 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Heuristics: A Decision-Theoretic Framework for Agent Memory Management
Dec 25, 2025External memory is a key component of modern large language model (LLM) systems, enabling long-term interaction and personalization. Despite its importance, memory management is still largely driven by hand-designed heuristics, offering little insight into the long-term and uncertain consequences of memory decisions. In practice, choices about what to read or write shape future retrieval and downstream behavior in ways that are difficult to anticipate. We argue that memory management should be viewed as a sequential decision-making problem under uncertainty, where the utility of memory is delayed and dependent on future interactions. To this end, we propose DAM (Decision-theoretic Agent Memory), a decision-theoretic framework that decomposes memory management into immediate information access and hierarchical storage maintenance. Within this architecture, candidate operations are evaluated via value functions and uncertainty estimators, enabling an aggregate policy to arbitrate decisions based on estimated long-term utility and risk. Our contribution is not a new algorithm, but a principled reframing that clarifies the limitations of heuristic approaches and provides a foundation for future research on uncertainty-aware memory systems.
Protein Design with Dynamic Protein Vocabulary
May 25, 2025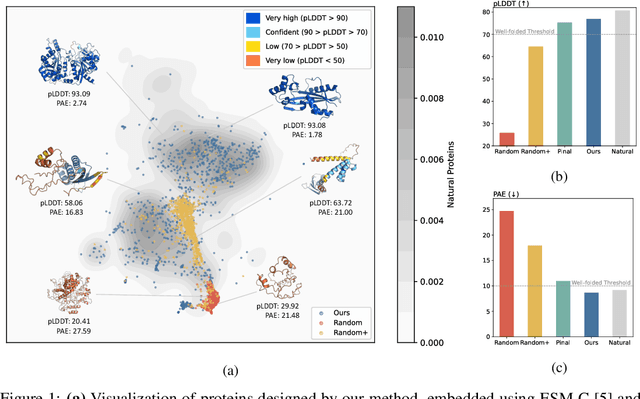
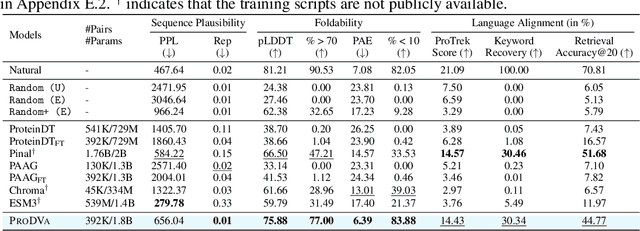
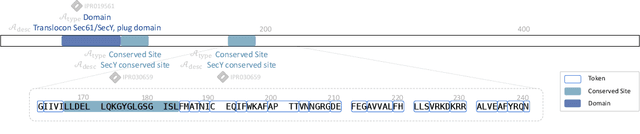
Protein design is a fundamental challenge in biotechnology, aiming to design novel sequences with specific functions within the vast space of possible proteins. Recent advances in deep generative models have enabled function-based protein design from textual descriptions, yet struggle with structural plausibility. Inspired by classical protein design methods that leverage natural protein structures, we explore whether incorporating fragments from natural proteins can enhance foldability in generative models. Our empirical results show that even random incorporation of fragments improves foldability. Building on this insight, we introduce ProDVa, a novel protein design approach that integrates a text encoder for functional descriptions, a protein language model for designing proteins, and a fragment encoder to dynamically retrieve protein fragments based on textual functional descriptions. Experimental results demonstrate that our approach effectively designs protein sequences that are both functionally aligned and structurally plausible. Compared to state-of-the-art models, ProDVa achieves comparable function alignment using less than 0.04% of the training data, while designing significantly more well-folded proteins, with the proportion of proteins having pLDDT above 70 increasing by 7.38% and those with PAE below 10 increasing by 9.6%.
PDFBench: A Benchmark for De novo Protein Design from Function
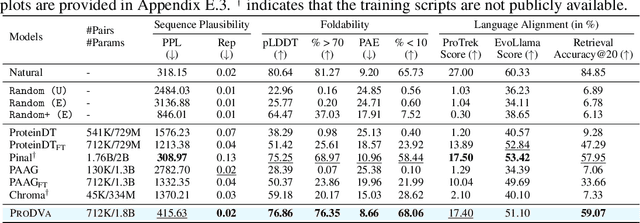
May 25, 2025In recent years, while natural language processing and multimodal learning have seen rapid advancements, the field of de novo protein design has also experienced significant growth. However, most current methods rely on proprietary datasets and evaluation rubrics, making fair comparisons between different approaches challenging. Moreover, these methods often employ evaluation metrics that capture only a subset of the desired properties of designed proteins, lacking a comprehensive assessment framework. To address these, we introduce PDFBench, the first comprehensive benchmark for evaluating de novo protein design from function. PDFBench supports two tasks: description-guided design and keyword-guided design. To ensure fair and multifaceted evaluation, we compile 22 metrics covering sequence plausibility, structural fidelity, and language-protein alignment, along with measures of novelty and diversity. We evaluate five state-of-the-art baselines, revealing their respective strengths and weaknesses across tasks. Finally, we analyze inter-metric correlations, exploring the relationships between four categories of metrics, and offering guidelines for metric selection. PDFBench establishes a unified framework to drive future advances in function-driven de novo protein design.
