 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversary-Robust Learning from Fully Asynchronous Directional Derivative Estimates
May 10, 2026We propose FAR-SIGN (Fully Asynchronous Robust optimization via SIGNed directional projections) for adversary-resilient learning in parameter-server--worker systems. FAR-SIGN achieves robustness through sign-based updates along carefully designed directions and mitigates the resulting bias via a two-timescale mechanism. It admits both first-order and zeroth-order implementations and enables fully asynchronous execution without requiring a private reference dataset at the server. We establish almost-sure convergence of FAR-SIGN to the set of stationary points for smooth, nonconvex objectives. Moreover, we prove the near-optimal rate of $O(n^{-1/4+ε})$ in the first-order setting and the standard $O(n^{-1/6+ε})$ in the zeroth-order setting, where $n$ is the iteration count and $ε>0$ can be chosen arbitrarily small. Experiments on MNIST show that FAR-SIGN outperforms robust aggregation-based methods in both accuracy and wall-clock time.
Tight Convergence Rates for Online Distributed Linear Estimation with Adversarial Measurements
Apr 07, 2026We study mean estimation of a random vector $X$ in a distributed parameter-server-worker setup. Worker $i$ observes samples of $a_i^\top X$, where $a_i^\top$ is the $i$th row of a known sensing matrix $A$. The key challenges are adversarial measurements and asynchrony: a fixed subset of workers may transmit corrupted measurements, and workers are activated asynchronously--only one is active at any time. In our previous work, we proposed a two-timescale $\ell_1$-minimization algorithm and established asymptotic recovery under a null-space-property-like condition on $A$. In this work, we establish tight non-asymptotic convergence rates under the same null-space-property-like condition. We also identify relaxed conditions on $A$ under which exact recovery may fail but recovery of a projected component of $\mathbb{E}[X]$ remains possible. Overall, our results provide a unified finite-time characterization of robustness, identifiability, and statistical efficiency in distributed linear estimation with adversarial workers, with implications for network tomography and related distributed sensing problems.
Reliable Policy Iteration: Performance Robustness Across Architecture and Environment Perturbations
Dec 12, 2025In a recent work, we proposed Reliable Policy Iteration (RPI), that restores policy iteration's monotonicity-of-value-estimates property to the function approximation setting. Here, we assess the robustness of RPI's empirical performance on two classical control tasks -- CartPole and Inverted Pendulum -- under changes to neural network and environmental parameters. Relative to DQN, Double DQN, DDPG, TD3, and PPO, RPI reaches near-optimal performance early and sustains this policy as training proceeds. Because deep RL methods are often hampered by sample inefficiency, training instability, and hyperparameter sensitivity, our results highlight RPI's promise as a more reliable alternative.
Reliable Critics: Monotonic Improvement and Convergence Guarantees for Reinforcement Learning
Jun 08, 2025



Despite decades of research, it remains challenging to correctly use Reinforcement Learning (RL) algorithms with function approximation. A prime example is policy iteration, whose fundamental guarantee of monotonic improvement collapses even under linear function approximation. To address this issue, we introduce Reliable Policy Iteration (RPI). It replaces the common projection or Bellman-error minimization during policy evaluation with a Bellman-based constrained optimization. We prove that not only does RPI confer textbook monotonicity on its value estimates but these estimates also lower bound the true return. Also, their limit partially satisfies the unprojected Bellman equation, emphasizing RPI's natural fit within RL. RPI is the first algorithm with such monotonicity and convergence guarantees under function approximation. For practical use, we provide a model-free variant of RPI that amounts to a novel critic. It can be readily integrated into primary model-free PI implementations such as DQN and DDPG. In classical control tasks, such RPI-enhanced variants consistently maintain their lower-bound guarantee while matching or surpassing the performance of all baseline methods.
