 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference-centric Bandits: Optimality of Mixtures and Regret-efficient Algorithms
Apr 30, 2025The objective of canonical multi-armed bandits is to identify and repeatedly select an arm with the largest reward, often in the form of the expected value of the arm's probability distribution. Such a utilitarian perspective and focus on the probability models' first moments, however, is agnostic to the distributions' tail behavior and their implications for variability and risks in decision-making. This paper introduces a principled framework for shifting from expectation-based evaluation to an alternative reward formulation, termed a preference metric (PM). The PMs can place the desired emphasis on different reward realization and can encode a richer modeling of preferences that incorporate risk aversion, robustness, or other desired attitudes toward uncertainty. A fundamentally distinct observation in such a PM-centric perspective is that designing bandit algorithms will have a significantly different principle: as opposed to the reward-based models in which the optimal sampling policy converges to repeatedly sampling from the single best arm, in the PM-centric framework the optimal policy converges to selecting a mix of arms based on specific mixing weights. Designing such mixture policies departs from the principles for designing bandit algorithms in significant ways, primarily because of uncountable mixture possibilities. The paper formalizes the PM-centric framework and presents two algorithm classes (horizon-dependent and anytime) that learn and track mixtures in a regret-efficient fashion. These algorithms have two distinctions from their canonical counterparts: (i) they involve an estimation routine to form reliable estimates of optimal mixtures, and (ii) they are equipped with tracking mechanisms to navigate arm selection fractions to track the optimal mixtures. These algorithms' regret guarantees are investigated under various algebraic forms of the PMs.
Risk-sensitive Bandits: Arm Mixture Optimality and Regret-efficient Algorithms
Mar 11, 2025This paper introduces a general framework for risk-sensitive bandits that integrates the notions of risk-sensitive objectives by adopting a rich class of distortion riskmetrics. The introduced framework subsumes the various existing risk-sensitive models. An important and hitherto unknown observation is that for a wide range of riskmetrics, the optimal bandit policy involves selecting a mixture of arms. This is in sharp contrast to the convention in the multi-arm bandit algorithms that there is generally a solitary arm that maximizes the utility, whether purely reward-centric or risk-sensitive. This creates a major departure from the principles for designing bandit algorithms since there are uncountable mixture possibilities. The contributions of the paper are as follows: (i) it formalizes a general framework for risk-sensitive bandits, (ii) identifies standard risk-sensitive bandit models for which solitary arm selections is not optimal, (iii) and designs regret-efficient algorithms whose sampling strategies can accurately track optimal arm mixtures (when mixture is optimal) or the solitary arms (when solitary is optimal). The algorithms are shown to achieve a regret that scales according to $O((\log T/T )^{\nu})$, where $T$ is the horizon, and $\nu>0$ is a riskmetric-specific constant.
Markov Chain Variance Estimation: A Stochastic Approximation Approach
Sep 09, 2024
We consider the problem of estimating the asymptotic variance of a function defined on a Markov chain, an important step for statistical inference of the stationary mean. We design the first recursive estimator that requires $O(1)$ computation at each step, does not require storing any historical samples or any prior knowledge of run-length, and has optimal $O(\frac{1}{n})$ rate of convergence for the mean-squared error (MSE) with provable finite sample guarantees. Here, $n$ refers to the total number of samples generated. The previously best-known rate of convergence in MSE was $O(\frac{\log n}{n})$, achieved by jackknifed estimators, which also do not enjoy these other desirable properties. Our estimator is based on linear stochastic approximation of an equivalent formulation of the asymptotic variance in terms of the solution of the Poisson equation. We generalize our estimator in several directions, including estimating the covariance matrix for vector-valued functions, estimating the stationary variance of a Markov chain, and approximately estimating the asymptotic variance in settings where the state space of the underlying Markov chain is large. We also show applications of our estimator in average reward reinforcement learning (RL), where we work with asymptotic variance as a risk measure to model safety-critical applications. We design a temporal-difference type algorithm tailored for policy evaluation in this context. We consider both the tabular and linear function approximation settings. Our work paves the way for developing actor-critic style algorithms for variance-constrained RL.
