 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-LLM Adaptive Conformal Inference for Reliable LLM Responses
Feb 01, 2026Ensuring factuality is essential for the safe use of Large Language Models (LLMs) in high-stakes domains such as medicine and law. Conformal inference provides distribution-free guarantees, but existing approaches are either overly conservative, discarding many true-claims, or rely on adaptive error rates and simple linear models that fail to capture complex group structures. To address these challenges, we reformulate conformal inference in a multiplicative filtering setting, modeling factuality as a product of claim-level scores. Our method, Multi-LLM Adaptive Conformal Inference (MACI), leverages ensembles to produce more accurate factuality-scores, which in our experiments led to higher retention, while validity is preserved through group-conditional calibration. Experiments show that MACI consistently achieves user-specified coverage with substantially higher retention and lower time cost than baselines. Our repository is available at https://github.com/MLAI-Yonsei/MACI
Locally minimax optimal and dimension-agnostic discrete argmin inference
Mar 27, 2025We revisit the discrete argmin inference problem in high-dimensional settings. Given $n$ observations from a $d$ dimensional vector, the goal is to test whether the $r$th component of the mean vector is the smallest among all components. We propose dimension-agnostic tests that maintain validity regardless of how $d$ scales with $n$, and regardless of arbitrary ties in the mean vector. Notably, our validity holds under mild moment conditions, requiring little more than finiteness of a second moment, and permitting possibly strong dependence between coordinates. In addition, we establish the local minimax separation rate for this problem, which adapts to the cardinality of a confusion set, and show that the proposed tests attain this rate. Our method uses the sample splitting and self-normalization approach of Kim and Ramdas (2024). Our tests can be easily inverted to yield confidence sets for the argmin index. Empirical results illustrate the strong performance of our approach in terms of type I error control and power compared to existing methods.
Minimax Optimal Two-Sample Testing under Local Differential Privacy
Nov 13, 2024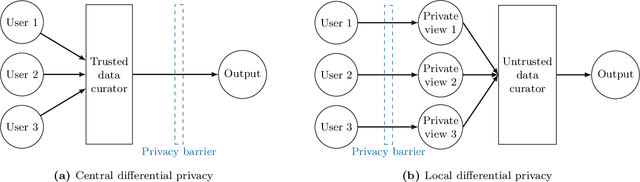



We explore the trade-off between privacy and statistical utility in private two-sample testing under local differential privacy (LDP) for both multinomial and continuous data. We begin by addressing the multinomial case, where we introduce private permutation tests using practical privacy mechanisms such as Laplace, discrete Laplace, and Google's RAPPOR. We then extend our multinomial approach to continuous data via binning and study its uniform separation rates under LDP over H\"older and Besov smoothness classes. The proposed tests for both discrete and continuous cases rigorously control the type I error for any finite sample size, strictly adhere to LDP constraints, and achieve minimax separation rates under LDP. The attained minimax rates reveal inherent privacy-utility trade-offs that are unavoidable in private testing. To address scenarios with unknown smoothness parameters in density testing, we propose an adaptive test based on a Bonferroni-type approach that ensures robust performance without prior knowledge of the smoothness parameters. We validate our theoretical findings with extensive numerical experiments and demonstrate the practical relevance and effectiveness of our proposed methods.
General Frameworks for Conditional Two-Sample Testing
Oct 22, 2024



We study the problem of conditional two-sample testing, which aims to determine whether two populations have the same distribution after accounting for confounding factors. This problem commonly arises in various applications, such as domain adaptation and algorithmic fairness, where comparing two groups is essential while controlling for confounding variables. We begin by establishing a hardness result for conditional two-sample testing, demonstrating that no valid test can have significant power against any single alternative without proper assumptions. We then introduce two general frameworks that implicitly or explicitly target specific classes of distributions for their validity and power. Our first framework allows us to convert any conditional independence test into a conditional two-sample test in a black-box manner, while preserving the asymptotic properties of the original conditional independence test. The second framework transforms the problem into comparing marginal distributions with estimated density ratios, which allows us to leverage existing methods for marginal two-sample testing. We demonstrate this idea in a concrete manner with classification and kernel-based methods. Finally, simulation studies are conducted to illustrate the proposed frameworks in finite-sample scenarios.
Computational-Statistical Trade-off in Kernel Two-Sample Testing with Random Fourier Features
Jul 12, 2024Recent years have seen a surge in methods for two-sample testing, among which the Maximum Mean Discrepancy (MMD) test has emerged as an effective tool for handling complex and high-dimensional data. Despite its success and widespread adoption, the primary limitation of the MMD test has been its quadratic-time complexity, which poses challenges for large-scale analysis. While various approaches have been proposed to expedite the procedure, it has been unclear whether it is possible to attain the same power guarantee as the MMD test at sub-quadratic time cost. To fill this gap, we revisit the approximated MMD test using random Fourier features, and investigate its computational-statistical trade-off. We start by revealing that the approximated MMD test is pointwise consistent in power only when the number of random features approaches infinity. We then consider the uniform power of the test and study the time-power trade-off under the minimax testing framework. Our result shows that, by carefully choosing the number of random features, it is possible to attain the same minimax separation rates as the MMD test within sub-quadratic time. We demonstrate this point under different distributional assumptions such as densities in a Sobolev ball. Our theoretical findings are corroborated by simulation studies.
Enhancing Sufficient Dimension Reduction via Hellinger Correlation
May 30, 2024



