 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArctyrEX : Accelerated Encrypted Execution of General-Purpose Applications
Jun 19, 2023



Fully Homomorphic Encryption (FHE) is a cryptographic method that guarantees the privacy and security of user data during computation. FHE algorithms can perform unlimited arithmetic computations directly on encrypted data without decrypting it. Thus, even when processed by untrusted systems, confidential data is never exposed. In this work, we develop new techniques for accelerated encrypted execution and demonstrate the significant performance advantages of our approach. Our current focus is the Fully Homomorphic Encryption over the Torus (CGGI) scheme, which is a current state-of-the-art method for evaluating arbitrary functions in the encrypted domain. CGGI represents a computation as a graph of homomorphic logic gates and each individual bit of the plaintext is transformed into a polynomial in the encrypted domain. Arithmetic on such data becomes very expensive: operations on bits become operations on entire polynomials. Therefore, evaluating even relatively simple nonlinear functions, such as a sigmoid, can take thousands of seconds on a single CPU thread. Using our novel framework for end-to-end accelerated encrypted execution called ArctyrEX, developers with no knowledge of complex FHE libraries can simply describe their computation as a C program that is evaluated over $40\times$ faster on an NVIDIA DGX A100 and $6\times$ faster with a single A100 relative to a 256-threaded CPU baseline.
Improve Agents without Retraining: Parallel Tree Search with Off-Policy Correction
Jul 04, 2021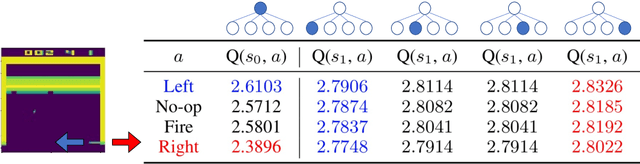
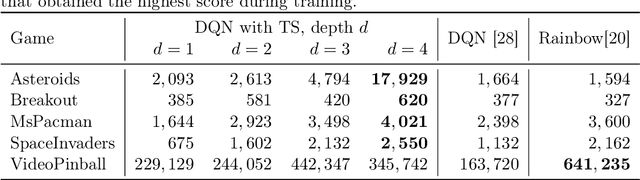
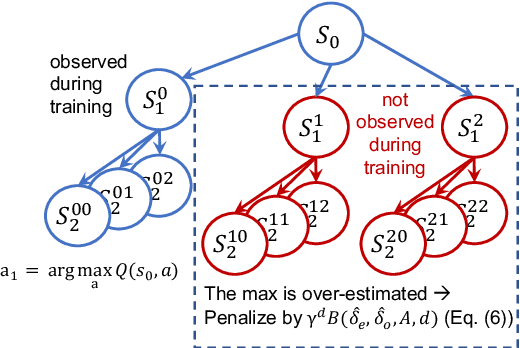
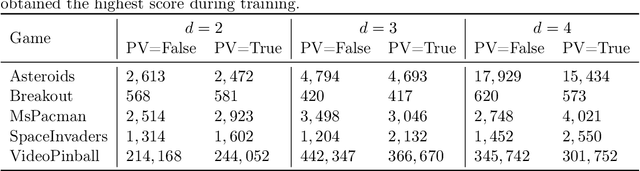
Tree Search (TS) is crucial to some of the most influential successes in reinforcement learning. Here, we tackle two major challenges with TS that limit its usability: \textit{distribution shift} and \textit{scalability}. We first discover and analyze a counter-intuitive phenomenon: action selection through TS and a pre-trained value function often leads to lower performance compared to the original pre-trained agent, even when having access to the exact state and reward in future steps. We show this is due to a distribution shift to areas where value estimates are highly inaccurate and analyze this effect using Extreme Value theory. To overcome this problem, we introduce a novel off-policy correction term that accounts for the mismatch between the pre-trained value and its corresponding TS policy by penalizing under-sampled trajectories. We prove that our correction eliminates the above mismatch and bound the probability of sub-optimal action selection. Our correction significantly improves pre-trained Rainbow agents without any further training, often more than doubling their scores on Atari games. Next, we address the scalability issue given by the computational complexity of exhaustive TS that scales exponentially with the tree depth. We introduce Batch-BFS: a GPU breadth-first search that advances all nodes in each depth of the tree simultaneously. Batch-BFS reduces runtime by two orders of magnitude and, beyond inference, enables also training with TS of depths that were not feasible before. We train DQN agents from scratch using TS and show improvement in several Atari games compared to both the original DQN and the more advanced Rainbow.
GPU-Accelerated Atari Emulation for Reinforcement Learning
Jul 19, 2019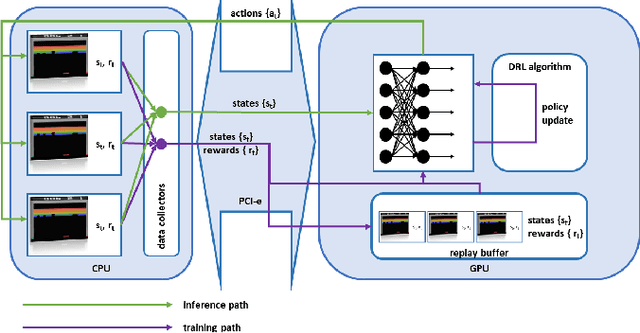
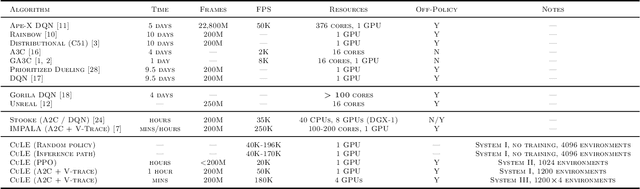

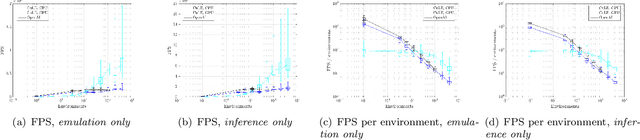
We designed and implemented a CUDA port of the Atari Learning Environment (ALE), a system for developing and evaluating deep reinforcement algorithms using Atari games. Our CUDA Learning Environment (CuLE) overcomes many limitations of existing CPU-based Atari emulators and scales naturally to multi-GPU systems. It leverages the parallelization capability of GPUs to run thousands of Atari games simultaneously; by rendering frames directly on the GPU, CuLE avoids the bottleneck arising from the limited CPU-GPU communication bandwidth. As a result, CuLE is able to generate between 40M and 190M frames per hour using a single GPU, a finding that could be previously achieved only through a cluster of CPUs. We demonstrate the advantages of CuLE by effectively training agents with traditional deep reinforcement learning algorithms and measuring the utilization and throughput of the GPU. Our analysis further highlights the differences in the data generation pattern for emulators running on CPUs or GPUs. CuLE is available at https://github.com/NVLabs/cule .