 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Test-Time Compute Can Hurt: Overestimation Bias in LLM Beam Search
Mar 17, 2026Wider beam search should improve LLM reasoning, but when should you stop widening? Prior work on beam width selection has focused on inference efficiency \citep{qin2025dsbd, freitag2017beam}, without analyzing whether wider search can \emph{hurt} output quality. We present an analysis, grounded in Extreme Value Theory, that answers this question. Beam selection over noisy scorer outputs introduces a systematic overestimation bias that grows with the candidate pool size, and we derive a maximum useful beam width $\hat{k}$ beyond which search degrades performance. This critical width depends on the signal-to-noise ratio of the scorer: $\hat{k}$ grows exponentially with $(Δ/σ)^2$, where $Δ> 0$ is the quality advantage of correct paths over incorrect ones and $σ$ is the scorer noise. We validate this theory by comparing perplexity-guided and PRM-guided beam search across three 7B-parameter models and ten domains on MR-BEN (5,975 questions). Perplexity scoring, with its high noise, yields $\hat{k} = 1$: search provides no benefit at any width tested. PRM scoring, with lower noise, yields $\hat{k} \geq 4$, with gains of up to 8.9 percentage points. The same model, the same algorithm, but different scorers place $\hat{k}$ at opposite ends of the beam width range. Our analysis identifies the scorer's signal-to-noise ratio as the key quantity governing beam width selection, and we propose diagnostic indicators for choosing the beam width in practice.
Who Said Neural Networks Aren't Linear?
Oct 09, 2025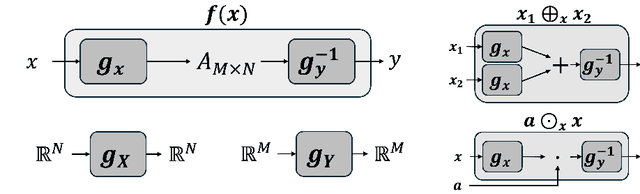



Neural networks are famously nonlinear. However, linearity is defined relative to a pair of vector spaces, $f$$:$$X$$\to$$Y$. Is it possible to identify a pair of non-standard vector spaces for which a conventionally nonlinear function is, in fact, linear? This paper introduces a method that makes such vector spaces explicit by construction. We find that if we sandwich a linear operator $A$ between two invertible neural networks, $f(x)=g_y^{-1}(A g_x(x))$, then the corresponding vector spaces $X$ and $Y$ are induced by newly defined addition and scaling actions derived from $g_x$ and $g_y$. We term this kind of architecture a Linearizer. This framework makes the entire arsenal of linear algebra, including SVD, pseudo-inverse, orthogonal projection and more, applicable to nonlinear mappings. Furthermore, we show that the composition of two Linearizers that share a neural network is also a Linearizer. We leverage this property and demonstrate that training diffusion models using our architecture makes the hundreds of sampling steps collapse into a single step. We further utilize our framework to enforce idempotency (i.e. $f(f(x))=f(x)$) on networks leading to a globally projective generative model and to demonstrate modular style transfer.
Towards Large Language Models with Self-Consistent Natural Language Explanations
Jun 09, 2025Large language models (LLMs) seem to offer an easy path to interpretability: just ask them to explain their decisions. Yet, studies show that these post-hoc explanations often misrepresent the true decision process, as revealed by mismatches in feature importance. Despite growing evidence of this inconsistency, no systematic solutions have emerged, partly due to the high cost of estimating feature importance, which limits evaluations to small datasets. To address this, we introduce the Post-hoc Self-Consistency Bank (PSCB) - a large-scale benchmark of decisions spanning diverse tasks and models, each paired with LLM-generated explanations and corresponding feature importance scores. Analysis of PSCB reveals that self-consistency scores barely differ between correct and incorrect predictions. We also show that the standard metric fails to meaningfully distinguish between explanations. To overcome this limitation, we propose an alternative metric that more effectively captures variation in explanation quality. We use it to fine-tune LLMs via Direct Preference Optimization (DPO), leading to significantly better alignment between explanations and decision-relevant features, even under domain shift. Our findings point to a scalable path toward more trustworthy, self-consistent LLMs.
