 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgedots.llm1 Technical Report
Jun 06, 2025Mixture of Experts (MoE) models have emerged as a promising paradigm for scaling language models efficiently by activating only a subset of parameters for each input token. In this report, we present dots.llm1, a large-scale MoE model that activates 14B parameters out of a total of 142B parameters, delivering performance on par with state-of-the-art models while reducing training and inference costs. Leveraging our meticulously crafted and efficient data processing pipeline, dots.llm1 achieves performance comparable to Qwen2.5-72B after pretraining on 11.2T high-quality tokens and post-training to fully unlock its capabilities. Notably, no synthetic data is used during pretraining. To foster further research, we open-source intermediate training checkpoints at every one trillion tokens, providing valuable insights into the learning dynamics of large language models.
EvoLlama: Enhancing LLMs' Understanding of Proteins via Multimodal Structure and Sequence Representations
Dec 16, 2024



Current Large Language Models (LLMs) for understanding proteins primarily treats amino acid sequences as a text modality. Meanwhile, Protein Language Models (PLMs), such as ESM-2, have learned massive sequential evolutionary knowledge from the universe of natural protein sequences. Furthermore, structure-based encoders like ProteinMPNN learn the structural information of proteins through Graph Neural Networks. However, whether the incorporation of protein encoders can enhance the protein understanding of LLMs has not been explored. To bridge this gap, we propose EvoLlama, a multimodal framework that connects a structure-based encoder, a sequence-based protein encoder and an LLM for protein understanding. EvoLlama consists of a ProteinMPNN structure encoder, an ESM-2 protein sequence encoder, a multimodal projector to align protein and text representations and a Llama-3 text decoder. To train EvoLlama, we fine-tune it on protein-oriented instructions and protein property prediction datasets verbalized via natural language instruction templates. Our experiments show that EvoLlama's protein understanding capabilities have been significantly enhanced, outperforming other fine-tuned protein-oriented LLMs in zero-shot settings by an average of 1%-8% and surpassing the state-of-the-art baseline with supervised fine-tuning by an average of 6%. On protein property prediction datasets, our approach achieves promising results that are competitive with state-of-the-art task-specific baselines. We will release our code in a future version.
Untie the Knots: An Efficient Data Augmentation Strategy for Long-Context Pre-Training in Language Models
Sep 07, 2024Large language models (LLM) have prioritized expanding the context window from which models can incorporate more information. However, training models to handle long contexts presents significant challenges. These include the scarcity of high-quality natural long-context data, the potential for performance degradation on short-context tasks, and the reduced training efficiency associated with attention mechanisms. In this paper, we introduce Untie the Knots (\textbf{UtK}), a novel data augmentation strategy employed during the continue pre-training phase, designed to efficiently enable LLMs to gain long-context capabilities without the need to modify the existing data mixture. In particular, we chunk the documents, shuffle the chunks, and create a complex and knotted structure of long texts; LLMs are then trained to untie these knots and identify relevant segments within seemingly chaotic token sequences. This approach greatly improves the model's performance by accurately attending to relevant information in long context and the training efficiency is also largely increased. We conduct extensive experiments on models with 7B and 72B parameters, trained on 20 billion tokens, demonstrating that UtK achieves 75\% and 84.5\% accurracy on RULER at 128K context length, significantly outperforming other long context strategies. The trained models will open-source for further research.