In this work, we develop a new theory and method for sufficient dimension reduction (SDR) in single-index models, where SDR is a sub-field of supervised dimension reduction based on conditional independence. Our work is primarily motivated by the recent introduction of the Hellinger correlation as a dependency measure. Utilizing this measure, we develop a method capable of effectively detecting the dimension reduction subspace, complete with theoretical justification. Through extensive numerical experiments, we demonstrate that our proposed method significantly enhances and outperforms existing SDR methods. This improvement is largely attributed to our proposed method's deeper understanding of data dependencies and the refinement of existing SDR techniques.
Robust Kernel Hypothesis Testing under Data Corruption
May 30, 2024We propose two general methods for constructing robust permutation tests under data corruption. The proposed tests effectively control the non-asymptotic type I error under data corruption, and we prove their consistency in power under minimal conditions. This contributes to the practical deployment of hypothesis tests for real-world applications with potential adversarial attacks. One of our methods inherently ensures differential privacy, further broadening its applicability to private data analysis. For the two-sample and independence settings, we show that our kernel robust tests are minimax optimal, in the sense that they are guaranteed to be non-asymptotically powerful against alternatives uniformly separated from the null in the kernel MMD and HSIC metrics at some optimal rate (tight with matching lower bound). Finally, we provide publicly available implementations and empirically illustrate the practicality of our proposed tests.
Semi-Supervised U-statistics
Mar 09, 2024Semi-supervised datasets are ubiquitous across diverse domains where obtaining fully labeled data is costly or time-consuming. The prevalence of such datasets has consistently driven the demand for new tools and methods that exploit the potential of unlabeled data. Responding to this demand, we introduce semi-supervised U-statistics enhanced by the abundance of unlabeled data, and investigate their statistical properties. We show that the proposed approach is asymptotically Normal and exhibits notable efficiency gains over classical U-statistics by effectively integrating various powerful prediction tools into the framework. To understand the fundamental difficulty of the problem, we derive minimax lower bounds in semi-supervised settings and showcase that our procedure is semi-parametrically efficient under regularity conditions. Moreover, tailored to bivariate kernels, we propose a refined approach that outperforms the classical U-statistic across all degeneracy regimes, and demonstrate its optimality properties. Simulation studies are conducted to corroborate our findings and to further demonstrate our framework.
Differentially Private Permutation Tests: Applications to Kernel Methods
Oct 29, 2023Recent years have witnessed growing concerns about the privacy of sensitive data. In response to these concerns, differential privacy has emerged as a rigorous framework for privacy protection, gaining widespread recognition in both academic and industrial circles. While substantial progress has been made in private data analysis, existing methods often suffer from impracticality or a significant loss of statistical efficiency. This paper aims to alleviate these concerns in the context of hypothesis testing by introducing differentially private permutation tests. The proposed framework extends classical non-private permutation tests to private settings, maintaining both finite-sample validity and differential privacy in a rigorous manner. The power of the proposed test depends on the choice of a test statistic, and we establish general conditions for consistency and non-asymptotic uniform power. To demonstrate the utility and practicality of our framework, we focus on reproducing kernel-based test statistics and introduce differentially private kernel tests for two-sample and independence testing: dpMMD and dpHSIC. The proposed kernel tests are straightforward to implement, applicable to various types of data, and attain minimax optimal power across different privacy regimes. Our empirical evaluations further highlight their competitive power under various synthetic and real-world scenarios, emphasizing their practical value. The code is publicly available to facilitate the implementation of our framework.
A Permutation-Free Kernel Independence Test
Dec 18, 2022



In nonparametric independence testing, we observe i.i.d.\ data $\{(X_i,Y_i)\}_{i=1}^n$, where $X \in \mathcal{X}, Y \in \mathcal{Y}$ lie in any general spaces, and we wish to test the null that $X$ is independent of $Y$. Modern test statistics such as the kernel Hilbert-Schmidt Independence Criterion (HSIC) and Distance Covariance (dCov) have intractable null distributions due to the degeneracy of the underlying U-statistics. Thus, in practice, one often resorts to using permutation testing, which provides a nonasymptotic guarantee at the expense of recalculating the quadratic-time statistics (say) a few hundred times. This paper provides a simple but nontrivial modification of HSIC and dCov (called xHSIC and xdCov, pronounced ``cross'' HSIC/dCov) so that they have a limiting Gaussian distribution under the null, and thus do not require permutations. This requires building on the newly developed theory of cross U-statistics by Kim and Ramdas (2020), and in particular developing several nontrivial extensions of the theory in Shekhar et al. (2022), which developed an analogous permutation-free kernel two-sample test. We show that our new tests, like the originals, are consistent against fixed alternatives, and minimax rate optimal against smooth local alternatives. Numerical simulations demonstrate that compared to the full dCov or HSIC, our variants have the same power up to a $\sqrt 2$ factor, giving practitioners a new option for large problems or data-analysis pipelines where computation, not sample size, could be the bottleneck.