"You just can't go around killing people" Explaining Agent Behavior to a Human Terminator
Apr 06, 2025

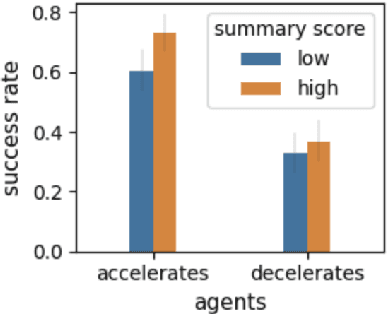
Consider a setting where a pre-trained agent is operating in an environment and a human operator can decide to temporarily terminate its operation and take-over for some duration of time. These kind of scenarios are common in human-machine interactions, for example in autonomous driving, factory automation and healthcare. In these settings, we typically observe a trade-off between two extreme cases -- if no take-overs are allowed, then the agent might employ a sub-optimal, possibly dangerous policy. Alternatively, if there are too many take-overs, then the human has no confidence in the agent, greatly limiting its usefulness. In this paper, we formalize this setup and propose an explainability scheme to help optimize the number of human interventions.
RL-RC-DoT: A Block-level RL agent for Task-Aware Video Compression
Jan 21, 2025Video encoders optimize compression for human perception by minimizing reconstruction error under bit-rate constraints. In many modern applications such as autonomous driving, an overwhelming majority of videos serve as input for AI systems performing tasks like object recognition or segmentation, rather than being watched by humans. It is therefore useful to optimize the encoder for a downstream task instead of for perceptual image quality. However, a major challenge is how to combine such downstream optimization with existing standard video encoders, which are highly efficient and popular. Here, we address this challenge by controlling the Quantization Parameters (QPs) at the macro-block level to optimize the downstream task. This granular control allows us to prioritize encoding for task-relevant regions within each frame. We formulate this optimization problem as a Reinforcement Learning (RL) task, where the agent learns to balance long-term implications of choosing QPs on both task performance and bit-rate constraints. Notably, our policy does not require the downstream task as an input during inference, making it suitable for streaming applications and edge devices such as vehicles. We demonstrate significant improvements in two tasks, car detection, and ROI (saliency) encoding. Our approach improves task performance for a given bit rate compared to traditional task agnostic encoding methods, paving the way for more efficient task-aware video compression.
PlaMo: Plan and Move in Rich 3D Physical Environments
Jun 26, 2024Controlling humanoids in complex physically simulated worlds is a long-standing challenge with numerous applications in gaming, simulation, and visual content creation. In our setup, given a rich and complex 3D scene, the user provides a list of instructions composed of target locations and locomotion types. To solve this task we present PlaMo, a scene-aware path planner and a robust physics-based controller. The path planner produces a sequence of motion paths, considering the various limitations the scene imposes on the motion, such as location, height, and speed. Complementing the planner, our control policy generates rich and realistic physical motion adhering to the plan. We demonstrate how the combination of both modules enables traversing complex landscapes in diverse forms while responding to real-time changes in the environment. Video: https://youtu.be/wWlqSQlRZ9M .
SoftTreeMax: Exponential Variance Reduction in Policy Gradient via Tree Search
Jan 30, 2023



Despite the popularity of policy gradient methods, they are known to suffer from large variance and high sample complexity. To mitigate this, we introduce SoftTreeMax -- a generalization of softmax that takes planning into account. In SoftTreeMax, we extend the traditional logits with the multi-step discounted cumulative reward, topped with the logits of future states. We consider two variants of SoftTreeMax, one for cumulative reward and one for exponentiated reward. For both, we analyze the gradient variance and reveal for the first time the role of a tree expansion policy in mitigating this variance. We prove that the resulting variance decays exponentially with the planning horizon as a function of the expansion policy. Specifically, we show that the closer the resulting state transitions are to uniform, the faster the decay. In a practical implementation, we utilize a parallelized GPU-based simulator for fast and efficient tree search. Our differentiable tree-based policy leverages all gradients at the tree leaves in each environment step instead of the traditional single-sample-based gradient. We then show in simulation how the variance of the gradient is reduced by three orders of magnitude, leading to better sample complexity compared to the standard policy gradient. On Atari, SoftTreeMax demonstrates up to 5x better performance in a faster run time compared to distributed PPO. Lastly, we demonstrate that high reward correlates with lower variance.
