 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcentration of General Stochastic Approximation Under Heavy-Tailed Markovian Noise
May 20, 2026We establish maximal concentration bounds for the iterates generated by stochastic approximation algorithms with general step sizes, where the noise has a finite-state Markovian component plus a Martingale-difference component. When the Martingale-difference noise is bounded, we show that the tail of the error can be sub-Gaussian, sub-Weibull, or something lighter than any Pareto but heavier than any Weibull, depending on the step size sequence and on whether the random operator is almost surely contractive, almost surely non-expansive, or expansive with positive probability. Our analysis relies on a novel Lyapunov function involving the moment-generating function of the solution to a Poisson equation, together with an auxiliary projected algorithm. We complement the upper bounds with worst-case examples showing that qualitatively sharper bounds are impossible. We further study the case of unbounded Martingale-difference noise when the average operator is contractive, and the step sizes are of order $1/k$. In this setting, we show that if the random operator is almost surely non-expansive, then the error tail is at most three times heavier than the noise tail, whereas if the random operator is expansive with positive probability, then the error may have substantially heavier tails. These results are obtained through a novel black-box truncation argument that reduces the unbounded-noise setting to the bounded-noise case.
Cover meets Robbins while Betting on Bounded Data: $\ln n$ Regret and Almost Sure $\ln\ln n$ Regret
Apr 22, 2026Consider betting against a sequence of data in $[0,1]$, where one is allowed to make any bet that is fair if the data have a conditional mean $m_0 \in (0,1)$. Cover's universal portfolio algorithm delivers a worst-case regret of $O(\ln n)$ compared to the best constant bet in hindsight, and this bound is unimprovable against adversarially generated data. In this work, we present a novel mixture betting strategy that combines insights from Robbins and Cover, and exhibits a different behavior: it eventually produces a regret of $O(\ln \ln n)$ on \emph{almost} all paths (a measure-one set of paths if each conditional mean equals $m_0$ and intrinsic variance increases to $\infty$), but has an $O(\log n)$ regret on the complement (a measure zero set of paths). Our paper appears to be the first to point out the value in hedging two very different strategies to achieve a best-of-both-worlds adaptivity to stochastic data and protection against adversarial data. We contrast our results to those in~\cite{agrawal2025regret} for a sub-Gaussian mixture on unbounded data: their worst-case regret has to be unbounded, but a similar hedging delivers both an optimal betting growth-rate and an almost sure $\ln\ln n$ regret on stochastic data. Finally, our strategy witnesses a sharp game-theoretic upper law of the iterated logarithm, analogous to~\cite{shafer2005probability}.
Regret Tail Characterization of Optimal Bandit Algorithms with Generic Rewards
Apr 16, 2026We study the tail behavior of regret in stochastic multi-armed bandits for algorithms that are asymptotically optimal in expectation. While minimizing expected regret is the classical objective, recent work shows that even such algorithms can exhibit heavy regret tails, incurring large regret with non-negligible probability. Existing sharp characterizations of regret tails are largely restricted to parametric settings, such as single-parameter exponential families. In this work, we extend the $\KLinf$-UCB algorithm of to a broad nonparametric class of reward distributions satisfying mild assumptions, and establish its asymptotic optimality in expectation. We then analyze the tail behavior of its regret and derive a novel upper bound on the regret tail probability. As special cases, our results recover regret-tail guarantees for both bounded-support and heavy-tailed (moment-bounded) bandit models. Moreover, for the special case of finitely-supported reward distributions, our upper bound matches the known lower bound exactly. Our results thus provide a unified and tight characterization of regret tails for asymptotically optimal KL-based UCB algorithms, going beyond parametric models.
Asymptotically Optimal Sequential Testing with Markovian Data
Feb 19, 2026We study one-sided and $α$-correct sequential hypothesis testing for data generated by an ergodic Markov chain. The null hypothesis is that the unknown transition matrix belongs to a prescribed set $P$ of stochastic matrices, and the alternative corresponds to a disjoint set $Q$. We establish a tight non-asymptotic instance-dependent lower bound on the expected stopping time of any valid sequential test under the alternative. Our novel analysis improves the existing lower bounds, which are either asymptotic or provably sub-optimal in this setting. Our lower bound incorporates both the stationary distribution and the transition structure induced by the unknown Markov chain. We further propose an optimal test whose expected stopping time matches this lower bound asymptotically as $α\to 0$. We illustrate the usefulness of our framework through applications to sequential detection of model misspecification in Markov Chain Monte Carlo and to testing structural properties, such as the linearity of transition dynamics, in Markov decision processes. Our findings yield a sharp and general characterization of optimal sequential testing procedures under Markovian dependence.
