 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuessing Efficiently for Constrained Subspace Approximation
Apr 29, 2025In this paper we study constrained subspace approximation problem. Given a set of $n$ points $\{a_1,\ldots,a_n\}$ in $\mathbb{R}^d$, the goal of the {\em subspace approximation} problem is to find a $k$ dimensional subspace that best approximates the input points. More precisely, for a given $p\geq 1$, we aim to minimize the $p$th power of the $\ell_p$ norm of the error vector $(\|a_1-\bm{P}a_1\|,\ldots,\|a_n-\bm{P}a_n\|)$, where $\bm{P}$ denotes the projection matrix onto the subspace and the norms are Euclidean. In \emph{constrained} subspace approximation (CSA), we additionally have constraints on the projection matrix $\bm{P}$. In its most general form, we require $\bm{P}$ to belong to a given subset $\mathcal{S}$ that is described explicitly or implicitly. We introduce a general framework for constrained subspace approximation. Our approach, that we term coreset-guess-solve, yields either $(1+\varepsilon)$-multiplicative or $\varepsilon$-additive approximations for a variety of constraints. We show that it provides new algorithms for partition-constrained subspace approximation with applications to {\it fair} subspace approximation, $k$-means clustering, and projected non-negative matrix factorization, among others. Specifically, while we reconstruct the best known bounds for $k$-means clustering in Euclidean spaces, we improve the known results for the remainder of the problems.
Counting Hours, Counting Losses: The Toll of Unpredictable Work Schedules on Financial Security
Apr 10, 2025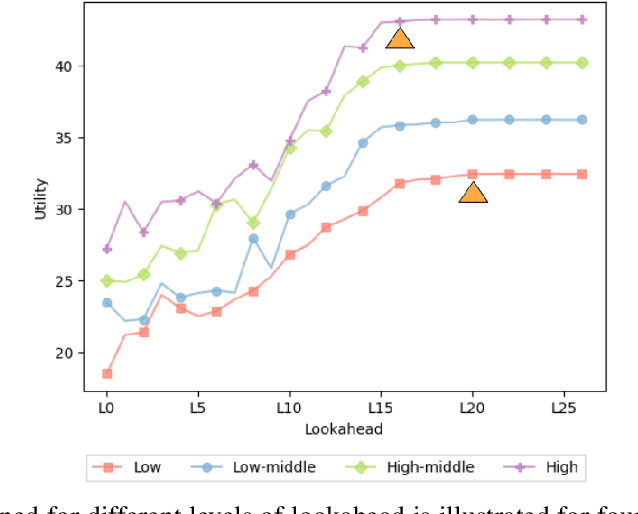
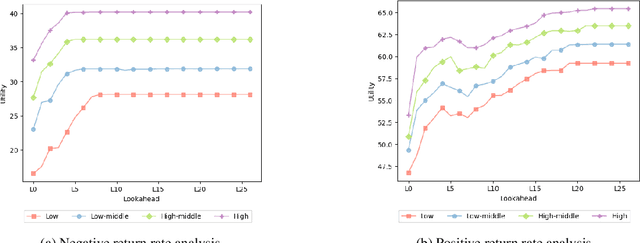
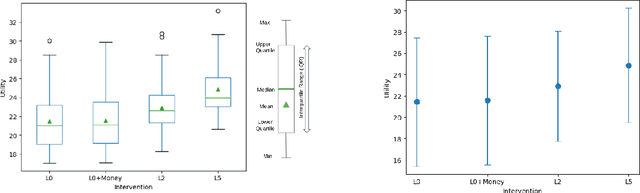
Financial instability has become a significant issue in today's society. While research typically focuses on financial aspects, there is a tendency to overlook time-related aspects of unstable work schedules. The inability to rely on consistent work schedules leads to burnout, work-family conflicts, and financial shocks that directly impact workers' income and assets. Unforeseen fluctuations in earnings pose challenges in financial planning, affecting decisions on savings and spending and ultimately undermining individuals' long-term financial stability and well-being. This issue is particularly evident in sectors where workers experience frequently changing schedules without sufficient notice, including those in the food service and retail sectors, part-time and hourly workers, and individuals with lower incomes. These groups are already more financially vulnerable, and the unpredictable nature of their schedules exacerbates their financial fragility. Our objective is to understand how unforeseen fluctuations in earnings exacerbate financial fragility by investigating the extent to which individuals' financial management depends on their ability to anticipate and plan for the future. To address this question, we develop a simulation framework that models how individuals optimize utility amidst financial uncertainty and the imperative to avoid financial ruin. We employ online learning techniques, specifically adapting workers' consumption policies based on evolving information about their work schedules. With this framework, we show both theoretically and empirically how a worker's capacity to anticipate schedule changes enhances their long-term utility. Conversely, the inability to predict future events can worsen workers' instability. Moreover, our framework enables us to explore interventions to mitigate the problem of schedule uncertainty and evaluate their effectiveness.
