 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosIR: Position-Aware Heterogeneous Information Retrieval Benchmark
Jan 13, 2026While dense retrieval models have achieved remarkable success, rigorous evaluation of their sensitivity to the position of relevant information (i.e., position bias) remains largely unexplored. Existing benchmarks typically employ position-agnostic relevance labels, conflating the challenge of processing long contexts with the bias against specific evidence locations. To address this challenge, we introduce PosIR (Position-Aware Information Retrieval), a comprehensive benchmark designed to diagnose position bias in diverse retrieval scenarios. PosIR comprises 310 datasets spanning 10 languages and 31 domains, constructed through a rigorous pipeline that ties relevance to precise reference spans, enabling the strict disentanglement of document length from information position. Extensive experiments with 10 state-of-the-art embedding models reveal that: (1) Performance on PosIR in long-context settings correlates poorly with the MMTEB benchmark, exposing limitations in current short-text benchmarks; (2) Position bias is pervasive and intensifies with document length, with most models exhibiting primacy bias while certain models show unexpected recency bias; (3) Gradient-based saliency analysis further uncovers the distinct internal attention mechanisms driving these positional preferences. In summary, PosIR serves as a valuable diagnostic framework to foster the development of position-robust retrieval systems.
Jasper-Token-Compression-600M Technical Report
Nov 19, 2025
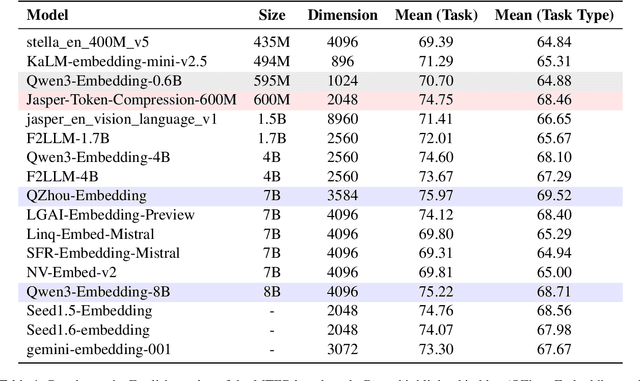
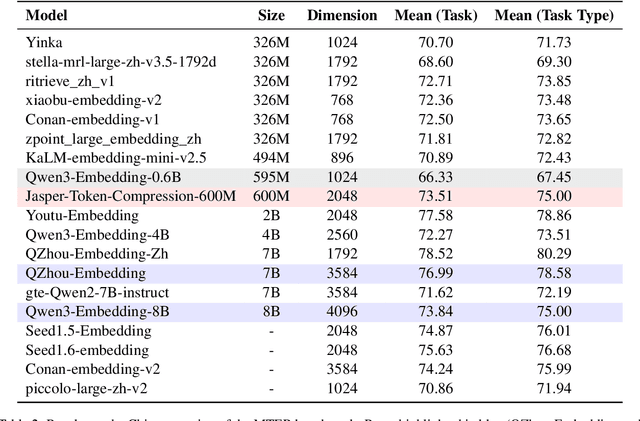

This technical report presents the training methodology and evaluation results of the open-source Jasper-Token-Compression-600M model, released in November 2025. Building on previous distillation-based recipes from the English Stella and Jasper models, we successfully extend this approach to a bilingual (English and Chinese) domain, further enhancing model performance through the incorporation of contrastive learning. A key innovation of our model is the introduction of a one-dimensional convolution-based token compression module. We dynamically adjust the compression rate during training, enabling the model to learn more robust and efficient compressed text representations. By combining knowledge distillation with token compression techniques, we achieve significant improvements in both embedding quality and inference efficiency. Our model performs with higher efficiency than a traditional 0.6B model while achieving performance comparable to that of an 8B model. For more information on the model release, visit: https://huggingface.co/infgrad/Jasper-Token-Compression-600M.
Benchmarking the Myopic Trap: Positional Bias in Information Retrieval
May 20, 2025This study investigates a specific form of positional bias, termed the Myopic Trap, where retrieval models disproportionately attend to the early parts of documents while overlooking relevant information that appears later. To systematically quantify this phenomenon, we propose a semantics-preserving evaluation framework that repurposes the existing NLP datasets into position-aware retrieval benchmarks. By evaluating the SOTA models of full retrieval pipeline, including BM25, embedding models, ColBERT-style late-interaction models, and reranker models, we offer a broader empirical perspective on positional bias than prior work. Experimental results show that embedding models and ColBERT-style models exhibit significant performance degradation when query-related content is shifted toward later positions, indicating a pronounced head bias. Notably, under the same training configuration, ColBERT-style approach show greater potential for mitigating positional bias compared to the traditional single-vector approach. In contrast, BM25 and reranker models remain largely unaffected by such perturbations, underscoring their robustness to positional bias. Code and data are publicly available at: www.github.com/NovaSearch-Team/RAG-Retrieval.
Dewey Long Context Embedding Model: A Technical Report
Mar 26, 2025This technical report presents the training methodology and evaluation results of the open-source dewey_en_beta embedding model. The increasing demand for retrieval-augmented generation (RAG) systems and the expanding context window capabilities of large language models (LLMs) have created critical challenges for conventional embedding models. Current approaches often struggle to maintain semantic coherence when processing documents exceeding typical sequence length limitations, significantly impacting retrieval performance in knowledge-intensive applications. This paper presents dewey_en_beta, a novel text embedding model that achieves excellent performance on MTEB (Eng, v2) and LongEmbed benchmark while supporting 128K token sequences. Our technical contribution centers on chunk alignment training, an innovative methodology that enables the simultaneous generation of localized chunk embeddings and global document-level representations through distillation. Information regarding the model release can be found at https://huggingface.co/infgrad/dewey_en_beta.
Jasper and Stella: distillation of SOTA embedding models
Dec 26, 2024



A crucial component of many deep learning applications (such as FAQ and RAG) is dense retrieval, in which embedding models are used to convert raw text to numerical vectors and then get the most similar text by MIPS (Maximum Inner Product Search). Some text embedding benchmarks (e.g. MTEB, BEIR, and AIR-Bench) have been established to evaluate embedding models accurately. Thanks to these benchmarks, we can use SOTA models; however, the deployment and application of these models in industry were hampered by their large vector dimensions and numerous parameters. To alleviate this problem, 1) we present a distillation technique that can enable a smaller student model to achieve good performance. 2) Inspired by MRL we present a training approach of reducing the vector dimensions based on its own vectors or its teacher vectors. 3) We do simple yet effective alignment training between images and text to make our model a multimodal encoder. We trained Stella and Jasper models using the technologies above and achieved high scores on the MTEB leaderboard. We release the model and data at Hugging Face Hub (https://huggingface.co/infgrad/jasper_en_vision_language_v1) and the training logs are at https://api.wandb.ai/links/dunnzhang0/z8jqoqpb.