SoftTreeMax: Policy Gradient with Tree Search
Sep 28, 2022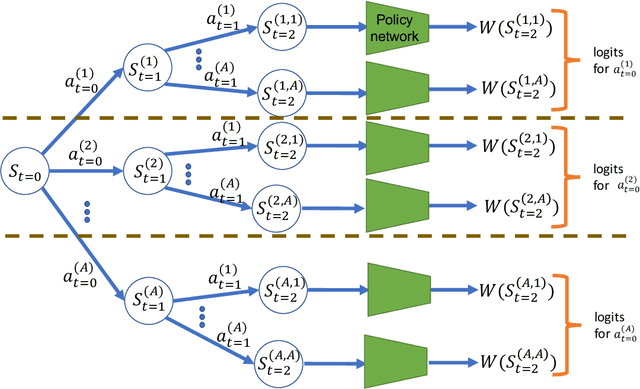
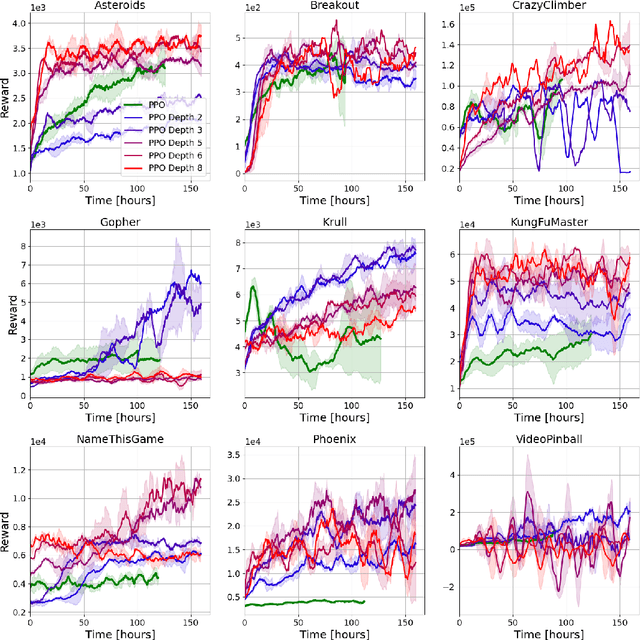
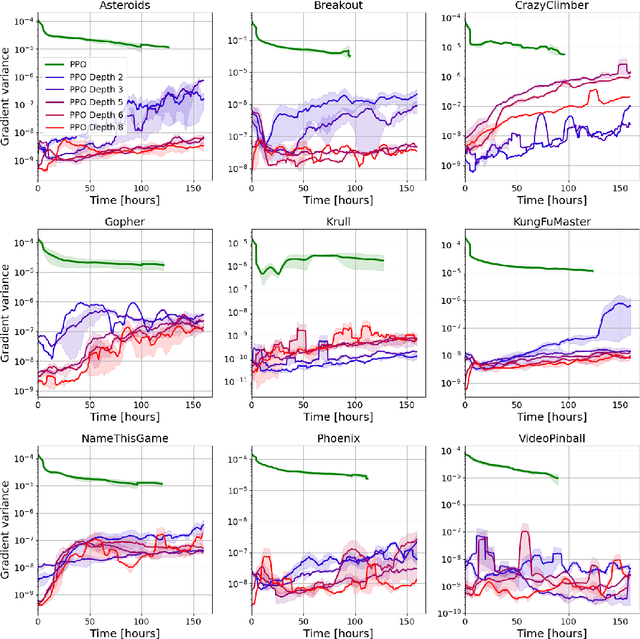
Policy-gradient methods are widely used for learning control policies. They can be easily distributed to multiple workers and reach state-of-the-art results in many domains. Unfortunately, they exhibit large variance and subsequently suffer from high-sample complexity since they aggregate gradients over entire trajectories. At the other extreme, planning methods, like tree search, optimize the policy using single-step transitions that consider future lookahead. These approaches have been mainly considered for value-based algorithms. Planning-based algorithms require a forward model and are computationally intensive at each step, but are more sample efficient. In this work, we introduce SoftTreeMax, the first approach that integrates tree-search into policy gradient. Traditionally, gradients are computed for single state-action pairs. Instead, our tree-based policy structure leverages all gradients at the tree leaves in each environment step. This allows us to reduce the variance of gradients by three orders of magnitude and to benefit from better sample complexity compared with standard policy gradient. On Atari, SoftTreeMax demonstrates up to 5x better performance in faster run-time compared with distributed PPO.