An Efficient Row-Based Sparse Fine-Tuning
Feb 17, 2025Fine-tuning is an important step in adapting foundation models such as large language models to downstream tasks. To make this step more accessible to users with limited computational budgets, it is crucial to develop fine-tuning methods that are memory and computationally efficient. Sparse Fine-tuning (SFT) and Low-rank adaptation (LoRA) are two frameworks that have emerged for addressing this problem and have been adopted widely in practice. In this work, we develop a new SFT framework, based on ideas from neural network pruning. At a high level, we first identify "important" neurons/nodes using feature importance metrics from network pruning (specifically, we use the structural pruning method), and then perform fine-tuning by restricting to weights involving these neurons. Using experiments on common language tasks, we demonstrate that our method significantly improves the memory efficiency of SFT without increasing training time complexity and implementation complexity, while achieving accuracy comparable to state-of-the-art methods such as LoRA and its variants.
On the Robustness of Spectral Algorithms for Semirandom Stochastic Block Models
Dec 18, 2024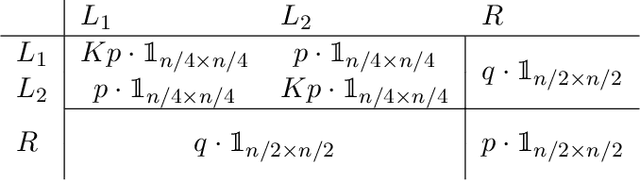
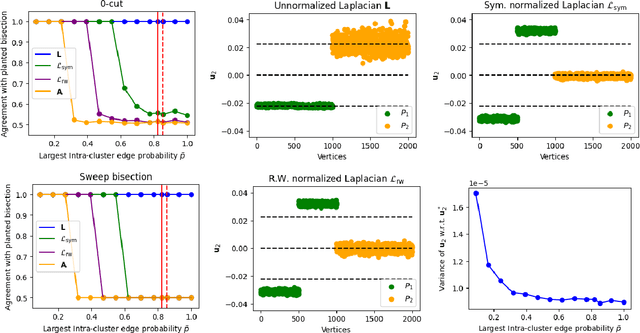
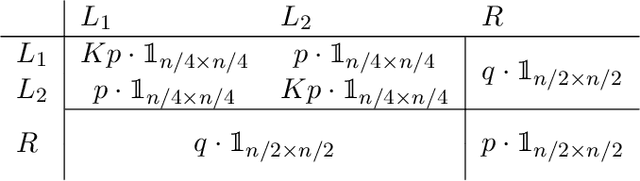
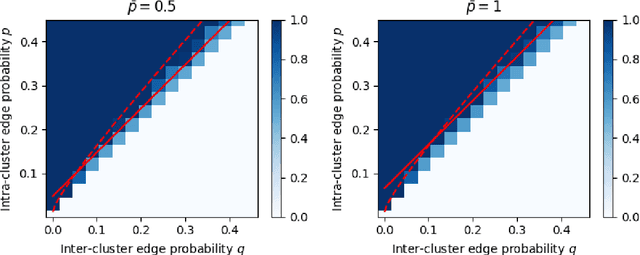
In a graph bisection problem, we are given a graph $G$ with two equally-sized unlabeled communities, and the goal is to recover the vertices in these communities. A popular heuristic, known as spectral clustering, is to output an estimated community assignment based on the eigenvector corresponding to the second smallest eigenvalue of the Laplacian of $G$. Spectral algorithms can be shown to provably recover the cluster structure for graphs generated from certain probabilistic models, such as the Stochastic Block Model (SBM). However, spectral clustering is known to be non-robust to model mis-specification. Techniques based on semidefinite programming have been shown to be more robust, but they incur significant computational overheads. In this work, we study the robustness of spectral algorithms against semirandom adversaries. Informally, a semirandom adversary is allowed to ``helpfully'' change the specification of the model in a way that is consistent with the ground-truth solution. Our semirandom adversaries in particular are allowed to add edges inside clusters or increase the probability that an edge appears inside a cluster. Semirandom adversaries are a useful tool to determine the extent to which an algorithm has overfit to statistical assumptions on the input. On the positive side, we identify classes of semirandom adversaries under which spectral bisection using the _unnormalized_ Laplacian is strongly consistent, i.e., it exactly recovers the planted partitioning. On the negative side, we show that in these classes spectral bisection with the _normalized_ Laplacian outputs a partitioning that makes a classification mistake on a constant fraction of the vertices. Finally, we demonstrate numerical experiments that complement our theoretical findings.