Eventually LIL Regret: Almost Sure $\ln\ln T$ Regret for a sub-Gaussian Mixture on Unbounded Data
Dec 13, 2025We prove that a classic sub-Gaussian mixture proposed by Robbins in a stochastic setting actually satisfies a path-wise (deterministic) regret bound. For every path in a natural ``Ville event'' $E_α$, this regret till time $T$ is bounded by $\ln^2(1/α)/V_T + \ln (1/α) + \ln \ln V_T$ up to universal constants, where $V_T$ is a nonnegative, nondecreasing, cumulative variance process. (The bound reduces to $\ln(1/α) + \ln \ln V_T$ if $V_T \geq \ln(1/α)$.) If the data were stochastic, then one can show that $E_α$ has probability at least $1-α$ under a wide class of distributions (eg: sub-Gaussian, symmetric, variance-bounded, etc.). In fact, we show that on the Ville event $E_0$ of probability one, the regret on every path in $E_0$ is eventually bounded by $\ln \ln V_T$ (up to constants). We explain how this work helps bridge the world of adversarial online learning (which usually deals with regret bounds for bounded data), with game-theoretic statistics (which can handle unbounded data, albeit using stochastic assumptions). In short, conditional regret bounds serve as a bridge between stochastic and adversarial betting.
On Stopping Times of Power-one Sequential Tests: Tight Lower and Upper Bounds
Apr 28, 2025We prove two lower bounds for stopping times of sequential tests between general composite nulls and alternatives. The first lower bound is for the setting where the type-1 error level $\alpha$ approaches zero, and equals $\log(1/\alpha)$ divided by a certain infimum KL divergence, termed $\operatorname{KL_{inf}}$. The second lower bound applies to the setting where $\alpha$ is fixed and $\operatorname{KL_{inf}}$ approaches 0 (meaning that the null and alternative sets are not separated) and equals $c \operatorname{KL_{inf}}^{-1} \log \log \operatorname{KL_{inf}}^{-1}$ for a universal constant $c > 0$. We also provide a sufficient condition for matching the upper bounds and show that this condition is met in several special cases. Given past work, these upper and lower bounds are unsurprising in their form; our main contribution is the generality in which they hold, for example, not requiring reference measures or compactness of the classes.
Markov Chain Variance Estimation: A Stochastic Approximation Approach
Sep 09, 2024
We consider the problem of estimating the asymptotic variance of a function defined on a Markov chain, an important step for statistical inference of the stationary mean. We design the first recursive estimator that requires $O(1)$ computation at each step, does not require storing any historical samples or any prior knowledge of run-length, and has optimal $O(\frac{1}{n})$ rate of convergence for the mean-squared error (MSE) with provable finite sample guarantees. Here, $n$ refers to the total number of samples generated. The previously best-known rate of convergence in MSE was $O(\frac{\log n}{n})$, achieved by jackknifed estimators, which also do not enjoy these other desirable properties. Our estimator is based on linear stochastic approximation of an equivalent formulation of the asymptotic variance in terms of the solution of the Poisson equation. We generalize our estimator in several directions, including estimating the covariance matrix for vector-valued functions, estimating the stationary variance of a Markov chain, and approximately estimating the asymptotic variance in settings where the state space of the underlying Markov chain is large. We also show applications of our estimator in average reward reinforcement learning (RL), where we work with asymptotic variance as a risk measure to model safety-critical applications. We design a temporal-difference type algorithm tailored for policy evaluation in this context. We consider both the tabular and linear function approximation settings. Our work paves the way for developing actor-critic style algorithms for variance-constrained RL.
Optimal Top-Two Method for Best Arm Identification and Fluid Analysis
Mar 14, 2024



Top-$2$ methods have become popular in solving the best arm identification (BAI) problem. The best arm, or the arm with the largest mean amongst finitely many, is identified through an algorithm that at any sequential step independently pulls the empirical best arm, with a fixed probability $\beta$, and pulls the best challenger arm otherwise. The probability of incorrect selection is guaranteed to lie below a specified $\delta >0$. Information theoretic lower bounds on sample complexity are well known for BAI problem and are matched asymptotically as $\delta \rightarrow 0$ by computationally demanding plug-in methods. The above top 2 algorithm for any $\beta \in (0,1)$ has sample complexity within a constant of the lower bound. However, determining the optimal $\beta$ that matches the lower bound has proven difficult. In this paper, we address this and propose an optimal top-2 type algorithm. We consider a function of allocations anchored at a threshold. If it exceeds the threshold then the algorithm samples the empirical best arm. Otherwise, it samples the challenger arm. We show that the proposed algorithm is optimal as $\delta \rightarrow 0$. Our analysis relies on identifying a limiting fluid dynamics of allocations that satisfy a series of ordinary differential equations pasted together and that describe the asymptotic path followed by our algorithm. We rely on the implicit function theorem to show existence and uniqueness of these fluid ode's and to show that the proposed algorithm remains close to the ode solution.
