 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP-Tailor: Customizing Personality Traits for Language Models via Mixture of Specialized LoRA Experts
Jun 18, 2024Personalized large language models (LLMs) have attracted great attention in many applications, such as intelligent education and emotional support. Most work focuses on controlling the character settings based on the profile (e.g., age, skill, experience, and so on). Conversely, the psychological theory-based personality traits with implicit expression and behavior are not well modeled, limiting their potential application in more specialized fields such as the psychological counseling agents. In this paper, we propose a mixture of experts (MoE)-based personalized LLMs, named P-tailor, to model the Big Five Personality Traits. Particularly, we learn specialized LoRA experts to represent various traits, such as openness, conscientiousness, extraversion, agreeableness and neuroticism. Then, we integrate P-Tailor with a personality specialization loss, promoting experts to specialize in distinct personality traits, thereby enhancing the efficiency of model parameter utilization. Due to the lack of datasets, we also curate a high-quality personality crafting dataset (PCD) to learn and develop the ability to exhibit different personality traits across various topics. We conduct extensive experiments to verify the great performance and effectiveness of P-Tailor in manipulation of the fine-grained personality traits of LLMs.
Modeling Comparative Logical Relation with Contrastive Learning for Text Generation
Jun 13, 2024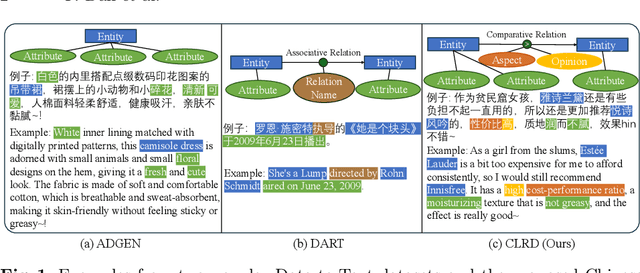
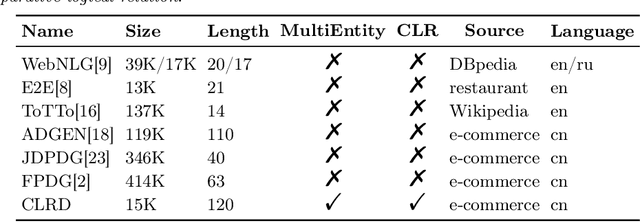
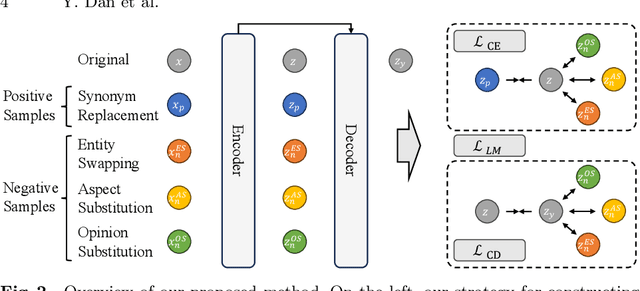
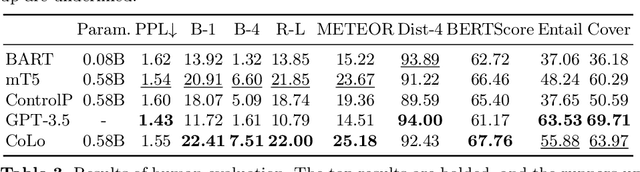
Data-to-Text Generation (D2T), a classic natural language generation problem, aims at producing fluent descriptions for structured input data, such as a table. Existing D2T works mainly focus on describing the superficial associative relations among entities, while ignoring the deep comparative logical relations, such as A is better than B in a certain aspect with a corresponding opinion, which is quite common in our daily life. In this paper, we introduce a new D2T task named comparative logical relation generation (CLRG). Additionally, we propose a Comparative Logic (CoLo) based text generation method, which generates texts following specific comparative logical relations with contrastive learning. Specifically, we first construct various positive and negative samples by fine-grained perturbations in entities, aspects and opinions. Then, we perform contrastive learning in the encoder layer to have a better understanding of the comparative logical relations, and integrate it in the decoder layer to guide the model to correctly generate the relations. Noting the data scarcity problem, we construct a Chinese Comparative Logical Relation Dataset (CLRD), which is a high-quality human-annotated dataset and challenging for text generation with descriptions of multiple entities and annotations on their comparative logical relations. Extensive experiments show that our method achieves impressive performance in both automatic and human evaluations.
EduChat: A Large-Scale Language Model-based Chatbot System for Intelligent Education
Aug 05, 2023



EduChat (https://www.educhat.top/) is a large-scale language model (LLM)-based chatbot system in the education domain. Its goal is to support personalized, fair, and compassionate intelligent education, serving teachers, students, and parents. Guided by theories from psychology and education, it further strengthens educational functions such as open question answering, essay assessment, Socratic teaching, and emotional support based on the existing basic LLMs. Particularly, we learn domain-specific knowledge by pre-training on the educational corpus and stimulate various skills with tool use by fine-tuning on designed system prompts and instructions. Currently, EduChat is available online as an open-source project, with its code, data, and model parameters available on platforms (e.g., GitHub https://github.com/icalk-nlp/EduChat, Hugging Face https://huggingface.co/ecnu-icalk ). We also prepare a demonstration of its capabilities online (https://vimeo.com/851004454). This initiative aims to promote research and applications of LLMs for intelligent education.
mPLUG-DocOwl: Modularized Multimodal Large Language Model for Document Understanding
Jul 04, 2023



Document understanding refers to automatically extract, analyze and comprehend information from various types of digital documents, such as a web page. Existing Multi-model Large Language Models (MLLMs), including mPLUG-Owl, have demonstrated promising zero-shot capabilities in shallow OCR-free text recognition, indicating their potential for OCR-free document understanding. Nevertheless, without in-domain training, these models tend to ignore fine-grained OCR features, such as sophisticated tables or large blocks of text, which are essential for OCR-free document understanding. In this paper, we propose mPLUG-DocOwl based on mPLUG-Owl for OCR-free document understanding. Specifically, we first construct a instruction tuning dataset featuring a wide range of visual-text understanding tasks. Then, we strengthen the OCR-free document understanding ability by jointly train the model on language-only, general vision-and-language, and document instruction tuning dataset with our unified instruction tuning strategy. We also build an OCR-free document instruction understanding evaluation set LLMDoc to better compare models' capabilities on instruct compliance and document understanding. Experimental results show that our model outperforms existing multi-modal models, demonstrating its strong ability of document understanding. Besides, without specific fine-tuning, mPLUG-DocOwl generalizes well on various downstream tasks. Our code, models, training data and evaluation set are available at https://github.com/X-PLUG/mPLUG-DocOwl.