 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDFBench: A Benchmark for De novo Protein Design from Function
May 25, 2025In recent years, while natural language processing and multimodal learning have seen rapid advancements, the field of de novo protein design has also experienced significant growth. However, most current methods rely on proprietary datasets and evaluation rubrics, making fair comparisons between different approaches challenging. Moreover, these methods often employ evaluation metrics that capture only a subset of the desired properties of designed proteins, lacking a comprehensive assessment framework. To address these, we introduce PDFBench, the first comprehensive benchmark for evaluating de novo protein design from function. PDFBench supports two tasks: description-guided design and keyword-guided design. To ensure fair and multifaceted evaluation, we compile 22 metrics covering sequence plausibility, structural fidelity, and language-protein alignment, along with measures of novelty and diversity. We evaluate five state-of-the-art baselines, revealing their respective strengths and weaknesses across tasks. Finally, we analyze inter-metric correlations, exploring the relationships between four categories of metrics, and offering guidelines for metric selection. PDFBench establishes a unified framework to drive future advances in function-driven de novo protein design.
Protein Design with Dynamic Protein Vocabulary
May 25, 2025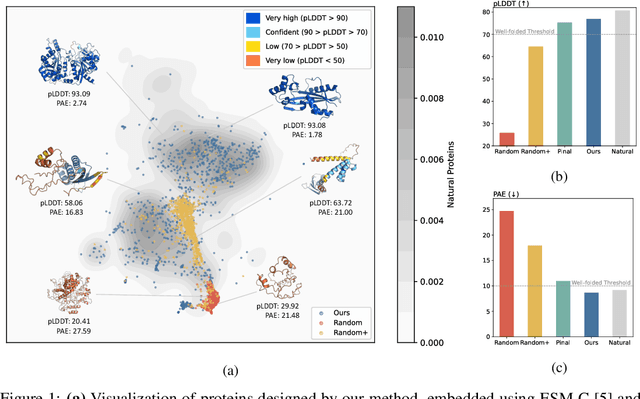
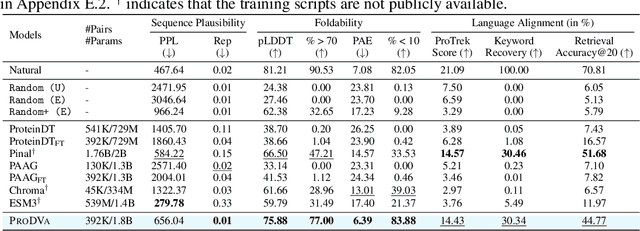
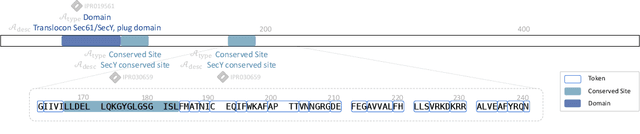
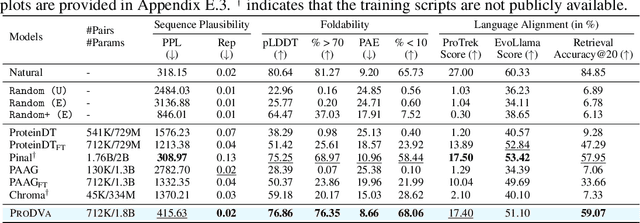
Protein design is a fundamental challenge in biotechnology, aiming to design novel sequences with specific functions within the vast space of possible proteins. Recent advances in deep generative models have enabled function-based protein design from textual descriptions, yet struggle with structural plausibility. Inspired by classical protein design methods that leverage natural protein structures, we explore whether incorporating fragments from natural proteins can enhance foldability in generative models. Our empirical results show that even random incorporation of fragments improves foldability. Building on this insight, we introduce ProDVa, a novel protein design approach that integrates a text encoder for functional descriptions, a protein language model for designing proteins, and a fragment encoder to dynamically retrieve protein fragments based on textual functional descriptions. Experimental results demonstrate that our approach effectively designs protein sequences that are both functionally aligned and structurally plausible. Compared to state-of-the-art models, ProDVa achieves comparable function alignment using less than 0.04% of the training data, while designing significantly more well-folded proteins, with the proportion of proteins having pLDDT above 70 increasing by 7.38% and those with PAE below 10 increasing by 9.6%.
EvoLlama: Enhancing LLMs' Understanding of Proteins via Multimodal Structure and Sequence Representations
Dec 16, 2024



Current Large Language Models (LLMs) for understanding proteins primarily treats amino acid sequences as a text modality. Meanwhile, Protein Language Models (PLMs), such as ESM-2, have learned massive sequential evolutionary knowledge from the universe of natural protein sequences. Furthermore, structure-based encoders like ProteinMPNN learn the structural information of proteins through Graph Neural Networks. However, whether the incorporation of protein encoders can enhance the protein understanding of LLMs has not been explored. To bridge this gap, we propose EvoLlama, a multimodal framework that connects a structure-based encoder, a sequence-based protein encoder and an LLM for protein understanding. EvoLlama consists of a ProteinMPNN structure encoder, an ESM-2 protein sequence encoder, a multimodal projector to align protein and text representations and a Llama-3 text decoder. To train EvoLlama, we fine-tune it on protein-oriented instructions and protein property prediction datasets verbalized via natural language instruction templates. Our experiments show that EvoLlama's protein understanding capabilities have been significantly enhanced, outperforming other fine-tuned protein-oriented LLMs in zero-shot settings by an average of 1%-8% and surpassing the state-of-the-art baseline with supervised fine-tuning by an average of 6%. On protein property prediction datasets, our approach achieves promising results that are competitive with state-of-the-art task-specific baselines. We will release our code in a future version.
CERD: A Comprehensive Chinese Rhetoric Dataset for Rhetorical Understanding and Generation in Essays
Sep 29, 2024



Existing rhetorical understanding and generation datasets or corpora primarily focus on single coarse-grained categories or fine-grained categories, neglecting the common interrelations between different rhetorical devices by treating them as independent sub-tasks. In this paper, we propose the Chinese Essay Rhetoric Dataset (CERD), consisting of 4 commonly used coarse-grained categories including metaphor, personification, hyperbole and parallelism and 23 fine-grained categories across both form and content levels. CERD is a manually annotated and comprehensive Chinese rhetoric dataset with five interrelated sub-tasks. Unlike previous work, our dataset aids in understanding various rhetorical devices, recognizing corresponding rhetorical components, and generating rhetorical sentences under given conditions, thereby improving the author's writing proficiency and language usage skills. Extensive experiments are conducted to demonstrate the interrelations between multiple tasks in CERD, as well as to establish a benchmark for future research on rhetoric. The experimental results indicate that Large Language Models achieve the best performance across most tasks, and jointly fine-tuning with multiple tasks further enhances performance.