Reinforcement Learning with Quasi-Hyperbolic Discounting
Sep 16, 2024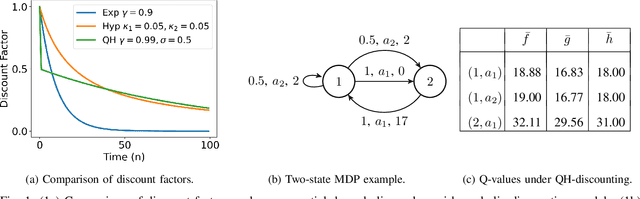
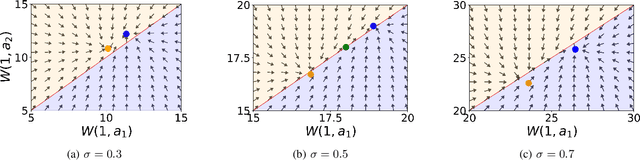
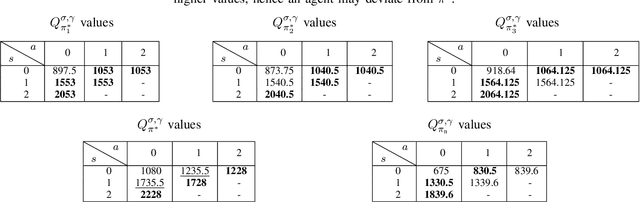
Reinforcement learning has traditionally been studied with exponential discounting or the average reward setup, mainly due to their mathematical tractability. However, such frameworks fall short of accurately capturing human behavior, which has a bias towards immediate gratification. Quasi-Hyperbolic (QH) discounting is a simple alternative for modeling this bias. Unlike in traditional discounting, though, the optimal QH-policy, starting from some time $t_1,$ can be different to the one starting from $t_2.$ Hence, the future self of an agent, if it is naive or impatient, can deviate from the policy that is optimal at the start, leading to sub-optimal overall returns. To prevent this behavior, an alternative is to work with a policy anchored in a Markov Perfect Equilibrium (MPE). In this work, we propose the first model-free algorithm for finding an MPE. Using a two-timescale analysis, we show that, if our algorithm converges, then the limit must be an MPE. We also validate this claim numerically for the standard inventory system with stochastic demands. Our work significantly advances the practical application of reinforcement learning.
Online Learning of Weakly Coupled MDP Policies for Load Balancing and Auto Scaling
Jun 20, 2024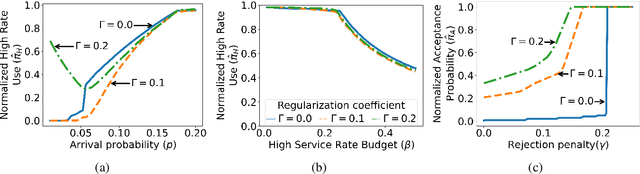
Load balancing and auto scaling are at the core of scalable, contemporary systems, addressing dynamic resource allocation and service rate adjustments in response to workload changes. This paper introduces a novel model and algorithms for tuning load balancers coupled with auto scalers, considering bursty traffic arriving at finite queues. We begin by presenting the problem as a weakly coupled Markov Decision Processes (MDP), solvable via a linear program (LP). However, as the number of control variables of such LP grows combinatorially, we introduce a more tractable relaxed LP formulation, and extend it to tackle the problem of online parameter learning and policy optimization using a two-timescale algorithm based on the LP Lagrangian.
Global Convergence Guarantees for Federated Policy Gradient Methods with Adversaries
Mar 15, 2024

Federated Reinforcement Learning (FRL) allows multiple agents to collaboratively build a decision making policy without sharing raw trajectories. However, if a small fraction of these agents are adversarial, it can lead to catastrophic results. We propose a policy gradient based approach that is robust to adversarial agents which can send arbitrary values to the server. Under this setting, our results form the first global convergence guarantees with general parametrization. These results demonstrate resilience with adversaries, while achieving sample complexity of order $\tilde{\mathcal{O}}\left( \frac{1}{\epsilon^2} \left( \frac{1}{N-f} + \frac{f^2}{(N-f)^2}\right)\right)$, where $N$ is the total number of agents and $f$ is the number of adversarial agents.