Optimization of utility-based shortfall risk: A non-asymptotic viewpoint
Oct 28, 2023We consider the problems of estimation and optimization of utility-based shortfall risk (UBSR), which is a popular risk measure in finance. In the context of UBSR estimation, we derive a non-asymptotic bound on the mean-squared error of the classical sample average approximation (SAA) of UBSR. Next, in the context of UBSR optimization, we derive an expression for the UBSR gradient under a smooth parameterization. This expression is a ratio of expectations, both of which involve the UBSR. We use SAA for the numerator as well as denominator in the UBSR gradient expression to arrive at a biased gradient estimator. We derive non-asymptotic bounds on the estimation error, which show that our gradient estimator is asymptotically unbiased. We incorporate the aforementioned gradient estimator into a stochastic gradient (SG) algorithm for UBSR optimization. Finally, we derive non-asymptotic bounds that quantify the rate of convergence of our SG algorithm for UBSR optimization.
VaR\ and CVaR Estimation in a Markov Cost Process: Lower and Upper Bounds
Oct 17, 2023We tackle the problem of estimating the Value-at-Risk (VaR) and the Conditional Value-at-Risk (CVaR) of the infinite-horizon discounted cost within a Markov cost process. First, we derive a minimax lower bound of $\Omega(1/\sqrt{n})$ that holds both in an expected and in a probabilistic sense. Then, using a finite-horizon truncation scheme, we derive an upper bound for the error in CVaR estimation, which matches our lower bound up to constant factors. Finally, we discuss an extension of our estimation scheme that covers more general risk measures satisfying a certain continuity criterion, e.g., spectral risk measures, utility-based shortfall risk. To the best of our knowledge, our work is the first to provide lower and upper bounds on the estimation error for any risk measure within Markovian settings. We remark that our lower bounds also extend to the infinite-horizon discounted costs' mean. Even in that case, our result $\Omega(1/\sqrt{n}) $ improves upon the existing result $\Omega(1/n)$[13].
A Cubic-regularized Policy Newton Algorithm for Reinforcement Learning
Apr 21, 2023We consider the problem of control in the setting of reinforcement learning (RL), where model information is not available. Policy gradient algorithms are a popular solution approach for this problem and are usually shown to converge to a stationary point of the value function. In this paper, we propose two policy Newton algorithms that incorporate cubic regularization. Both algorithms employ the likelihood ratio method to form estimates of the gradient and Hessian of the value function using sample trajectories. The first algorithm requires an exact solution of the cubic regularized problem in each iteration, while the second algorithm employs an efficient gradient descent-based approximation to the cubic regularized problem. We establish convergence of our proposed algorithms to a second-order stationary point (SOSP) of the value function, which results in the avoidance of traps in the form of saddle points. In particular, the sample complexity of our algorithms to find an $\epsilon$-SOSP is $O(\epsilon^{-3.5})$, which is an improvement over the state-of-the-art sample complexity of $O(\epsilon^{-4.5})$.
Finite time analysis of temporal difference learning with linear function approximation: Tail averaging and regularisation
Oct 12, 2022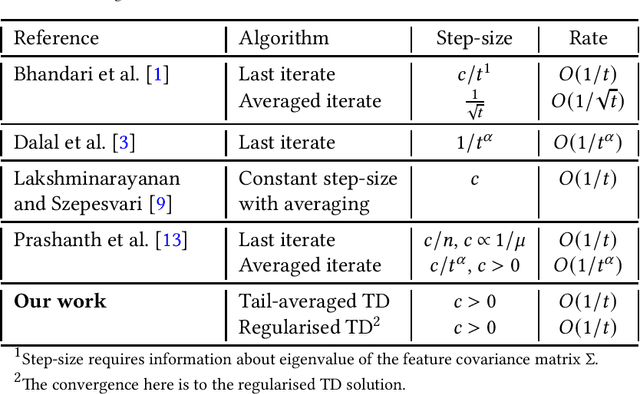

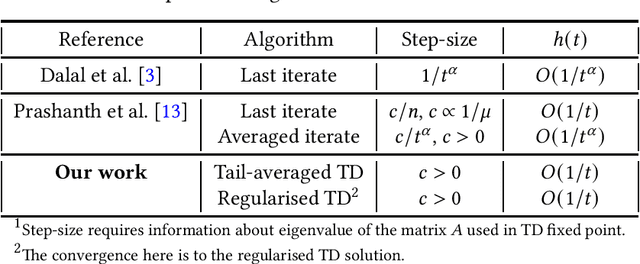
We study the finite-time behaviour of the popular temporal difference (TD) learning algorithm when combined with tail-averaging. We derive finite time bounds on the parameter error of the tail-averaged TD iterate under a step-size choice that does not require information about the eigenvalues of the matrix underlying the projected TD fixed point. Our analysis shows that tail-averaged TD converges at the optimal $O\left(1/t\right)$ rate, both in expectation and with high probability. In addition, our bounds exhibit a sharper rate of decay for the initial error (bias), which is an improvement over averaging all iterates. We also propose and analyse a variant of TD that incorporates regularisation. From analysis, we conclude that the regularised version of TD is useful for problems with ill-conditioned features.
