 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteady-State Behavior of Constant-Stepsize Stochastic Approximation: Gaussian Approximation and Tail Bounds
Feb 15, 2026Constant-stepsize stochastic approximation (SA) is widely used in learning for computational efficiency. For a fixed stepsize, the iterates typically admit a stationary distribution that is rarely tractable. Prior work shows that as the stepsize $α\downarrow 0$, the centered-and-scaled steady state converges weakly to a Gaussian random vector. However, for fixed $α$, this weak convergence offers no usable error bound for approximating the steady-state by its Gaussian limit. This paper provides explicit, non-asymptotic error bounds for fixed $α$. We first prove general-purpose theorems that bound the Wasserstein distance between the centered-scaled steady state and an appropriate Gaussian distribution, under regularity conditions for drift and moment conditions for noise. To ensure broad applicability, we cover both i.i.d. and Markovian noise models. We then instantiate these theorems for three representative SA settings: (1) stochastic gradient descent (SGD) for smooth strongly convex objectives, (2) linear SA, and (3) contractive nonlinear SA. We obtain dimension- and stepsize-dependent, explicit bounds in Wasserstein distance of order $α^{1/2}\log(1/α)$ for small $α$. Building on the Wasserstein approximation error, we further derive non-uniform Berry--Esseen-type tail bounds that compare the steady-state tail probability to Gaussian tails. We achieve an explicit error term that decays in both the deviation level and stepsize $α$. We adapt the same analysis for SGD beyond strongly convexity and study general convex objectives. We identify a non-Gaussian (Gibbs) limiting law under the correct scaling, which is validated numerically, and provide a corresponding pre-limit Wasserstein error bound.
Quantifying Normality: Convergence Rate to Gaussian Limit for Stochastic Approximation and Unadjusted OU Algorithm
Feb 14, 2026Stochastic approximation (SA) is a method for finding the root of an operator perturbed by noise. There is a rich literature establishing the asymptotic normality of rescaled SA iterates under fairly mild conditions. However, these asymptotic results do not quantify the accuracy of the Gaussian approximation in finite time. In this paper, we establish explicit non-asymptotic bounds on the Wasserstein distance between the distribution of the rescaled iterate at time k and the asymptotic Gaussian limit for various choices of step-sizes including constant and polynomially decaying. As an immediate consequence, we obtain tail bounds on the error of SA iterates at any time. We obtain the sharp rates by first studying the convergence rate of the discrete Ornstein-Uhlenbeck (O-U) process driven by general noise, whose stationary distribution is identical to the limiting Gaussian distribution of the rescaled SA iterates. We believe that this is of independent interest, given its connection to sampling literature. The analysis involves adapting Stein's method for Gaussian approximation to handle the matrix weighted sum of i.i.d. random variables. The desired finite-time bounds for SA are obtained by characterizing the error dynamics between the rescaled SA iterate and the discrete time O-U process and combining it with the convergence rate of the latter process.
A Non-Asymptotic Theory of Seminorm Lyapunov Stability: From Deterministic to Stochastic Iterative Algorithms
Feb 20, 2025We study the problem of solving fixed-point equations for seminorm-contractive operators and establish foundational results on the non-asymptotic behavior of iterative algorithms in both deterministic and stochastic settings. Specifically, in the deterministic setting, we prove a fixed-point theorem for seminorm-contractive operators, showing that iterates converge geometrically to the kernel of the seminorm. In the stochastic setting, we analyze the corresponding stochastic approximation (SA) algorithm under seminorm-contractive operators and Markovian noise, providing a finite-sample analysis for various stepsize choices. A benchmark for equation solving is linear systems of equations, where the convergence behavior of fixed-point iteration is closely tied to the stability of linear dynamical systems. In this special case, our results provide a complete characterization of system stability with respect to a seminorm, linking it to the solution of a Lyapunov equation in terms of positive semi-definite matrices. In the stochastic setting, we establish a finite-sample analysis for linear Markovian SA without requiring the Hurwitzness assumption. Our theoretical results offer a unified framework for deriving finite-sample bounds for various reinforcement learning algorithms in the average reward setting, including TD($\lambda$) for policy evaluation (which is a special case of solving a Poisson equation) and Q-learning for control.
