 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathesis: Towards Formal Theorem Proving from Natural Languages
Jun 08, 2025



Recent advances in large language models show strong promise for formal reasoning. However, most LLM-based theorem provers have long been constrained by the need for expert-written formal statements as inputs, limiting their applicability to real-world problems expressed in natural language. We tackle this gap with Mathesis, the first end-to-end theorem proving pipeline processing informal problem statements. It contributes Mathesis-Autoformalizer, the first autoformalizer using reinforcement learning to enhance the formalization ability of natural language problems, aided by our novel LeanScorer framework for nuanced formalization quality assessment. It also proposes a Mathesis-Prover, which generates formal proofs from the formalized statements. To evaluate the real-world applicability of end-to-end formal theorem proving, we introduce Gaokao-Formal, a benchmark of 488 complex problems from China's national college entrance exam. Our approach is carefully designed, with a thorough study of each component. Experiments demonstrate Mathesis's effectiveness, with the autoformalizer outperforming the best baseline by 22% in pass-rate on Gaokao-Formal. The full system surpasses other model combinations, achieving 64% accuracy on MiniF2F with pass@32 and a state-of-the-art 18% on Gaokao-Formal.
Near-optimal Active Regression of Single-Index Models
Feb 25, 2025

The active regression problem of the single-index model is to solve $\min_x \lVert f(Ax)-b\rVert_p$, where $A$ is fully accessible and $b$ can only be accessed via entry queries, with the goal of minimizing the number of queries to the entries of $b$. When $f$ is Lipschitz, previous results only obtain constant-factor approximations. This work presents the first algorithm that provides a $(1+\varepsilon)$-approximation solution by querying $\tilde{O}(d^{\frac{p}{2}\vee 1}/\varepsilon^{p\vee 2})$ entries of $b$. This query complexity is also shown to be optimal up to logarithmic factors for $p\in [1,2]$ and the $\varepsilon$-dependence of $1/\varepsilon^p$ is shown to be optimal for $p>2$.
Dimension-independent rates for structured neural density estimation
Nov 22, 2024



We show that deep neural networks achieve dimension-independent rates of convergence for learning structured densities such as those arising in image, audio, video, and text applications. More precisely, we demonstrate that neural networks with a simple $L^2$-minimizing loss achieve a rate of $n^{-1/(4+r)}$ in nonparametric density estimation when the underlying density is Markov to a graph whose maximum clique size is at most $r$, and we provide evidence that in the aforementioned applications, this size is typically constant, i.e., $r=O(1)$. We then establish that the optimal rate in $L^1$ is $n^{-1/(2+r)}$ which, compared to the standard nonparametric rate of $n^{-1/(2+d)}$, reveals that the effective dimension of such problems is the size of the largest clique in the Markov random field. These rates are independent of the data's ambient dimension, making them applicable to realistic models of image, sound, video, and text data. Our results provide a novel justification for deep learning's ability to circumvent the curse of dimensionality, demonstrating dimension-independent convergence rates in these contexts.
Agnostic Active Learning of Single Index Models with Linear Sample Complexity
May 16, 2024We study active learning methods for single index models of the form $F({\mathbf x}) = f(\langle {\mathbf w}, {\mathbf x}\rangle)$, where $f:\mathbb{R} \to \mathbb{R}$ and ${\mathbf x,\mathbf w} \in \mathbb{R}^d$. In addition to their theoretical interest as simple examples of non-linear neural networks, single index models have received significant recent attention due to applications in scientific machine learning like surrogate modeling for partial differential equations (PDEs). Such applications require sample-efficient active learning methods that are robust to adversarial noise. I.e., that work even in the challenging agnostic learning setting. We provide two main results on agnostic active learning of single index models. First, when $f$ is known and Lipschitz, we show that $\tilde{O}(d)$ samples collected via {statistical leverage score sampling} are sufficient to learn a near-optimal single index model. Leverage score sampling is simple to implement, efficient, and already widely used for actively learning linear models. Our result requires no assumptions on the data distribution, is optimal up to log factors, and improves quadratically on a recent ${O}(d^{2})$ bound of \cite{gajjar2023active}. Second, we show that $\tilde{O}(d)$ samples suffice even in the more difficult setting when $f$ is \emph{unknown}. Our results leverage tools from high dimensional probability, including Dudley's inequality and dual Sudakov minoration, as well as a novel, distribution-aware discretization of the class of Lipschitz functions.
Optimal estimation of Gaussian (poly)trees
Feb 09, 2024



