 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign then Adapt: Rethinking Parameter-Efficient Transfer Learning in 4D Perception
Feb 26, 2026Point cloud video understanding is critical for robotics as it accurately encodes motion and scene interaction. We recognize that 4D datasets are far scarcer than 3D ones, which hampers the scalability of self-supervised 4D models. A promising alternative is to transfer 3D pre-trained models to 4D perception tasks. However, rigorous empirical analysis reveals two critical limitations that impede transfer capability: overfitting and the modality gap. To overcome these challenges, we develop a novel "Align then Adapt" (PointATA) paradigm that decomposes parameter-efficient transfer learning into two sequential stages. Optimal-transport theory is employed to quantify the distributional discrepancy between 3D and 4D datasets, enabling our proposed point align embedder to be trained in Stage 1 to alleviate the underlying modality gap. To mitigate overfitting, an efficient point-video adapter and a spatial-context encoder are integrated into the frozen 3D backbone to enhance temporal modeling capacity in Stage 2. Notably, with the above engineering-oriented designs, PointATA enables a pre-trained 3D model without temporal knowledge to reason about dynamic video content at a smaller parameter cost compared to previous work. Extensive experiments show that PointATA can match or even outperform strong full fine-tuning models, whilst enjoying the advantage of parameter efficiency, e.g. 97.21 \% accuracy on 3D action recognition, $+8.7 \%$ on 4 D action segmentation, and 84.06\% on 4D semantic segmentation.
Point-SRA: Self-Representation Alignment for 3D Representation Learning
Jan 05, 2026Masked autoencoders (MAE) have become a dominant paradigm in 3D representation learning, setting new performance benchmarks across various downstream tasks. Existing methods with fixed mask ratio neglect multi-level representational correlations and intrinsic geometric structures, while relying on point-wise reconstruction assumptions that conflict with the diversity of point cloud. To address these issues, we propose a 3D representation learning method, termed Point-SRA, which aligns representations through self-distillation and probabilistic modeling. Specifically, we assign different masking ratios to the MAE to capture complementary geometric and semantic information, while the MeanFlow Transformer (MFT) leverages cross-modal conditional embeddings to enable diverse probabilistic reconstruction. Our analysis further reveals that representations at different time steps in MFT also exhibit complementarity. Therefore, a Dual Self-Representation Alignment mechanism is proposed at both the MAE and MFT levels. Finally, we design a Flow-Conditioned Fine-Tuning Architecture to fully exploit the point cloud distribution learned via MeanFlow. Point-SRA outperforms Point-MAE by 5.37% on ScanObjectNN. On intracranial aneurysm segmentation, it reaches 96.07% mean IoU for arteries and 86.87% for aneurysms. For 3D object detection, Point-SRA achieves 47.3% AP@50, surpassing MaskPoint by 5.12%.
PointDico: Contrastive 3D Representation Learning Guided by Diffusion Models
Dec 09, 2025Self-supervised representation learning has shown significant improvement in Natural Language Processing and 2D Computer Vision. However, existing methods face difficulties in representing 3D data because of its unordered and uneven density. Through an in-depth analysis of mainstream contrastive and generative approaches, we find that contrastive models tend to suffer from overfitting, while 3D Mask Autoencoders struggle to handle unordered point clouds. This motivates us to learn 3D representations by sharing the merits of diffusion and contrast models, which is non-trivial due to the pattern difference between the two paradigms. In this paper, we propose \textit{PointDico}, a novel model that seamlessly integrates these methods. \textit{PointDico} learns from both denoising generative modeling and cross-modal contrastive learning through knowledge distillation, where the diffusion model serves as a guide for the contrastive model. We introduce a hierarchical pyramid conditional generator for multi-scale geometric feature extraction and employ a dual-channel design to effectively integrate local and global contextual information. \textit{PointDico} achieves a new state-of-the-art in 3D representation learning, \textit{e.g.}, \textbf{94.32\%} accuracy on ScanObjectNN, \textbf{86.5\%} Inst. mIoU on ShapeNetPart.