Stochastic Approximation with Unbounded Markovian Noise: A General-Purpose Theorem
Oct 29, 2024Motivated by engineering applications such as resource allocation in networks and inventory systems, we consider average-reward Reinforcement Learning with unbounded state space and reward function. Recent works studied this problem in the actor-critic framework and established finite sample bounds assuming access to a critic with certain error guarantees. We complement their work by studying Temporal Difference (TD) learning with linear function approximation and establishing finite-time bounds with the optimal $\mathcal{O}\left(1/\epsilon^2\right)$ sample complexity. These results are obtained using the following general-purpose theorem for non-linear Stochastic Approximation (SA). Suppose that one constructs a Lyapunov function for a non-linear SA with certain drift condition. Then, our theorem establishes finite-time bounds when this SA is driven by unbounded Markovian noise under suitable conditions. It serves as a black box tool to generalize sample guarantees on SA from i.i.d. or martingale difference case to potentially unbounded Markovian noise. The generality and the mild assumption of the setup enables broad applicability of our theorem. We illustrate its power by studying two more systems: (i) We improve upon the finite-time bounds of $Q$-learning by tightening the error bounds and also allowing for a larger class of behavior policies. (ii) We establish the first ever finite-time bounds for distributed stochastic optimization of high-dimensional smooth strongly convex function using cyclic block coordinate descent.
Markov Chain Variance Estimation: A Stochastic Approximation Approach
Sep 09, 2024
We consider the problem of estimating the asymptotic variance of a function defined on a Markov chain, an important step for statistical inference of the stationary mean. We design the first recursive estimator that requires $O(1)$ computation at each step, does not require storing any historical samples or any prior knowledge of run-length, and has optimal $O(\frac{1}{n})$ rate of convergence for the mean-squared error (MSE) with provable finite sample guarantees. Here, $n$ refers to the total number of samples generated. The previously best-known rate of convergence in MSE was $O(\frac{\log n}{n})$, achieved by jackknifed estimators, which also do not enjoy these other desirable properties. Our estimator is based on linear stochastic approximation of an equivalent formulation of the asymptotic variance in terms of the solution of the Poisson equation. We generalize our estimator in several directions, including estimating the covariance matrix for vector-valued functions, estimating the stationary variance of a Markov chain, and approximately estimating the asymptotic variance in settings where the state space of the underlying Markov chain is large. We also show applications of our estimator in average reward reinforcement learning (RL), where we work with asymptotic variance as a risk measure to model safety-critical applications. We design a temporal-difference type algorithm tailored for policy evaluation in this context. We consider both the tabular and linear function approximation settings. Our work paves the way for developing actor-critic style algorithms for variance-constrained RL.
Performance of NPG in Countable State-Space Average-Cost RL
May 30, 2024We consider policy optimization methods in reinforcement learning settings where the state space is arbitrarily large, or even countably infinite. The motivation arises from control problems in communication networks, matching markets, and other queueing systems. We consider Natural Policy Gradient (NPG), which is a popular algorithm for finite state spaces. Under reasonable assumptions, we derive a performance bound for NPG that is independent of the size of the state space, provided the error in policy evaluation is within a factor of the true value function. We obtain this result by establishing new policy-independent bounds on the solution to Poisson's equation, i.e., the relative value function, and by combining these bounds with previously known connections between MDPs and learning from experts.
Convergence for Natural Policy Gradient on Infinite-State Average-Reward Markov Decision Processes
Feb 07, 2024Infinite-state Markov Decision Processes (MDPs) are essential in modeling and optimizing a wide variety of engineering problems. In the reinforcement learning (RL) context, a variety of algorithms have been developed to learn and optimize these MDPs. At the heart of many popular policy-gradient based learning algorithms, such as natural actor-critic, TRPO, and PPO, lies the Natural Policy Gradient (NPG) algorithm. Convergence results for these RL algorithms rest on convergence results for the NPG algorithm. However, all existing results on the convergence of the NPG algorithm are limited to finite-state settings. We prove the first convergence rate bound for the NPG algorithm for infinite-state average-reward MDPs, proving a $O(1/\sqrt{T})$ convergence rate, if the NPG algorithm is initialized with a good initial policy. Moreover, we show that in the context of a large class of queueing MDPs, the MaxWeight policy suffices to satisfy our initial-policy requirement and achieve a $O(1/\sqrt{T})$ convergence rate. Key to our result are state-dependent bounds on the relative value function achieved by the iterate policies of the NPG algorithm.