We develop optimal algorithms for learning undirected Gaussian trees and directed Gaussian polytrees from data. We consider both problems of distribution learning (i.e. in KL distance) and structure learning (i.e. exact recovery). The first approach is based on the Chow-Liu algorithm, and learns an optimal tree-structured distribution efficiently. The second approach is a modification of the PC algorithm for polytrees that uses partial correlation as a conditional independence tester for constraint-based structure learning. We derive explicit finite-sample guarantees for both approaches, and show that both approaches are optimal by deriving matching lower bounds. Additionally, we conduct numerical experiments to compare the performance of various algorithms, providing further insights and empirical evidence.
Inconsistency of cross-validation for structure learning in Gaussian graphical models
Dec 28, 2023Despite numerous years of research into the merits and trade-offs of various model selection criteria, obtaining robust results that elucidate the behavior of cross-validation remains a challenging endeavor. In this paper, we highlight the inherent limitations of cross-validation when employed to discern the structure of a Gaussian graphical model. We provide finite-sample bounds on the probability that the Lasso estimator for the neighborhood of a node within a Gaussian graphical model, optimized using a prediction oracle, misidentifies the neighborhood. Our results pertain to both undirected and directed acyclic graphs, encompassing general, sparse covariance structures. To support our theoretical findings, we conduct an empirical investigation of this inconsistency by contrasting our outcomes with other commonly used information criteria through an extensive simulation study. Given that many algorithms designed to learn the structure of graphical models require hyperparameter selection, the precise calibration of this hyperparameter is paramount for accurately estimating the inherent structure. Consequently, our observations shed light on this widely recognized practical challenge.
On Mergable Coresets for Polytope Distance
Nov 08, 2023

We show that a constant-size constant-error coreset for polytope distance is simple to maintain under merges of coresets. However, increasing the size cannot improve the error bound significantly beyond that constant.
Learning Mixtures of Gaussians with Censored Data
May 06, 2023We study the problem of learning mixtures of Gaussians with censored data. Statistical learning with censored data is a classical problem, with numerous practical applications, however, finite-sample guarantees for even simple latent variable models such as Gaussian mixtures are missing. Formally, we are given censored data from a mixture of univariate Gaussians $$\sum_{i=1}^k w_i \mathcal{N}(\mu_i,\sigma^2),$$ i.e. the sample is observed only if it lies inside a set $S$. The goal is to learn the weights $w_i$ and the means $\mu_i$. We propose an algorithm that takes only $\frac{1}{\varepsilon^{O(k)}}$ samples to estimate the weights $w_i$ and the means $\mu_i$ within $\varepsilon$ error.
A super-polynomial lower bound for learning nonparametric mixtures
Mar 28, 2022
We study the problem of learning nonparametric distributions in a finite mixture, and establish a super-polynomial lower bound on the sample complexity of learning the component distributions in such models. Namely, we are given i.i.d. samples from $f$ where $$ f=\sum_{i=1}^k w_i f_i, \quad\sum_{i=1}^k w_i=1, \quad w_i>0 $$ and we are interested in learning each component $f_i$. Without any assumptions on $f_i$, this problem is ill-posed. In order to identify the components $f_i$, we assume that each $f_i$ can be written as a convolution of a Gaussian and a compactly supported density $\nu_i$ with $\text{supp}(\nu_i)\cap \text{supp}(\nu_j)=\emptyset$. Our main result shows that $\Omega((\frac{1}{\varepsilon})^{C\log\log \frac{1}{\varepsilon}})$ samples are required for estimating each $f_i$. The proof relies on a fast rate for approximation with Gaussians, which may be of independent interest. This result has important implications for the hardness of learning more general nonparametric latent variable models that arise in machine learning applications.
Optimal estimation of Gaussian DAG models
Jan 25, 2022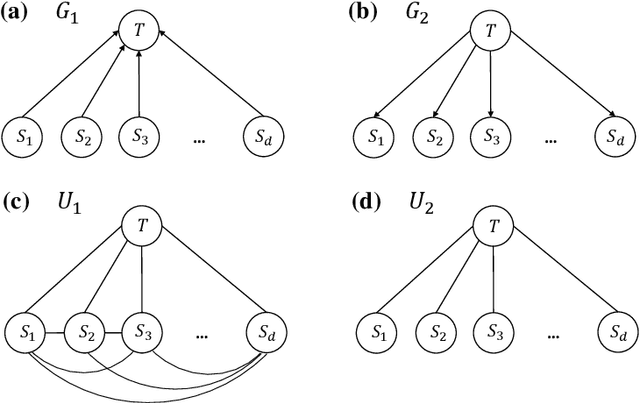
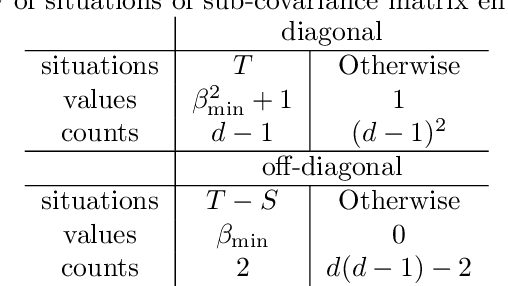

We study the optimal sample complexity of learning a Gaussian directed acyclic graph (DAG) from observational data. Our main result establishes the minimax optimal sample complexity for learning the structure of a linear Gaussian DAG model with equal variances to be $n\asymp q\log(d/q)$, where $q$ is the maximum number of parents and $d$ is the number of nodes. We further make comparisons with the classical problem of learning (undirected) Gaussian graphical models, showing that under the equal variance assumption, these two problems share the same optimal sample complexity. In other words, at least for Gaussian models with equal error variances, learning a directed graphical model is not more difficult than learning an undirected graphical model. Our results also extend to more general identification assumptions as well as subgaussian errors.