Reinforcement Learning with a Terminator
May 30, 2022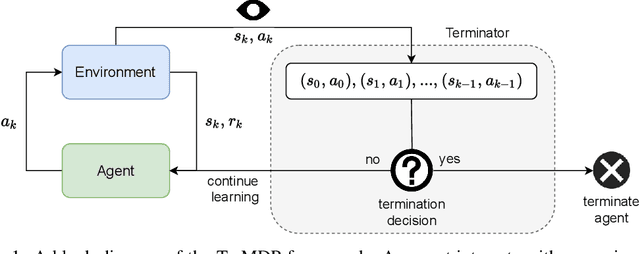
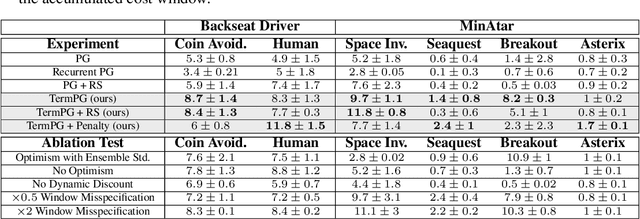
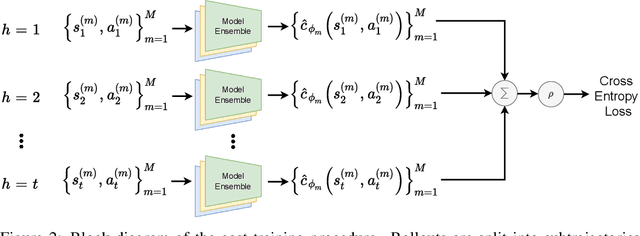
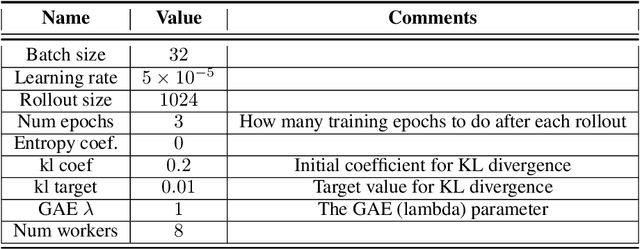
We present the problem of reinforcement learning with exogenous termination. We define the Termination Markov Decision Process (TerMDP), an extension of the MDP framework, in which episodes may be interrupted by an external non-Markovian observer. This formulation accounts for numerous real-world situations, such as a human interrupting an autonomous driving agent for reasons of discomfort. We learn the parameters of the TerMDP and leverage the structure of the estimation problem to provide state-wise confidence bounds. We use these to construct a provably-efficient algorithm, which accounts for termination, and bound its regret. Motivated by our theoretical analysis, we design and implement a scalable approach, which combines optimism (w.r.t. termination) and a dynamic discount factor, incorporating the termination probability. We deploy our method on high-dimensional driving and MinAtar benchmarks. Additionally, we test our approach on human data in a driving setting. Our results demonstrate fast convergence and significant improvement over various baseline approaches.
Planning and Learning with Adaptive Lookahead
Jan 28, 2022



The classical Policy Iteration (PI) algorithm alternates between greedy one-step policy improvement and policy evaluation. Recent literature shows that multi-step lookahead policy improvement leads to a better convergence rate at the expense of increased complexity per iteration. However, prior to running the algorithm, one cannot tell what is the best fixed lookahead horizon. Moreover, per a given run, using a lookahead of horizon larger than one is often wasteful. In this work, we propose for the first time to dynamically adapt the multi-step lookahead horizon as a function of the state and of the value estimate. We devise two PI variants and analyze the trade-off between iteration count and computational complexity per iteration. The first variant takes the desired contraction factor as the objective and minimizes the per-iteration complexity. The second variant takes as input the computational complexity per iteration and minimizes the overall contraction factor. We then devise a corresponding DQN-based algorithm with an adaptive tree search horizon. We also include a novel enhancement for on-policy learning: per-depth value function estimator. Lastly, we demonstrate the efficacy of our adaptive lookahead method in a maze environment and in Atari.