Tight Finite Time Bounds of Two-Time-Scale Linear Stochastic Approximation with Markovian Noise
Dec 31, 2023Stochastic approximation (SA) is an iterative algorithm to find the fixed point of an operator given noisy samples of this operator. SA appears in many areas such as optimization and Reinforcement Learning (RL). When implemented in practice, the noise that appears in the update of RL algorithms is naturally Markovian. Furthermore, in some settings, such as gradient TD, SA is employed in a two-time-scale manner. The mix of Markovian noise along with the two-time-scale structure results in an algorithm which is complex to analyze theoretically. In this paper, we characterize a tight convergence bound for the iterations of linear two-time-scale SA with Markovian noise. Our results show the convergence behavior of this algorithm given various choices of step sizes. Applying our result to the well-known TDC algorithm, we show the first $O(1/\epsilon)$ sample complexity for the convergence of this algorithm, outperforming all the previous work. Similarly, our results can be applied to establish the convergence behavior of a variety of RL algorithms, such as TD-learning with Polyak averaging, GTD, and GTD2.
Concentration of Contractive Stochastic Approximation: Additive and Multiplicative Noise
Mar 28, 2023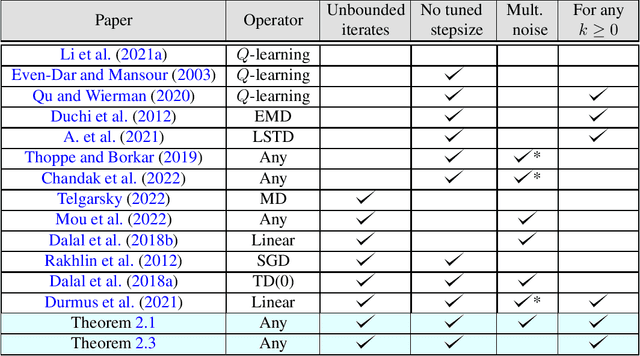
In this work, we study the concentration behavior of a stochastic approximation (SA) algorithm under a contractive operator with respect to an arbitrary norm. We consider two settings where the iterates are potentially unbounded: (1) bounded multiplicative noise, and (2) additive sub-Gaussian noise. We obtain maximal concentration inequalities on the convergence errors, and show that these errors have sub-Gaussian tails in the additive noise setting, and super-polynomial tails (faster than polynomial decay) in the multiplicative noise setting. In addition, we provide an impossibility result showing that it is in general not possible to achieve sub-exponential tails for SA with multiplicative noise. To establish these results, we develop a novel bootstrapping argument that involves bounding the moment generating function of the generalized Moreau envelope of the error and the construction of an exponential supermartingale to enable using Ville's maximal inequality. To demonstrate the applicability of our theoretical results, we use them to provide maximal concentration bounds for a large class of reinforcement learning algorithms, including but not limited to on-policy TD-learning with linear function approximation, off-policy TD-learning with generalized importance sampling factors, and $Q$-learning. To the best of our knowledge, super-polynomial concentration bounds for off-policy TD-learning have not been established in the literature due to the challenge of handling the combination of unbounded iterates and multiplicative noise.
Sample Complexity of Policy-Based Methods under Off-Policy Sampling and Linear Function Approximation
Aug 05, 2022In this work, we study policy-based methods for solving the reinforcement learning problem, where off-policy sampling and linear function approximation are employed for policy evaluation, and various policy update rules, including natural policy gradient (NPG), are considered for policy update. To solve the policy evaluation sub-problem in the presence of the deadly triad, we propose a generic algorithm framework of multi-step TD-learning with generalized importance sampling ratios, which includes two specific algorithms: the $\lambda$-averaged $Q$-trace and the two-sided $Q$-trace. The generic algorithm is single time-scale, has provable finite-sample guarantees, and overcomes the high variance issue in off-policy learning. As for the policy update, we provide a universal analysis using only the contraction property and the monotonicity property of the Bellman operator to establish the geometric convergence under various policy update rules. Importantly, by viewing NPG as an approximate way of implementing policy iteration, we establish the geometric convergence of NPG without introducing regularization, and without using mirror descent type of analysis as in existing literature. Combining the geometric convergence of the policy update with the finite-sample analysis of the policy evaluation, we establish for the first time an overall $\mathcal{O}(\epsilon^{-2})$ sample complexity for finding an optimal policy (up to a function approximation error) using policy-based methods under off-policy sampling and linear function approximation.