P-Tailor: Customizing Personality Traits for Language Models via Mixture of Specialized LoRA Experts
Jun 18, 2024Personalized large language models (LLMs) have attracted great attention in many applications, such as intelligent education and emotional support. Most work focuses on controlling the character settings based on the profile (e.g., age, skill, experience, and so on). Conversely, the psychological theory-based personality traits with implicit expression and behavior are not well modeled, limiting their potential application in more specialized fields such as the psychological counseling agents. In this paper, we propose a mixture of experts (MoE)-based personalized LLMs, named P-tailor, to model the Big Five Personality Traits. Particularly, we learn specialized LoRA experts to represent various traits, such as openness, conscientiousness, extraversion, agreeableness and neuroticism. Then, we integrate P-Tailor with a personality specialization loss, promoting experts to specialize in distinct personality traits, thereby enhancing the efficiency of model parameter utilization. Due to the lack of datasets, we also curate a high-quality personality crafting dataset (PCD) to learn and develop the ability to exhibit different personality traits across various topics. We conduct extensive experiments to verify the great performance and effectiveness of P-Tailor in manipulation of the fine-grained personality traits of LLMs.
Modeling Comparative Logical Relation with Contrastive Learning for Text Generation
Jun 13, 2024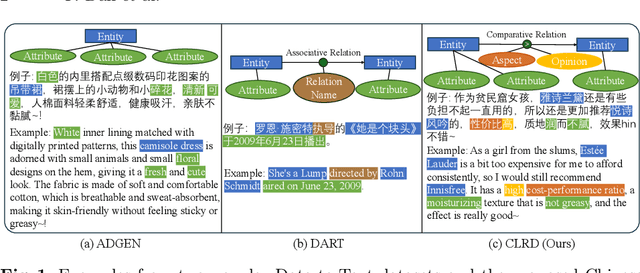
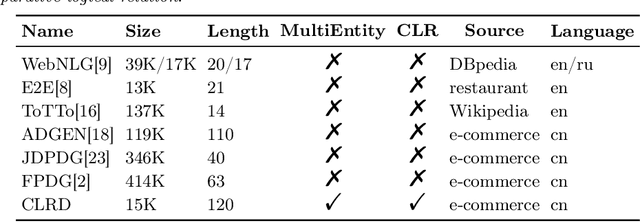
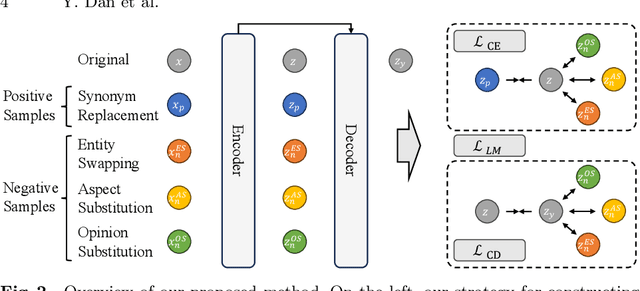
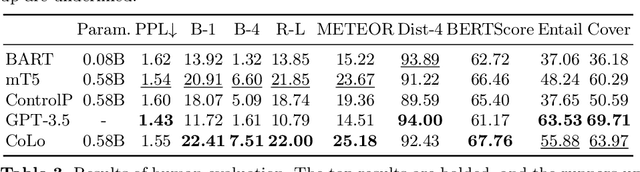
Data-to-Text Generation (D2T), a classic natural language generation problem, aims at producing fluent descriptions for structured input data, such as a table. Existing D2T works mainly focus on describing the superficial associative relations among entities, while ignoring the deep comparative logical relations, such as A is better than B in a certain aspect with a corresponding opinion, which is quite common in our daily life. In this paper, we introduce a new D2T task named comparative logical relation generation (CLRG). Additionally, we propose a Comparative Logic (CoLo) based text generation method, which generates texts following specific comparative logical relations with contrastive learning. Specifically, we first construct various positive and negative samples by fine-grained perturbations in entities, aspects and opinions. Then, we perform contrastive learning in the encoder layer to have a better understanding of the comparative logical relations, and integrate it in the decoder layer to guide the model to correctly generate the relations. Noting the data scarcity problem, we construct a Chinese Comparative Logical Relation Dataset (CLRD), which is a high-quality human-annotated dataset and challenging for text generation with descriptions of multiple entities and annotations on their comparative logical relations. Extensive experiments show that our method achieves impressive performance in both automatic and human evaluations.