Convergence Guarantees for the DeepWalk Embedding on Block Models
Oct 26, 2024Graph embeddings have emerged as a powerful tool for understanding the structure of graphs. Unlike classical spectral methods, recent methods such as DeepWalk, Node2Vec, etc. are based on solving nonlinear optimization problems on the graph, using local information obtained by performing random walks. These techniques have empirically been shown to produce ''better'' embeddings than their classical counterparts. However, due to their reliance on solving a nonconvex optimization problem, obtaining theoretical guarantees on the properties of the solution has remained a challenge, even for simple classes of graphs. In this work, we show convergence properties for the DeepWalk algorithm on graphs obtained from the Stochastic Block Model (SBM). Despite being simplistic, the SBM has proved to be a classic model for analyzing the behavior of algorithms on large graphs. Our results mirror the existing ones for spectral embeddings on SBMs, showing that even in the case of one-dimensional embeddings, the output of the DeepWalk algorithm provably recovers the cluster structure with high probability.
On Mergable Coresets for Polytope Distance
Nov 08, 2023

We show that a constant-size constant-error coreset for polytope distance is simple to maintain under merges of coresets. However, increasing the size cannot improve the error bound significantly beyond that constant.
Tight Bounds for Volumetric Spanners and Applications
Sep 29, 2023
Given a set of points of interest, a volumetric spanner is a subset of the points using which all the points can be expressed using "small" coefficients (measured in an appropriate norm). Formally, given a set of vectors $X = \{v_1, v_2, \dots, v_n\}$, the goal is to find $T \subseteq [n]$ such that every $v \in X$ can be expressed as $\sum_{i\in T} \alpha_i v_i$, with $\|\alpha\|$ being small. This notion, which has also been referred to as a well-conditioned basis, has found several applications, including bandit linear optimization, determinant maximization, and matrix low rank approximation. In this paper, we give almost optimal bounds on the size of volumetric spanners for all $\ell_p$ norms, and show that they can be constructed using a simple local search procedure. We then show the applications of our result to other tasks and in particular the problem of finding coresets for the Minimum Volume Enclosing Ellipsoid (MVEE) problem.
Understanding the Effect of the Long Tail on Neural Network Compression
Jun 27, 2023Network compression is now a mature sub-field of neural network research: over the last decade, significant progress has been made towards reducing the size of models and speeding up inference, while maintaining the classification accuracy. However, many works have observed that focusing on just the overall accuracy can be misguided. E.g., it has been shown that mismatches between the full and compressed models can be biased towards under-represented classes. This raises the important research question, can we achieve network compression while maintaining "semantic equivalence" with the original network? In this work, we study this question in the context of the "long tail" phenomenon in computer vision datasets observed by Feldman, et al. They argue that memorization of certain inputs (appropriately defined) is essential to achieving good generalization. As compression limits the capacity of a network (and hence also its ability to memorize), we study the question: are mismatches between the full and compressed models correlated with the memorized training data? We present positive evidence in this direction for image classification tasks, by considering different base architectures and compression schemes.
Online Learning and Bandits with Queried Hints
Nov 04, 2022We consider the classic online learning and stochastic multi-armed bandit (MAB) problems, when at each step, the online policy can probe and find out which of a small number ($k$) of choices has better reward (or loss) before making its choice. In this model, we derive algorithms whose regret bounds have exponentially better dependence on the time horizon compared to the classic regret bounds. In particular, we show that probing with $k=2$ suffices to achieve time-independent regret bounds for online linear and convex optimization. The same number of probes improve the regret bound of stochastic MAB with independent arms from $O(\sqrt{nT})$ to $O(n^2 \log T)$, where $n$ is the number of arms and $T$ is the horizon length. For stochastic MAB, we also consider a stronger model where a probe reveals the reward values of the probed arms, and show that in this case, $k=3$ probes suffice to achieve parameter-independent constant regret, $O(n^2)$. Such regret bounds cannot be achieved even with full feedback after the play, showcasing the power of limited ``advice'' via probing before making the play. We also present extensions to the setting where the hints can be imperfect, and to the case of stochastic MAB where the rewards of the arms can be correlated.
Logarithmic Regret from Sublinear Hints
Nov 09, 2021We consider the online linear optimization problem, where at every step the algorithm plays a point $x_t$ in the unit ball, and suffers loss $\langle c_t, x_t\rangle$ for some cost vector $c_t$ that is then revealed to the algorithm. Recent work showed that if an algorithm receives a hint $h_t$ that has non-trivial correlation with $c_t$ before it plays $x_t$, then it can achieve a regret guarantee of $O(\log T)$, improving on the bound of $\Theta(\sqrt{T})$ in the standard setting. In this work, we study the question of whether an algorithm really requires a hint at every time step. Somewhat surprisingly, we show that an algorithm can obtain $O(\log T)$ regret with just $O(\sqrt{T})$ hints under a natural query model; in contrast, we also show that $o(\sqrt{T})$ hints cannot guarantee better than $\Omega(\sqrt{T})$ regret. We give two applications of our result, to the well-studied setting of optimistic regret bounds and to the problem of online learning with abstention.