Hyperbolic Image-and-Pointcloud Contrastive Learning for 3D Classification
Sep 24, 2024



3D contrastive representation learning has exhibited remarkable efficacy across various downstream tasks. However, existing contrastive learning paradigms based on cosine similarity fail to deeply explore the potential intra-modal hierarchical and cross-modal semantic correlations about multi-modal data in Euclidean space. In response, we seek solutions in hyperbolic space and propose a hyperbolic image-and-pointcloud contrastive learning method (HyperIPC). For the intra-modal branch, we rely on the intrinsic geometric structure to explore the hyperbolic embedding representation of point cloud to capture invariant features. For the cross-modal branch, we leverage images to guide the point cloud in establishing strong semantic hierarchical correlations. Empirical experiments underscore the outstanding classification performance of HyperIPC. Notably, HyperIPC enhances object classification results by 2.8% and few-shot classification outcomes by 5.9% on ScanObjectNN compared to the baseline. Furthermore, ablation studies and confirmatory testing validate the rationality of HyperIPC's parameter settings and the effectiveness of its submodules.
3D-JEPA: A Joint Embedding Predictive Architecture for 3D Self-Supervised Representation Learning
Sep 24, 2024Invariance-based and generative methods have shown a conspicuous performance for 3D self-supervised representation learning (SSRL). However, the former relies on hand-crafted data augmentations that introduce bias not universally applicable to all downstream tasks, and the latter indiscriminately reconstructs masked regions, resulting in irrelevant details being saved in the representation space. To solve the problem above, we introduce 3D-JEPA, a novel non-generative 3D SSRL framework. Specifically, we propose a multi-block sampling strategy that produces a sufficiently informative context block and several representative target blocks. We present the context-aware decoder to enhance the reconstruction of the target blocks. Concretely, the context information is fed to the decoder continuously, facilitating the encoder in learning semantic modeling rather than memorizing the context information related to target blocks. Overall, 3D-JEPA predicts the representation of target blocks from a context block using the encoder and context-aware decoder architecture. Various downstream tasks on different datasets demonstrate 3D-JEPA's effectiveness and efficiency, achieving higher accuracy with fewer pretraining epochs, e.g., 88.65% accuracy on PB_T50_RS with 150 pretraining epochs.
DENOISER: Rethinking the Robustness for Open-Vocabulary Action Recognition
Apr 23, 2024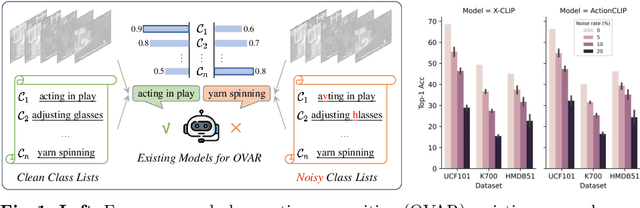
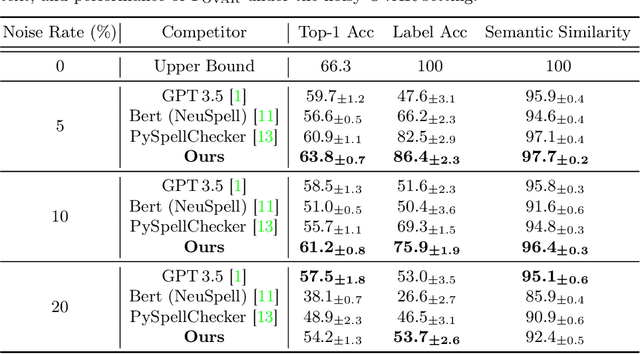
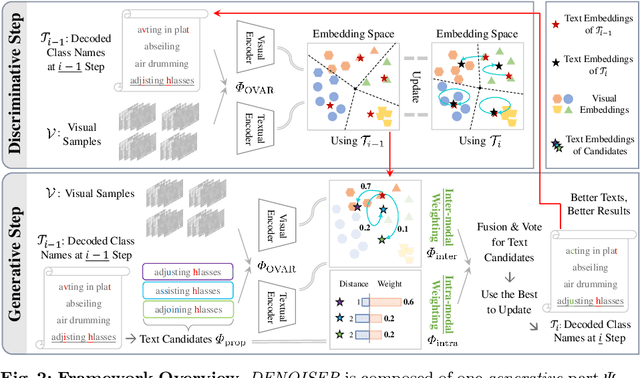
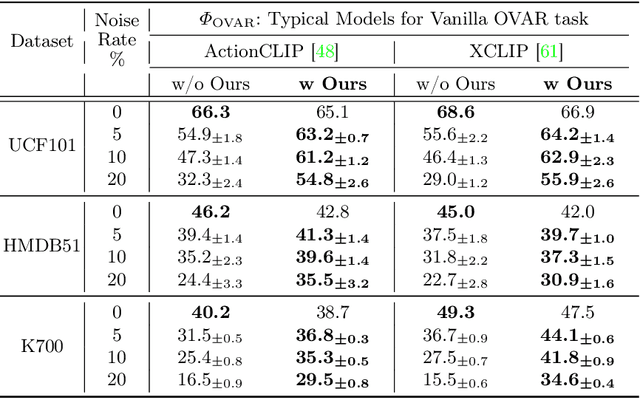
As one of the fundamental video tasks in computer vision, Open-Vocabulary Action Recognition (OVAR) recently gains increasing attention, with the development of vision-language pre-trainings. To enable generalization of arbitrary classes, existing methods treat class labels as text descriptions, then formulate OVAR as evaluating embedding similarity between visual samples and textual classes. However, one crucial issue is completely ignored: the class descriptions given by users may be noisy, e.g., misspellings and typos, limiting the real-world practicality of vanilla OVAR. To fill the research gap, this paper pioneers to evaluate existing methods by simulating multi-level noises of various types, and reveals their