Nyonic Technical Report
Apr 24, 2024



This report details the development and key achievements of our latest language model designed for custom large language models. The advancements introduced include a novel Online Data Scheduler that supports flexible training data adjustments and curriculum learning. The model's architecture is fortified with state-of-the-art techniques such as Rotary Positional Embeddings, QK-LayerNorm, and a specially crafted multilingual tokenizer to enhance stability and performance. Moreover, our robust training framework incorporates advanced monitoring and rapid recovery features to ensure optimal efficiency. Our Wonton 7B model has demonstrated competitive performance on a range of multilingual and English benchmarks. Future developments will prioritize narrowing the performance gap with more extensively trained models, thereby enhancing the model's real-world efficacy and adaptability.GitHub: \url{https://github.com/nyonicai/nyonic-public}
RethinkingTMSC: An Empirical Study for Target-Oriented Multimodal Sentiment Classification
Oct 14, 2023



Recently, Target-oriented Multimodal Sentiment Classification (TMSC) has gained significant attention among scholars. However, current multimodal models have reached a performance bottleneck. To investigate the causes of this problem, we perform extensive empirical evaluation and in-depth analysis of the datasets to answer the following questions: Q1: Are the modalities equally important for TMSC? Q2: Which multimodal fusion modules are more effective? Q3: Do existing datasets adequately support the research? Our experiments and analyses reveal that the current TMSC systems primarily rely on the textual modality, as most of targets' sentiments can be determined solely by text. Consequently, we point out several directions to work on for the TMSC task in terms of model design and dataset construction. The code and data can be found in https://github.com/Junjie-Ye/RethinkingTMSC.
UReader: Universal OCR-free Visually-situated Language Understanding with Multimodal Large Language Model
Oct 08, 2023Text is ubiquitous in our visual world, conveying crucial information, such as in documents, websites, and everyday photographs. In this work, we propose UReader, a first exploration of universal OCR-free visually-situated language understanding based on the Multimodal Large Language Model (MLLM). By leveraging the shallow text recognition ability of the MLLM, we only finetuned 1.2% parameters and the training cost is much lower than previous work following domain-specific pretraining and finetuning paradigms. Concretely, UReader is jointly finetuned on a wide range of Visually-situated Language Understanding tasks via a unified instruction format. To enhance the visual text and semantic understanding, we further apply two auxiliary tasks with the same format, namely text reading and key points generation tasks. We design a shape-adaptive cropping module before the encoder-decoder architecture of MLLM to leverage the frozen low-resolution vision encoder for processing high-resolution images. Without downstream finetuning, our single model achieves state-of-the-art ocr-free performance in 8 out of 10 visually-situated language understanding tasks, across 5 domains: documents, tables, charts, natural images, and webpage screenshots. Codes and instruction-tuning datasets will be released.
mPLUG-DocOwl: Modularized Multimodal Large Language Model for Document Understanding
Jul 04, 2023



Document understanding refers to automatically extract, analyze and comprehend information from various types of digital documents, such as a web page. Existing Multi-model Large Language Models (MLLMs), including mPLUG-Owl, have demonstrated promising zero-shot capabilities in shallow OCR-free text recognition, indicating their potential for OCR-free document understanding. Nevertheless, without in-domain training, these models tend to ignore fine-grained OCR features, such as sophisticated tables or large blocks of text, which are essential for OCR-free document understanding. In this paper, we propose mPLUG-DocOwl based on mPLUG-Owl for OCR-free document understanding. Specifically, we first construct a instruction tuning dataset featuring a wide range of visual-text understanding tasks. Then, we strengthen the OCR-free document understanding ability by jointly train the model on language-only, general vision-and-language, and document instruction tuning dataset with our unified instruction tuning strategy. We also build an OCR-free document instruction understanding evaluation set LLMDoc to better compare models' capabilities on instruct compliance and document understanding. Experimental results show that our model outperforms existing multi-modal models, demonstrating its strong ability of document understanding. Besides, without specific fine-tuning, mPLUG-DocOwl generalizes well on various downstream tasks. Our code, models, training data and evaluation set are available at https://github.com/X-PLUG/mPLUG-DocOwl.