EvoLlama: Enhancing LLMs' Understanding of Proteins via Multimodal Structure and Sequence Representations
Dec 16, 2024



Current Large Language Models (LLMs) for understanding proteins primarily treats amino acid sequences as a text modality. Meanwhile, Protein Language Models (PLMs), such as ESM-2, have learned massive sequential evolutionary knowledge from the universe of natural protein sequences. Furthermore, structure-based encoders like ProteinMPNN learn the structural information of proteins through Graph Neural Networks. However, whether the incorporation of protein encoders can enhance the protein understanding of LLMs has not been explored. To bridge this gap, we propose EvoLlama, a multimodal framework that connects a structure-based encoder, a sequence-based protein encoder and an LLM for protein understanding. EvoLlama consists of a ProteinMPNN structure encoder, an ESM-2 protein sequence encoder, a multimodal projector to align protein and text representations and a Llama-3 text decoder. To train EvoLlama, we fine-tune it on protein-oriented instructions and protein property prediction datasets verbalized via natural language instruction templates. Our experiments show that EvoLlama's protein understanding capabilities have been significantly enhanced, outperforming other fine-tuned protein-oriented LLMs in zero-shot settings by an average of 1%-8% and surpassing the state-of-the-art baseline with supervised fine-tuning by an average of 6%. On protein property prediction datasets, our approach achieves promising results that are competitive with state-of-the-art task-specific baselines. We will release our code in a future version.
Generation with Dynamic Vocabulary
Oct 11, 2024



We introduce a new dynamic vocabulary for language models. It can involve arbitrary text spans during generation. These text spans act as basic generation bricks, akin to tokens in the traditional static vocabularies. We show that, the ability to generate multi-tokens atomically improve both generation quality and efficiency (compared to the standard language model, the MAUVE metric is increased by 25%, the latency is decreased by 20%). The dynamic vocabulary can be deployed in a plug-and-play way, thus is attractive for various downstream applications. For example, we demonstrate that dynamic vocabulary can be applied to different domains in a training-free manner. It also helps to generate reliable citations in question answering tasks (substantially enhancing citation results without compromising answer accuracy).
Investigating and Mitigating Object Hallucinations in Pretrained Vision-Language (CLIP) Models
