 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Software Pipelining and Warp Specialization for Tensor Core GPUs
Dec 19, 2025


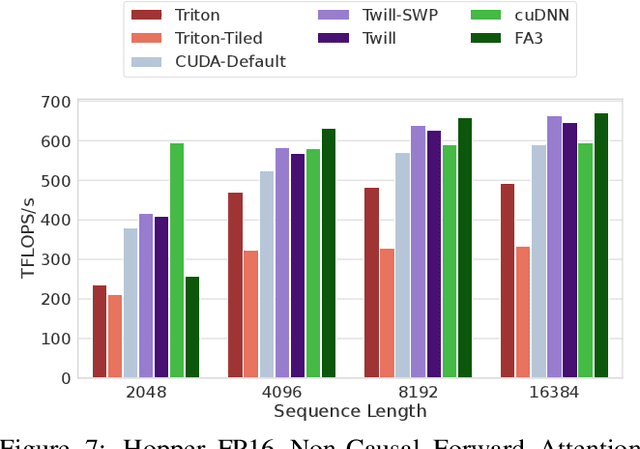
GPU architectures have continued to grow in complexity, with recent incarnations introducing increasingly powerful fixed-function units for matrix multiplication and data movement to accompany highly parallel general-purpose cores. To fully leverage these machines, software must use sophisticated schedules that maximally utilize all hardware resources. Since realizing such schedules is complex, both programmers and compilers routinely employ program transformations, such as software pipelining (SWP) and warp specialization (WS), to do so in practice. However, determining how best to use SWP and WS in combination is a challenging problem that is currently handled through a mix of brittle compilation heuristics and fallible human intuition, with little insight into the space of solutions. To remedy this situation, we introduce a novel formulation of SWP and WS as a joint optimization problem that can be solved holistically by off-the-shelf constraint solvers. We reify our approach in Twill, the first system that automatically derives optimal SWP and WS schedules for a large class of iterative programs. Twill is heuristic-free, easily extensible to new GPU architectures, and guaranteed to produce optimal schedules. We show that Twill can rediscover, and thereby prove optimal, the SWP and WS schedules manually developed by experts for Flash Attention on both the NVIDIA Hopper and Blackwell GPU architectures.
Understanding the Effect of the Long Tail on Neural Network Compression
Jun 27, 2023Network compression is now a mature sub-field of neural network research: over the last decade, significant progress has been made towards reducing the size of models and speeding up inference, while maintaining the classification accuracy. However, many works have observed that focusing on just the overall accuracy can be misguided. E.g., it has been shown that mismatches between the full and compressed models can be biased towards under-represented classes. This raises the important research question, can we achieve network compression while maintaining "semantic equivalence" with the original network? In this work, we study this question in the context of the "long tail" phenomenon in computer vision datasets observed by Feldman, et al. They argue that memorization of certain inputs (appropriately defined) is essential to achieving good generalization. As compression limits the capacity of a network (and hence also its ability to memorize), we study the question: are mismatches between the full and compressed models correlated with the memorized training data? We present positive evidence in this direction for image classification tasks, by considering different base architectures and compression schemes.
ArctyrEX : Accelerated Encrypted Execution of General-Purpose Applications
Jun 19, 2023



Fully Homomorphic Encryption (FHE) is a cryptographic method that guarantees the privacy and security of user data during computation. FHE algorithms can perform unlimited arithmetic computations directly on encrypted data without decrypting it. Thus, even when processed by untrusted systems, confidential data is never exposed. In this work, we develop new techniques for accelerated encrypted execution and demonstrate the significant performance advantages of our approach. Our current focus is the Fully Homomorphic Encryption over the Torus (CGGI) scheme, which is a current state-of-the-art method for evaluating arbitrary functions in the encrypted domain. CGGI represents a computation as a graph of homomorphic logic gates and each individual bit of the plaintext is transformed into a polynomial in the encrypted domain. Arithmetic on such data becomes very expensive: operations on bits become operations on entire polynomials. Therefore, evaluating even relatively simple nonlinear functions, such as a sigmoid, can take thousands of seconds on a single CPU thread. Using our novel framework for end-to-end accelerated encrypted execution called ArctyrEX, developers with no knowledge of complex FHE libraries can simply describe their computation as a C program that is evaluated over $40\times$ faster on an NVIDIA DGX A100 and $6\times$ faster with a single A100 relative to a 256-threaded CPU baseline.