ChatPLUG: Open-Domain Generative Dialogue System with Internet-Augmented Instruction Tuning for Digital Human
Apr 28, 2023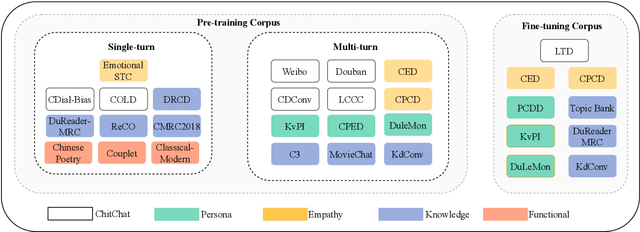

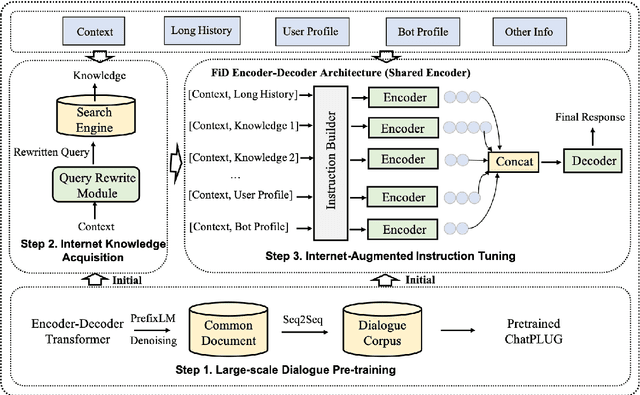
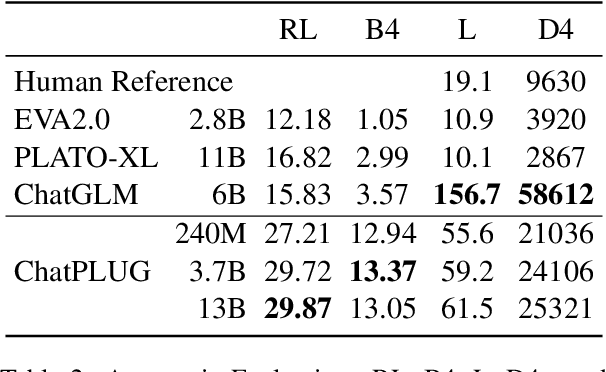
In this paper, we present ChatPLUG, a Chinese open-domain dialogue system for digital human applications that instruction finetunes on a wide range of dialogue tasks in a unified internet-augmented format. Different from other open-domain dialogue models that focus on large-scale pre-training and scaling up model size or dialogue corpus, we aim to build a powerful and practical dialogue system for digital human with diverse skills and good multi-task generalization by internet-augmented instruction tuning. To this end, we first conduct large-scale pre-training on both common document corpus and dialogue data with curriculum learning, so as to inject various world knowledge and dialogue abilities into ChatPLUG. Then, we collect a wide range of dialogue tasks spanning diverse features of knowledge, personality, multi-turn memory, and empathy, on which we further instruction tune \modelname via unified natural language instruction templates. External knowledge from an internet search is also used during instruction finetuning for alleviating the problem of knowledge hallucinations. We show that \modelname outperforms state-of-the-art Chinese dialogue systems on both automatic and human evaluation, and demonstrates strong multi-task generalization on a variety of text understanding and generation tasks. In addition, we deploy \modelname to real-world applications such as Smart Speaker and Instant Message applications with fast inference. Our models and code will be made publicly available on ModelScope~\footnote{\small{https://modelscope.cn/models/damo/ChatPLUG-3.7B}} and Github~\footnote{\small{https://github.com/X-PLUG/ChatPLUG}}.