 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Comparative Logical Relation with Contrastive Learning for Text Generation
Paper and Code
Jun 13, 2024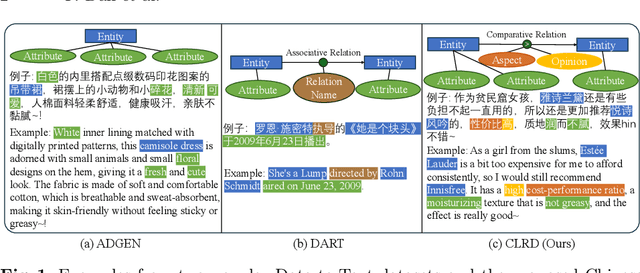
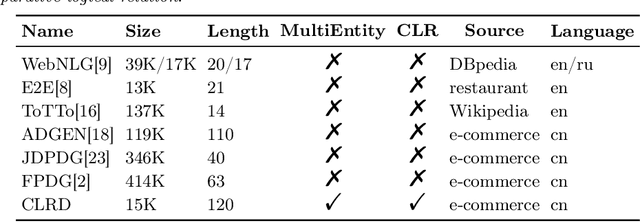
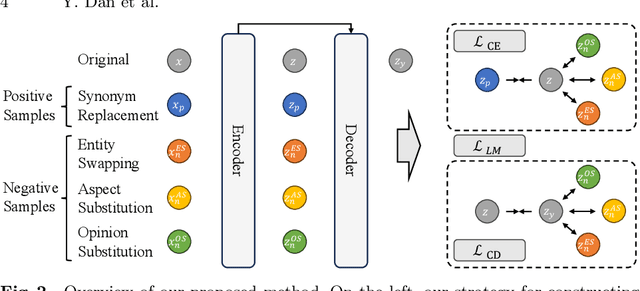
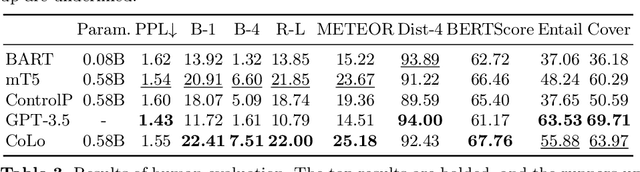
Data-to-Text Generation (D2T), a classic natural language generation problem, aims at producing fluent descriptions for structured input data, such as a table. Existing D2T works mainly focus on describing the superficial associative relations among entities, while ignoring the deep comparative logical relations, such as A is better than B in a certain aspect with a corresponding opinion, which is quite common in our daily life. In this paper, we introduce a new D2T task named comparative logical relation generation (CLRG). Additionally, we propose a Comparative Logic (CoLo) based text generation method, which generates texts following specific comparative logical relations with contrastive learning. Specifically, we first construct various positive and negative samples by fine-grained perturbations in entities, aspects and opinions. Then, we perform contrastive learning in the encoder layer to have a better understanding of the comparative logical relations, and integrate it in the decoder layer to guide the model to correctly generate the relations. Noting the data scarcity problem, we construct a Chinese Comparative Logical Relation Dataset (CLRD), which is a high-quality human-annotated dataset and challenging for text generation with descriptions of multiple entities and annotations on their comparative logical relations. Extensive experiments show that our method achieves impressive performance in both automatic and human evaluations.