A Gradient Smoothed Functional Algorithm with Truncated Cauchy Random Perturbations for Stochastic Optimization
Jul 30, 2022
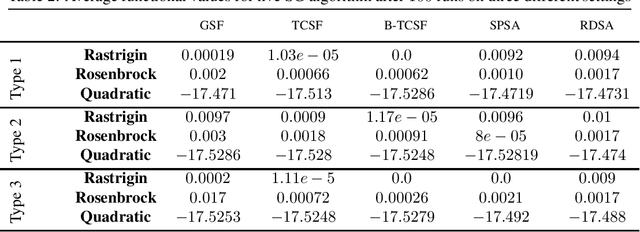
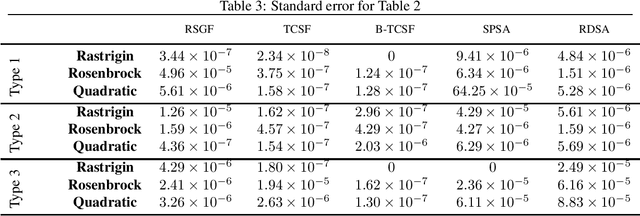
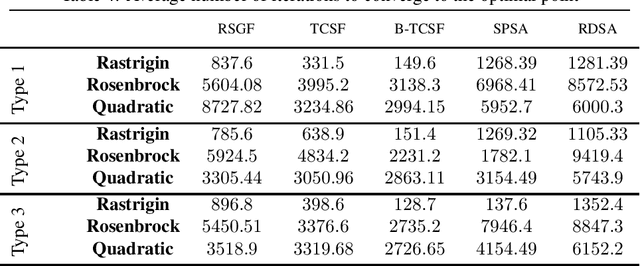
In this paper, we present a stochastic gradient algorithm for minimizing a smooth objective function that is an expectation over noisy cost samples and only the latter are observed for any given parameter. Our algorithm employs a gradient estimation scheme with random perturbations, which are formed using the truncated Cauchy distribution from the unit sphere. We analyze the bias and variance of the proposed gradient estimator. Our algorithm is found to be particularly useful in the case when the objective function is non-convex, and the parameter dimension is high. From an asymptotic convergence analysis, we establish that our algorithm converges almost surely to the set of stationary points of the objective function and obtain the asymptotic convergence rate. We also show that our algorithm avoids unstable equilibria, implying convergence to local minima. Further, we perform a non-asymptotic convergence analysis of our algorithm. In particular, we establish here a non-asymptotic bound for finding an $\epsilon$-stationary point of the non-convex objective function. Finally, we demonstrate numerically through simulations that the performance of our algorithm outperforms GSF, SPSA and RDSA by a significant margin over a few non-convex settings and further validate its performance over convex (noisy) objectives.
A Survey of Risk-Aware Multi-Armed Bandits
May 12, 2022In several applications such as clinical trials and financial portfolio optimization, the expected value (or the average reward) does not satisfactorily capture the merits of a drug or a portfolio. In such applications, risk plays a crucial role, and a risk-aware performance measure is preferable, so as to capture losses in the case of adverse events. This survey aims to consolidate and summarise the existing research on risk measures, specifically in the context of multi-armed bandits. We review various risk measures of interest, and comment on their properties. Next, we review existing concentration inequalities for various risk measures. Then, we proceed to defining risk-aware bandit problems, We consider algorithms for the regret minimization setting, where the exploration-exploitation trade-off manifests, as well as the best-arm identification setting, which is a pure exploration problem -- both in the context of risk-sensitive measures. We conclude by commenting on persisting challenges and fertile areas for future research.
