 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Quasi-Hyperbolic Discounting
Sep 16, 2024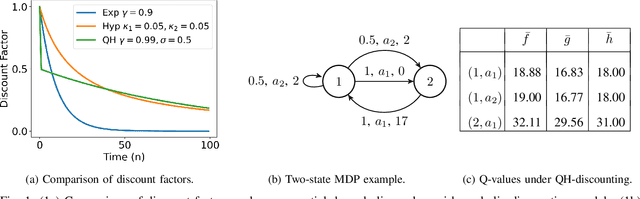
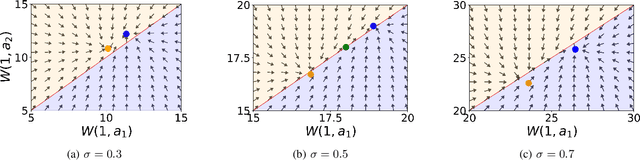
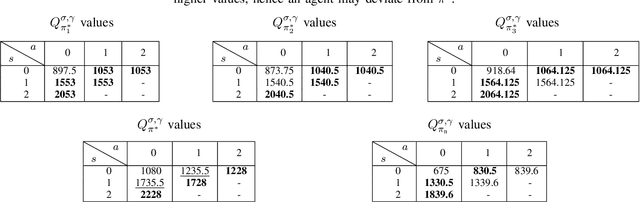
Reinforcement learning has traditionally been studied with exponential discounting or the average reward setup, mainly due to their mathematical tractability. However, such frameworks fall short of accurately capturing human behavior, which has a bias towards immediate gratification. Quasi-Hyperbolic (QH) discounting is a simple alternative for modeling this bias. Unlike in traditional discounting, though, the optimal QH-policy, starting from some time $t_1,$ can be different to the one starting from $t_2.$ Hence, the future self of an agent, if it is naive or impatient, can deviate from the policy that is optimal at the start, leading to sub-optimal overall returns. To prevent this behavior, an alternative is to work with a policy anchored in a Markov Perfect Equilibrium (MPE). In this work, we propose the first model-free algorithm for finding an MPE. Using a two-timescale analysis, we show that, if our algorithm converges, then the limit must be an MPE. We also validate this claim numerically for the standard inventory system with stochastic demands. Our work significantly advances the practical application of reinforcement learning.