poor robustness. To tackle the noisy OVAR task, we further propose one novel DENOISER framework, covering two parts: generation and discrimination. Concretely, the generative part denoises noisy class-text names via one decoding process, i.e., propose text candidates, then utilize inter-modal and intra-modal information to vote for the best. At the discriminative part, we use vanilla OVAR models to assign visual samples to class-text names, thus obtaining more semantics. For optimization, we alternately iterate between generative and discriminative parts for progressive refinements. The denoised text classes help OVAR models classify visual samples more accurately; in return, classified visual samples help better denoising. On three datasets, we carry out extensive experiments to show our superior robustness, and thorough ablations to dissect the effectiveness of each component.
Overlap Bias Matching is Necessary for Point Cloud Registration
Aug 18, 2023



Point cloud registration is a fundamental problem in many domains. Practically, the overlap between point clouds to be registered may be relatively small. Most unsupervised methods lack effective initial evaluation of overlap, leading to suboptimal registration accuracy. To address this issue, we propose an unsupervised network Overlap Bias Matching Network (OBMNet) for partial point cloud registration. Specifically, we propose a plug-and-play Overlap Bias Matching Module (OBMM) comprising two integral components, overlap sampling module and bias prediction module. These two components are utilized to capture the distribution of overlapping regions and predict bias coefficients of point cloud common structures, respectively. Then, we integrate OBMM with the neighbor map matching module to robustly identify correspondences by precisely merging matching scores of points within the neighborhood, which addresses the ambiguities in single-point features. OBMNet can maintain efficacy even in pair-wise registration scenarios with low overlap ratios. Experimental results on extensive datasets demonstrate that our approach's performance achieves a significant improvement compared to the state-of-the-art registration approach.
DualGenerator: Information Interaction-based Generative Network for Point Cloud Completion
May 16, 2023Point cloud completion estimates complete shapes from incomplete point clouds to obtain higher-quality point cloud data. Most existing methods only consider global object features, ignoring spatial and semantic information of adjacent points. They cannot distinguish structural information well between different object parts, and the robustness of models is poor. To tackle these challenges, we propose an information interaction-based generative network for point cloud completion ($\mathbf{DualGenerator}$). It contains an adversarial generation path and a variational generation path, which interact with each other and share weights. DualGenerator introduces a local refinement module in generation paths, which captures general structures from partial inputs, and then refines shape details of the point cloud. It promotes completion in the unknown region and makes a distinction between different parts more obvious. Moreover, we design DGStyleGAN to improve the generation quality further. It promotes the robustness of this network combined with fusion analysis of dual-path completion results. Qualitative and quantitative evaluations demonstrate that our method is superior on MVP and Completion3D datasets. The performance will not degrade significantly after adding noise interference or sparse sampling.