Adaptive Estimation of Random Vectors with Bandit Feedback
Apr 01, 2022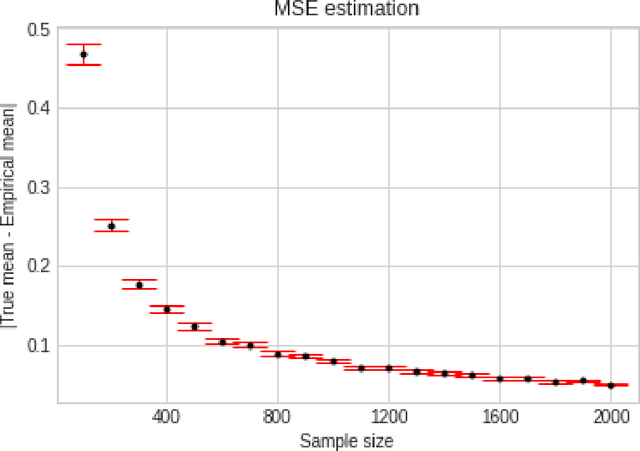
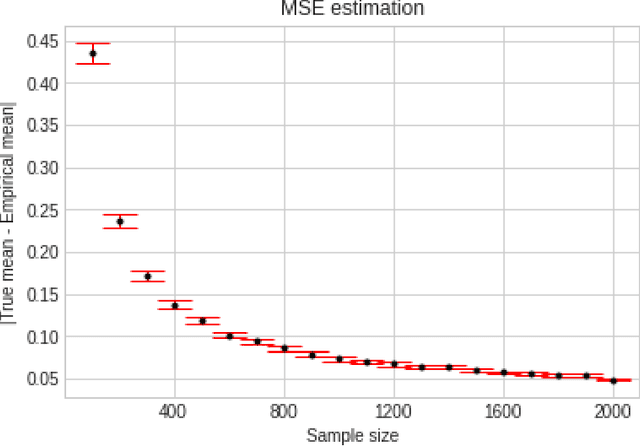
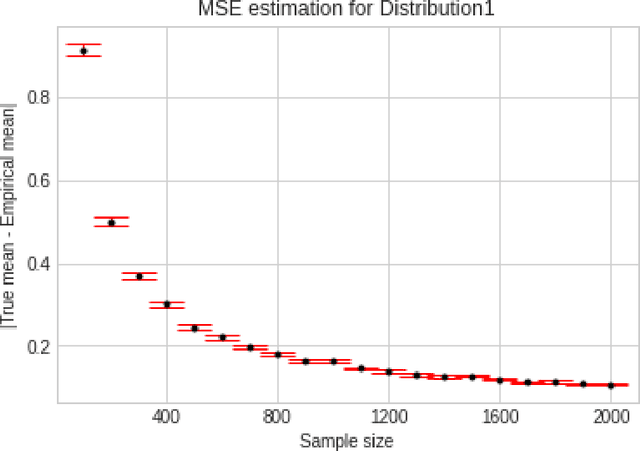
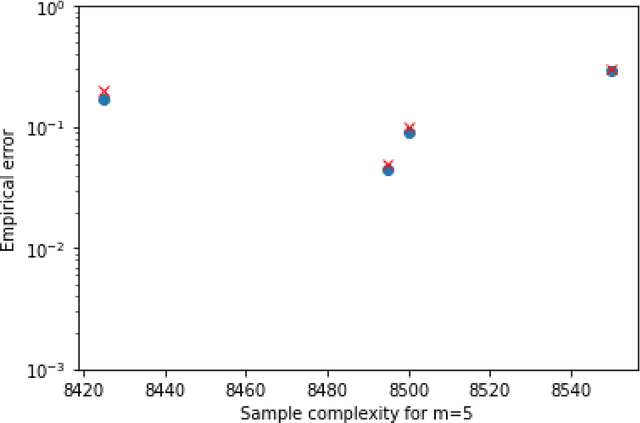
We consider the problem of sequentially learning to estimate, in the mean squared error (MSE) sense, a Gaussian $K$-vector of unknown covariance by observing only $m < K$ of its entries in each round. This reduces to learning an optimal subset for estimating the entire vector. Towards this, we first establish an exponential concentration bound for an estimate of the MSE for each observable subset. We then frame the estimation problem with bandit feedback in the best-subset identification setting. We propose a variant of the successive elimination algorithm to cater to the adaptive estimation problem, and we derive an upper bound on the sample complexity of this algorithm. In addition, to understand the fundamental limit on the sample complexity of this adaptive estimation bandit problem, we derive a minimax lower bound.