Efficient Sparsely Activated Transformers
Aug 31, 2022
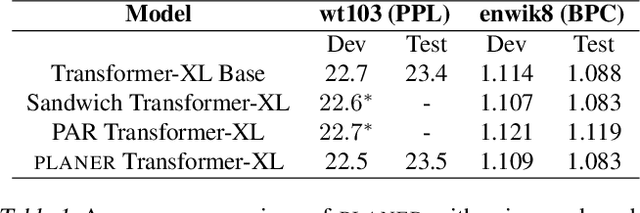
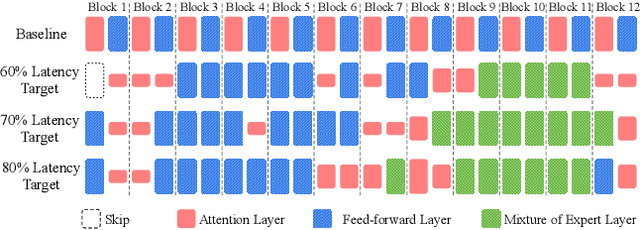
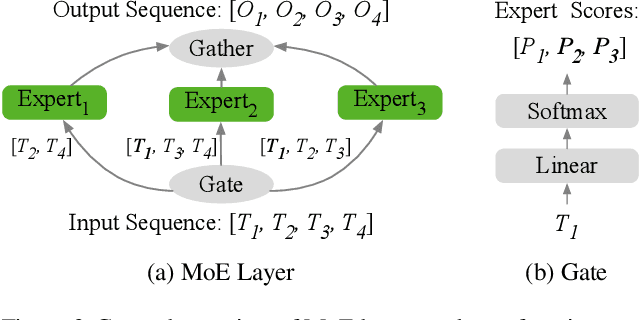
Transformer-based neural networks have achieved state-of-the-art task performance in a number of machine learning domains including natural language processing and computer vision. To further improve their accuracy, recent work has explored the integration of dynamic behavior into these networks in the form of mixture-of-expert (MoE) layers. In this paper, we explore the introduction of MoE layers to optimize a different metric: inference latency. We introduce a novel system named PLANER that takes an existing Transformer-based network and a user-defined latency target and produces an optimized, sparsely-activated version of the original network that tries to meet the latency target while maintaining baseline accuracy. We evaluate PLANER on two real-world language modeling tasks using the Transformer-XL network and achieve inference latency reductions of over 2x at iso-accuracy.
Reliable Model Compression via Label-Preservation-Aware Loss Functions
Dec 03, 2020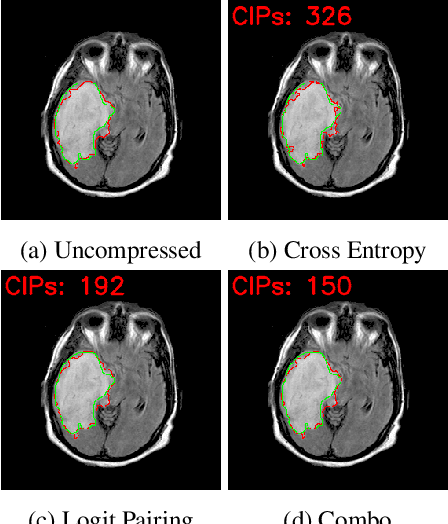
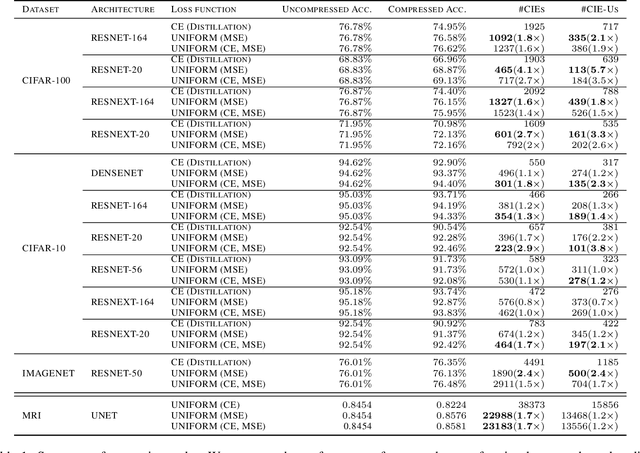
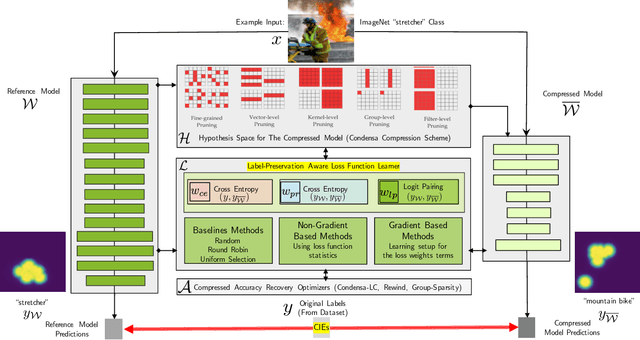
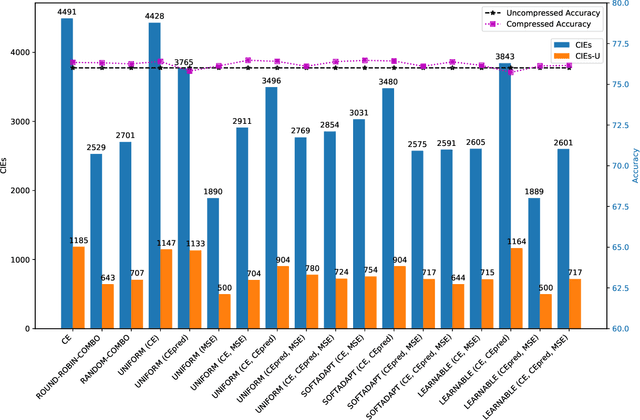
Model compression is a ubiquitous tool that brings the power of modern deep learning to edge devices with power and latency constraints. The goal of model compression is to take a large reference neural network and output a smaller and less expensive compressed network that is functionally equivalent to the reference. Compression typically involves pruning and/or quantization, followed by re-training to maintain the reference accuracy. However, it has been observed that compression can lead to a considerable mismatch in the labels produced by the reference and the compressed models, resulting in bias and unreliability. To combat this, we present a framework that uses a teacher-student learning paradigm to better preserve labels. We investigate the role of additional terms to the loss function and show how to automatically tune the