 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation and Analysis of Hallucination in Large Vision-Language Models
Aug 29, 2023

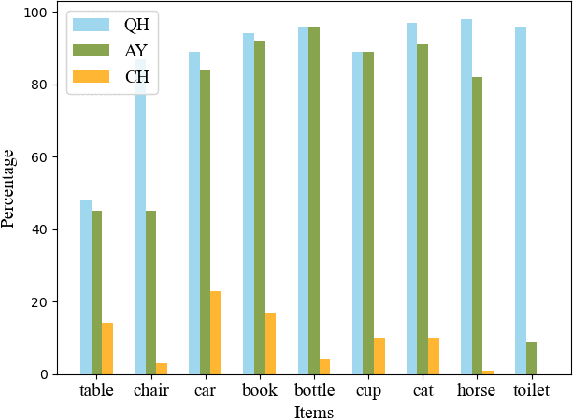
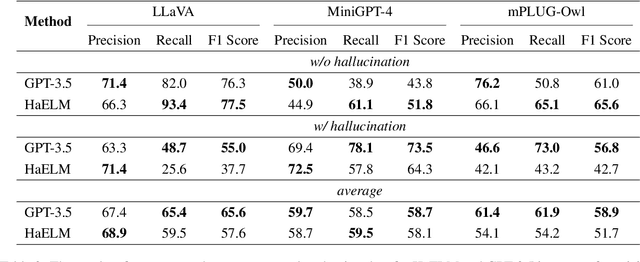
Large Vision-Language Models (LVLMs) have recently achieved remarkable success. However, LVLMs are still plagued by the hallucination problem, which limits the practicality in many scenarios. Hallucination refers to the information of LVLMs' responses that does not exist in the visual input, which poses potential risks of substantial consequences. There has been limited work studying hallucination evaluation in LVLMs. In this paper, we propose Hallucination Evaluation based on Large Language Models (HaELM), an LLM-based hallucination evaluation framework. HaELM achieves an approximate 95% performance comparable to ChatGPT and has additional advantages including low cost, reproducibility, privacy preservation and local deployment. Leveraging the HaELM, we evaluate the hallucination in current LVLMs. Furthermore, we analyze the factors contributing to hallucination in LVLMs and offer helpful suggestions to mitigate the hallucination problem. Our training data and human annotation hallucination data will be made public soon.
Overlap Bias Matching is Necessary for Point Cloud Registration
Aug 18, 2023



Point cloud registration is a fundamental problem in many domains. Practically, the overlap between point clouds to be registered may be relatively small. Most unsupervised methods lack effective initial evaluation of overlap, leading to suboptimal registration accuracy. To address this issue, we propose an unsupervised network Overlap Bias Matching Network (OBMNet) for partial point cloud registration. Specifically, we propose a plug-and-play Overlap Bias Matching Module (OBMM) comprising two integral components, overlap sampling module and bias prediction module. These two components are utilized to capture the distribution of overlapping regions and predict bias coefficients of point cloud common structures, respectively. Then, we integrate OBMM with the neighbor map matching module to robustly identify correspondences by precisely merging matching scores of points within the neighborhood, which addresses the ambiguities in single-point features. OBMNet can maintain efficacy even in pair-wise registration scenarios with low overlap ratios. Experimental results on extensive datasets demonstrate that our approach's performance achieves a significant improvement compared to the state-of-the-art registration approach.
mPLUG-DocOwl: Modularized Multimodal Large Language Model for Document Understanding
Jul 04, 2023



Document understanding refers to automatically extract, analyze and comprehend information from various types of digital documents, such as a web page. Existing Multi-model Large Language Models (MLLMs), including mPLUG-Owl, have demonstrated promising zero-shot capabilities in shallow OCR-free text recognition, indicating their potential for OCR-free document understanding. Nevertheless, without in-domain training, these models tend to ignore fine-grained OCR features, such as sophisticated tables or large blocks of text, which are essential for OCR-free document understanding. In this paper, we propose mPLUG-DocOwl based on mPLUG-Owl for OCR-free document understanding. Specifically, we first construct a instruction tuning dataset featuring a wide range of visual-text understanding tasks. Then, we strengthen the OCR-free document understanding ability by jointly train the model on language-only, general vision-and-language, and document instruction tuning dataset with our unified instruction tuning strategy. We also build an OCR-free document instruction understanding evaluation set LLMDoc to better compare models' capabilities on instruct compliance and document understanding. Experimental results show that our model outperforms existing multi-modal models, demonstrating its strong ability of document understanding. Besides, without specific fine-tuning, mPLUG-DocOwl generalizes well on various downstream tasks. Our code, models, training data and evaluation set are available at https://github.com/X-PLUG/mPLUG-DocOwl.