 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerailing Non-Answers via Logit Suppression at Output Subspace Boundaries in RLHF-Aligned Language Models
May 28, 2025We introduce a method to reduce refusal rates of large language models (LLMs) on sensitive content without modifying model weights or prompts. Motivated by the observation that refusals in certain models were often preceded by the specific token sequence of a token marking the beginning of the chain-of-thought (CoT) block (<think>) followed by a double newline token (\n\n), we investigate the impact of two simple formatting adjustments during generation: suppressing \n\n after <think> and suppressing the end-of-sequence token after the end of the CoT block (</think>). Our method requires no datasets, parameter changes, or training, relying solely on modifying token probabilities during generation. In our experiments with official DeepSeek-R1 distillations, these interventions increased the proportion of substantive answers to sensitive prompts without affecting performance on standard benchmarks. Our findings suggest that refusal behaviors can be circumvented by blocking refusal subspaces at specific points in the generation process.
Directional Sign Loss: A Topology-Preserving Loss Function that Approximates the Sign of Finite Differences
Apr 05, 2025Preserving critical topological features in learned latent spaces is a fundamental challenge in representation learning, particularly for topology-sensitive data. This paper introduces directional sign loss (DSL), a novel loss function that approximates the number of mismatches in the signs of finite differences between corresponding elements of two arrays. By penalizing discrepancies in critical points between input and reconstructed data, DSL encourages autoencoders and other learnable compressors to retain the topological features of the original data. We present the mathematical formulation, complexity analysis, and practical implementation of DSL, comparing its behavior to its non-differentiable counterpart and to other topological measures. Experiments on one-, two-, and three-dimensional data show that combining DSL with traditional loss functions preserves topological features more effectively than traditional losses alone. Moreover, DSL serves as a differentiable, efficient proxy for common topology-based metrics, enabling its use in gradient-based optimization frameworks.
What Operations can be Performed Directly on Compressed Arrays, and with What Error?
Jun 17, 2024
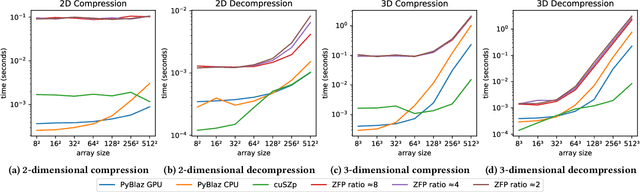
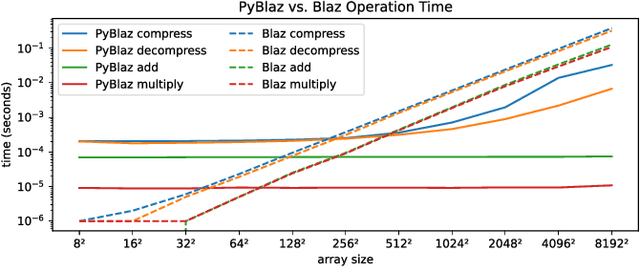
In response to the rapidly escalating costs of computing with large matrices and tensors caused by data movement, several lossy compression methods have been developed to significantly reduce data volumes. Unfortunately, all these methods require the data to be decompressed before further computations are done. In this work, we develop a lossy compressor that allows a dozen fairly fundamental operations directly on compressed data while offering good compression ratios and modest errors. We implement a new compressor PyBlaz based on the familiar GPU-powered PyTorch framework, and evaluate it on three non-trivial applications, choosing different number systems for internal representation. Our results demonstrate that the compressed-domain operations achieve good scalability with problem sizes while incurring errors well within acceptable limits. To our best knowledge, this is the first such lossy compressor that supports compressed-domain operations while achieving acceptable performance as well as error.
Understanding the Effect of the Long Tail on Neural Network Compression
Jun 27, 2023Network compression is now a mature sub-field of neural network research: over the last decade, significant progress has been made towards reducing the size of models and speeding up inference, while maintaining the classification accuracy. However, many works have observed that focusing on just the overall accuracy can be misguided. E.g., it has been shown that mismatches between the full and compressed models can be biased towards under-represented classes. This raises the important research question, can we achieve network compression while maintaining "semantic equivalence" with the original network? In this work, we study this question in the context of the "long tail" phenomenon in computer vision datasets observed by Feldman, et al. They argue that memorization of certain inputs (appropriately defined) is essential to achieving good generalization. As compression limits the capacity of a network (and hence also its ability to memorize), we study the question: are mismatches between the full and compressed models correlated with the memorized training data? We present positive evidence in this direction for image classification tasks, by considering different base architectures and compression schemes.