CRIMED: Lower and Upper Bounds on Regret for Bandits with Unbounded Stochastic Corruption
Sep 28, 2023



We investigate the regret-minimisation problem in a multi-armed bandit setting with arbitrary corruptions. Similar to the classical setup, the agent receives rewards generated independently from the distribution of the arm chosen at each time. However, these rewards are not directly observed. Instead, with a fixed $\varepsilon\in (0,\frac{1}{2})$, the agent observes a sample from the chosen arm's distribution with probability $1-\varepsilon$, or from an arbitrary corruption distribution with probability $\varepsilon$. Importantly, we impose no assumptions on these corruption distributions, which can be unbounded. In this setting, accommodating potentially unbounded corruptions, we establish a problem-dependent lower bound on regret for a given family of arm distributions. We introduce CRIMED, an asymptotically-optimal algorithm that achieves the exact lower bound on regret for bandits with Gaussian distributions with known variance. Additionally, we provide a finite-sample analysis of CRIMED's regret performance. Notably, CRIMED can effectively handle corruptions with $\varepsilon$ values as high as $\frac{1}{2}$. Furthermore, we develop a tight concentration result for medians in the presence of arbitrary corruptions, even with $\varepsilon$ values up to $\frac{1}{2}$, which may be of independent interest. We also discuss an extension of the algorithm for handling misspecification in Gaussian model.
Optimal Best-Arm Identification in Bandits with Access to Offline Data
Jun 15, 2023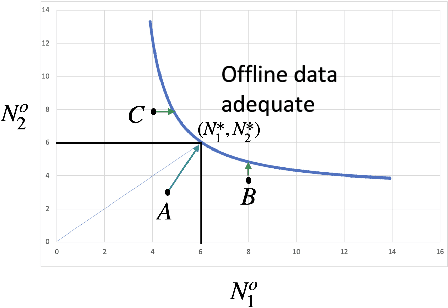
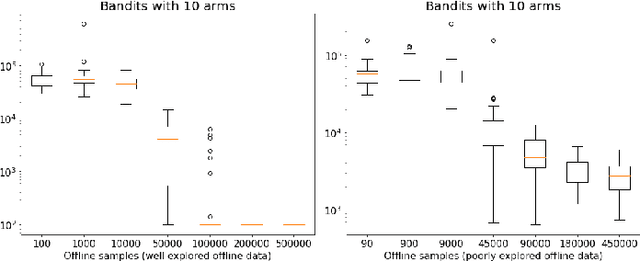
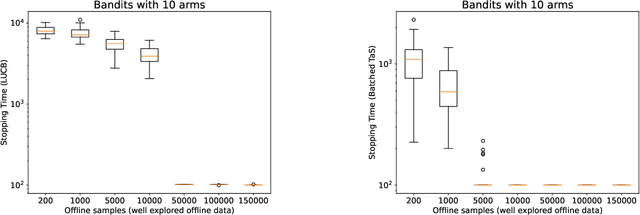
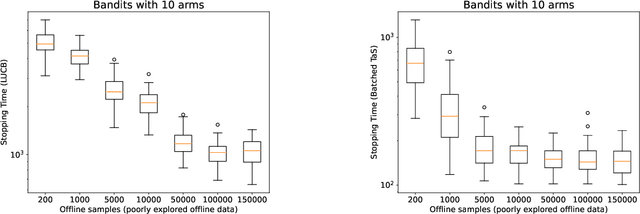
Learning paradigms based purely on offline data as well as those based solely on sequential online learning have been well-studied in the literature. In this paper, we consider combining offline data with online learning, an area less studied but of obvious practical importance. We consider the stochastic $K$-armed bandit problem, where our goal is to identify the arm with the highest mean in the presence of relevant offline data, with confidence $1-\delta$. We conduct a lower bound analysis on policies that provide such $1-\delta$ probabilistic correctness guarantees. We develop algorithms that match the lower bound on sample complexity when $\delta$ is small. Our algorithms are computationally efficient with an average per-sample acquisition cost of $\tilde{O}(K)$, and rely on a careful characterization of the optimality conditions of the lower bound problem.