associated parameters. We demonstrate the effectiveness of our approach both quantitatively and qualitatively on multiple compression schemes and accuracy recovery algorithms using a set of 8 different real-world network architectures. We obtain a significant reduction of up to 4.1X in the number of mismatches between the compressed and reference models, and up to 5.7X in cases where the reference model makes the correct prediction.
A Programmable Approach to Model Compression
Nov 06, 2019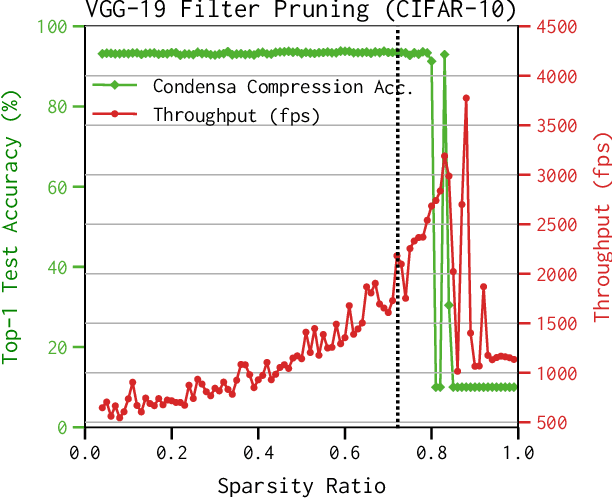

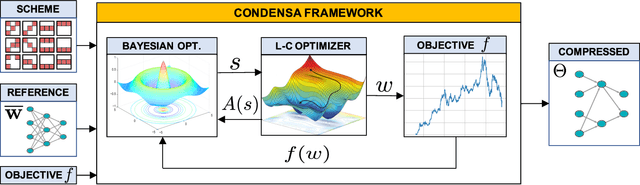
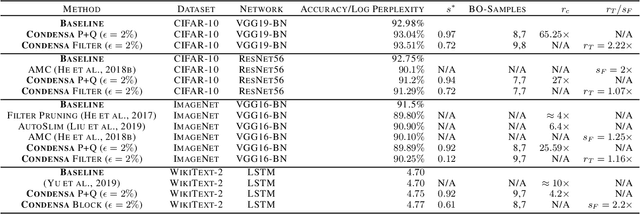
Deep neural networks frequently contain far more weights, represented at a higher precision, than are required for the specific task which they are trained to perform. Consequently, they can often be compressed using techniques such as weight pruning and quantization that reduce both model size and inference time without appreciable loss in accuracy. Compressing models before they are deployed can therefore result in significantly more efficient systems. However, while the results are desirable, finding the best compression strategy for a given neural network, target platform, and optimization objective often requires extensive experimentation. Moreover, finding optimal hyperparameters for a given compression strategy typically results in even more expensive, frequently manual, trial-and-error exploration. In this paper, we introduce a programmable system for model compression called Condensa. Users programmatically compose simple operators, in Python, to build complex compression strategies. Given a strategy and a user-provided objective, such as minimization of running time, Condensa uses a novel sample-efficient constrained Bayesian optimization algorithm to automatically infer desirable sparsity ratios. Our experiments on three real-world image classification and language modeling tasks demonstrate memory footprint reductions of up to 65x and runtime throughput improvements of up to 2.22x using at most 10 samples per search. We have released a reference implementation of Condensa at https://github.com/NVlabs/condensa.
