 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosIR: Position-Aware Heterogeneous Information Retrieval Benchmark
Jan 13, 2026While dense retrieval models have achieved remarkable success, rigorous evaluation of their sensitivity to the position of relevant information (i.e., position bias) remains largely unexplored. Existing benchmarks typically employ position-agnostic relevance labels, conflating the challenge of processing long contexts with the bias against specific evidence locations. To address this challenge, we introduce PosIR (Position-Aware Information Retrieval), a comprehensive benchmark designed to diagnose position bias in diverse retrieval scenarios. PosIR comprises 310 datasets spanning 10 languages and 31 domains, constructed through a rigorous pipeline that ties relevance to precise reference spans, enabling the strict disentanglement of document length from information position. Extensive experiments with 10 state-of-the-art embedding models reveal that: (1) Performance on PosIR in long-context settings correlates poorly with the MMTEB benchmark, exposing limitations in current short-text benchmarks; (2) Position bias is pervasive and intensifies with document length, with most models exhibiting primacy bias while certain models show unexpected recency bias; (3) Gradient-based saliency analysis further uncovers the distinct internal attention mechanisms driving these positional preferences. In summary, PosIR serves as a valuable diagnostic framework to foster the development of position-robust retrieval systems.
Jasper-Token-Compression-600M Technical Report
Nov 19, 2025
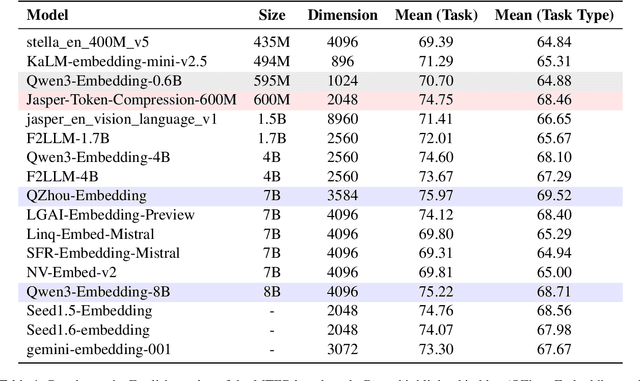
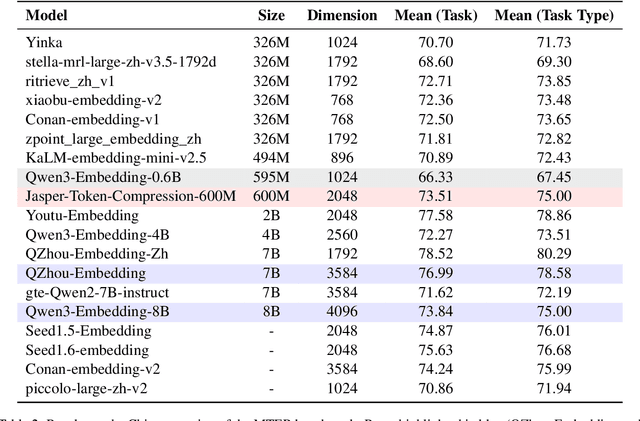

This technical report presents the training methodology and evaluation results of the open-source Jasper-Token-Compression-600M model, released in November 2025. Building on previous distillation-based recipes from the English Stella and Jasper models, we successfully extend this approach to a bilingual (English and Chinese) domain, further enhancing model performance through the incorporation of contrastive learning. A key innovation of our model is the introduction of a one-dimensional convolution-based token compression module. We dynamically adjust the compression rate during training, enabling the model to learn more robust and efficient compressed text representations. By combining knowledge distillation with token compression techniques, we achieve significant improvements in both embedding quality and inference efficiency. Our model performs with higher efficiency than a traditional 0.6B model while achieving performance comparable to that of an 8B model. For more information on the model release, visit: https://huggingface.co/infgrad/Jasper-Token-Compression-600M.
Mathesis: Towards Formal Theorem Proving from Natural Languages
Jun 08, 2025



Recent advances in large language models show strong promise for formal reasoning. However, most LLM-based theorem provers have long been constrained by the need for expert-written formal statements as inputs, limiting their applicability to real-world problems expressed in natural language. We tackle this gap with Mathesis, the first end-to-end theorem proving pipeline processing informal problem statements. It contributes Mathesis-Autoformalizer, the first autoformalizer using reinforcement learning to enhance the formalization ability of natural language problems, aided by our novel LeanScorer framework for nuanced formalization quality assessment. It also proposes a Mathesis-Prover, which generates formal proofs from the formalized statements. To evaluate the real-world applicability of end-to-end formal theorem proving, we introduce Gaokao-Formal, a benchmark of 488 complex problems from China's national college entrance exam. Our approach is carefully designed, with a thorough study of each component. Experiments demonstrate Mathesis's effectiveness, with the autoformalizer outperforming the best baseline by 22% in pass-rate on Gaokao-Formal. The full system surpasses other model combinations, achieving 64% accuracy on MiniF2F with pass@32 and a state-of-the-art 18% on Gaokao-Formal.
Dewey Long Context Embedding Model: A Technical Report
Mar 26, 2025This technical report presents the training methodology and evaluation results of the open-source dewey_en_beta embedding model. The increasing demand for retrieval-augmented generation (RAG) systems and the expanding context window capabilities of large language models (LLMs) have created critical challenges for conventional embedding models. Current approaches often struggle to maintain semantic coherence when processing documents exceeding typical sequence length limitations, significantly impacting retrieval performance in knowledge-intensive applications. This paper presents dewey_en_beta, a novel text embedding model that achieves excellent performance on MTEB (Eng, v2) and LongEmbed benchmark while supporting 128K token sequences. Our technical contribution centers on chunk alignment training, an innovative methodology that enables the simultaneous generation of localized chunk embeddings and global document-level representations through distillation. Information regarding the model release can be found at https://huggingface.co/infgrad/dewey_en_beta.
Nyonic Technical Report
Apr 24, 2024



This report details the development and key achievements of our latest language model designed for custom large language models. The advancements introduced include a novel Online Data Scheduler that supports flexible training data adjustments and curriculum learning. The model's architecture is fortified with state-of-the-art techniques such as Rotary Positional Embeddings, QK-LayerNorm, and a specially crafted multilingual tokenizer to enhance stability and performance. Moreover, our robust training framework incorporates advanced monitoring and rapid recovery features to ensure optimal efficiency. Our Wonton 7B model has demonstrated competitive performance on a range of multilingual and English benchmarks. Future developments will prioritize narrowing the performance gap with more extensively trained models, thereby enhancing the model's real-world efficacy and adaptability.GitHub: \url{https://github.com/nyonicai/nyonic-public}