VaR\ and CVaR Estimation in a Markov Cost Process: Lower and Upper Bounds
Oct 17, 2023We tackle the problem of estimating the Value-at-Risk (VaR) and the Conditional Value-at-Risk (CVaR) of the infinite-horizon discounted cost within a Markov cost process. First, we derive a minimax lower bound of $\Omega(1/\sqrt{n})$ that holds both in an expected and in a probabilistic sense. Then, using a finite-horizon truncation scheme, we derive an upper bound for the error in CVaR estimation, which matches our lower bound up to constant factors. Finally, we discuss an extension of our estimation scheme that covers more general risk measures satisfying a certain continuity criterion, e.g., spectral risk measures, utility-based shortfall risk. To the best of our knowledge, our work is the first to provide lower and upper bounds on the estimation error for any risk measure within Markovian settings. We remark that our lower bounds also extend to the infinite-horizon discounted costs' mean. Even in that case, our result $\Omega(1/\sqrt{n}) $ improves upon the existing result $\Omega(1/n)$[13].
Online Learning with Adversaries: A Differential Inclusion Analysis
Apr 04, 2023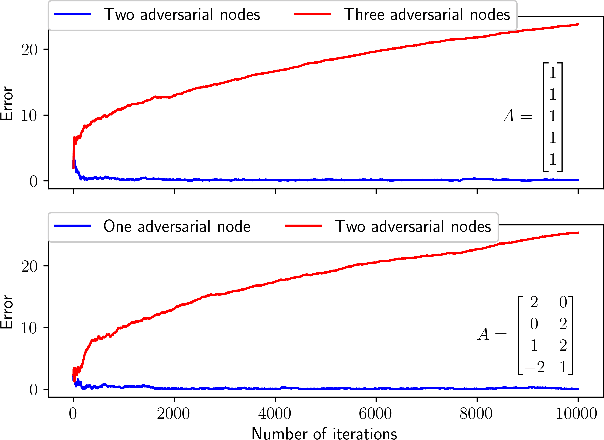
We consider the measurement model $Y = AX,$ where $X$ and, hence, $Y$ are random variables and $A$ is an a priori known tall matrix. At each time instance, a sample of one of $Y$'s coordinates is available, and the goal is to estimate $\mu := \mathbb{E}[X]$ via these samples. However, the challenge is that a small but unknown subset of $Y$'s coordinates are controlled by adversaries with infinite power: they can return any real number each time they are queried for a sample. For such an adversarial setting, we propose the first asynchronous online algorithm that converges to $\mu$ almost surely. We prove this result using a novel differential inclusion based two-timescale analysis. Two key highlights of our proof include: (a) the use of a novel Lyapunov function for showing that $\mu$ is the unique global attractor for our algorithm's limiting dynamics, and (b) the use of martingale and stopping time theory to show that our algorithm's iterates are almost surely bounded.
SoftTreeMax: Exponential Variance Reduction in Policy Gradient via Tree Search
Jan 30, 2023



Despite the popularity of policy gradient methods, they are known to suffer from large variance and high sample complexity. To mitigate this, we introduce SoftTreeMax -- a generalization of softmax that takes planning into account. In SoftTreeMax, we extend the traditional logits with the multi-step discounted cumulative reward, topped with the logits of future states. We consider two variants of SoftTreeMax, one for cumulative reward and one for exponentiated reward. For both, we analyze the gradient variance and reveal for the first time the role of a tree expansion policy in mitigating this variance. We prove that the resulting variance decays exponentially with the planning horizon as a function of the expansion policy. Specifically, we show that the closer the resulting state transitions are to uniform, the faster the decay. In a practical implementation, we utilize a parallelized GPU-based simulator for fast and efficient tree search. Our differentiable tree-based policy leverages all gradients at the tree leaves in each environment step instead of the traditional single-sample-based gradient. We then show in simulation how the variance of the gradient is reduced by three orders of magnitude, leading to better sample complexity compared to the standard policy gradient. On Atari, SoftTreeMax demonstrates up to 5x better performance in a faster run time compared to distributed PPO. Lastly, we demonstrate that high reward correlates with lower variance.