GPU-Accelerated Atari Emulation for Reinforcement Learning
Jul 19, 2019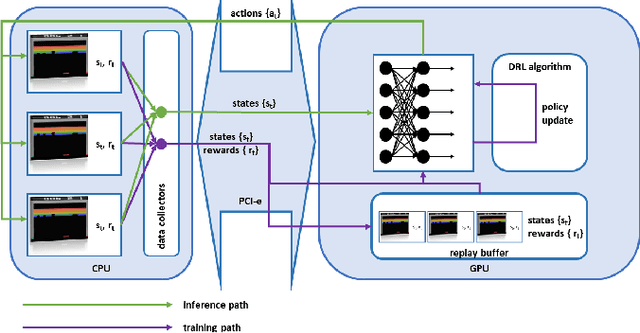
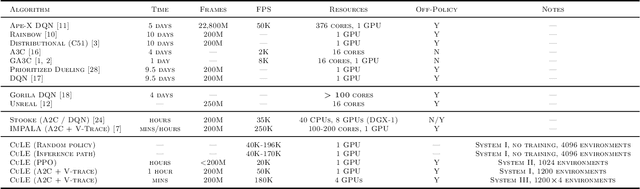

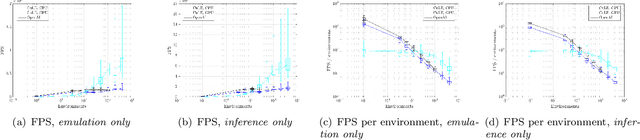
We designed and implemented a CUDA port of the Atari Learning Environment (ALE), a system for developing and evaluating deep reinforcement algorithms using Atari games. Our CUDA Learning Environment (CuLE) overcomes many limitations of existing CPU-based Atari emulators and scales naturally to multi-GPU systems. It leverages the parallelization capability of GPUs to run thousands of Atari games simultaneously; by rendering frames directly on the GPU, CuLE avoids the bottleneck arising from the limited CPU-GPU communication bandwidth. As a result, CuLE is able to generate between 40M and 190M frames per hour using a single GPU, a finding that could be previously achieved only through a cluster of CPUs. We demonstrate the advantages of CuLE by effectively training agents with traditional deep reinforcement learning algorithms and measuring the utilization and throughput of the GPU. Our analysis further highlights the differences in the data generation pattern for emulators running on CPUs or GPUs. CuLE is available at https://github.com/NVLabs/cule .
AdaBatch: Adaptive Batch Sizes for Training Deep Neural Networks
Feb 14, 2018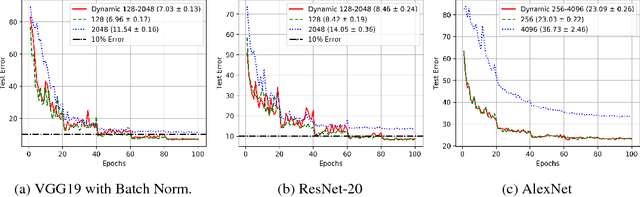

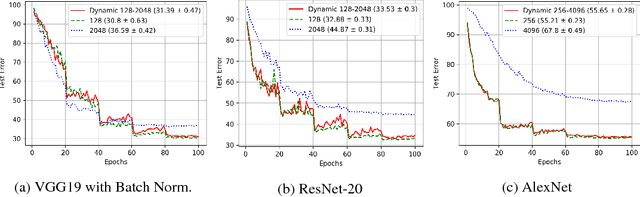

Training deep neural networks with Stochastic Gradient Descent, or its variants, requires careful choice of both learning rate and batch size. While smaller batch sizes generally converge in fewer training epochs, larger batch sizes offer more parallelism and hence better computational efficiency. We have developed a new training approach that, rather than statically choosing a single batch size for all epochs, adaptively increases the batch size during the training process. Our method delivers the convergence rate of small batch sizes while achieving performance similar to large batch sizes. We analyse our approach using the standard AlexNet, ResNet, and VGG networks operating on the popular CIFAR-10, CIFAR-100, and ImageNet datasets. Our results demonstrate that learning with adaptive batch sizes can improve performance by factors of up to 6.25 on 4 NVIDIA Tesla P100 GPUs while changing accuracy by less than 1% relative to training with fixed batch sizes.