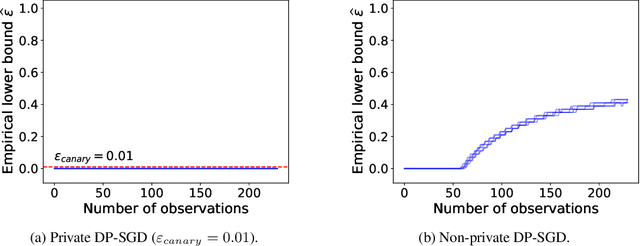
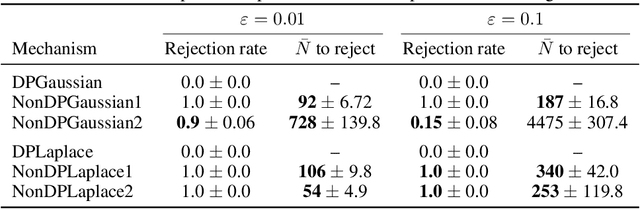
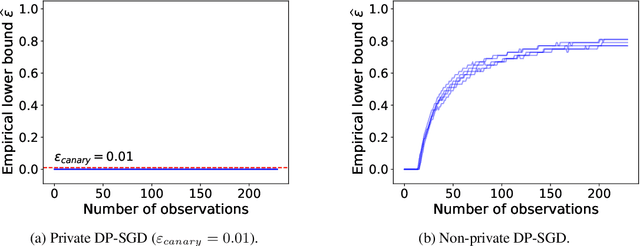
We propose a practical sequential test for auditing differential privacy guarantees of black-box mechanisms. The test processes streams of mechanisms' outputs providing anytime-valid inference while controlling Type I error, overcoming the fixed sample size limitation of previous batch auditing methods. Experiments show this test detects violations with sample sizes that are orders of magnitude smaller than existing methods, reducing this number from 50K to a few hundred examples, across diverse realistic mechanisms. Notably, it identifies DP-SGD privacy violations in \textit{under} one training run, unlike prior methods needing full model training.