Oct 04, 2024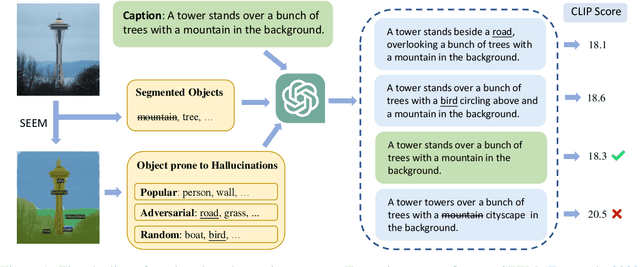
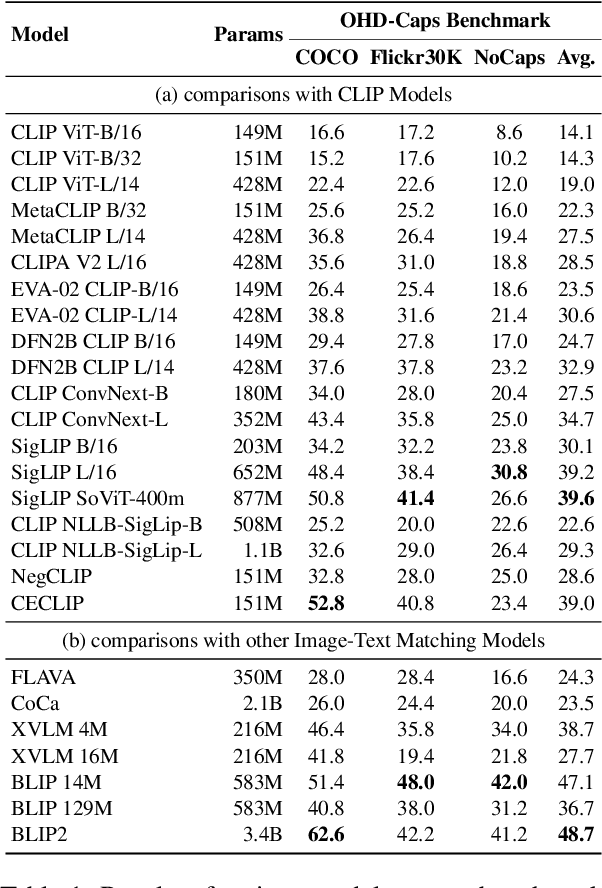
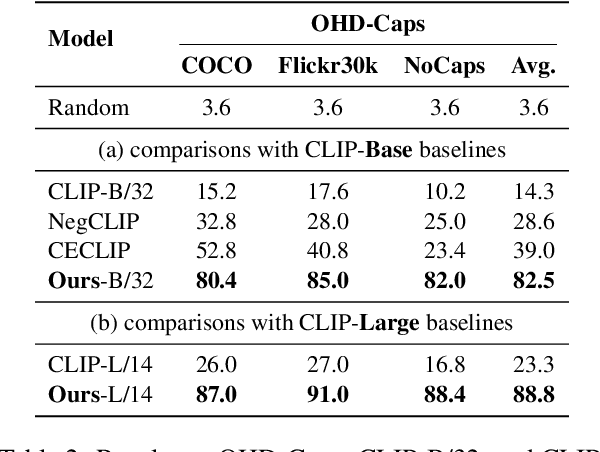
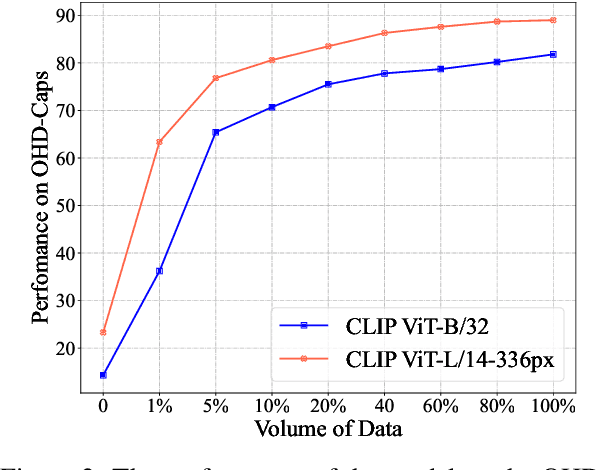
Large Vision-Language Models (LVLMs) have achieved impressive performance, yet research has pointed out a serious issue with object hallucinations within these models. However, there is no clear conclusion as to which part of the model these hallucinations originate from. In this paper, we present an in-depth investigation into the object hallucination problem specifically within the CLIP model, which serves as the backbone for many state-of-the-art vision-language systems. We unveil that even in isolation, the CLIP model is prone to object hallucinations, suggesting that the hallucination problem is not solely due to the interaction between vision and language modalities. To address this, we propose a counterfactual data augmentation method by creating negative samples with a variety of hallucination issues. We demonstrate that our method can effectively mitigate object hallucinations for CLIP model, and we show the the enhanced model can be employed as a visual encoder, effectively alleviating the object hallucination issue in LVLMs.
CERD: A Comprehensive Chinese Rhetoric Dataset for Rhetorical Understanding and Generation in Essays
Sep 29, 2024



Existing rhetorical understanding and generation datasets or corpora primarily focus on single coarse-grained categories or fine-grained categories, neglecting the common interrelations between different rhetorical devices by treating them as independent sub-tasks. In this paper, we propose the Chinese Essay Rhetoric Dataset (CERD), consisting of 4 commonly used coarse-grained categories including metaphor, personification, hyperbole and parallelism and 23 fine-grained categories across both form and content levels. CERD is a manually annotated and comprehensive Chinese rhetoric dataset with five interrelated sub-tasks. Unlike previous work, our dataset aids in understanding various rhetorical devices, recognizing corresponding rhetorical components, and generating rhetorical sentences under given conditions, thereby improving the author's writing proficiency and language usage skills. Extensive experiments are conducted to demonstrate the interrelations between multiple tasks in CERD, as well as to establish a benchmark for future research on rhetoric. The experimental results indicate that Large Language Models achieve the best performance across most tasks, and jointly fine-tuning with multiple tasks further enhances performance.
TCMBench: A Comprehensive Benchmark for Evaluating Large Language Models in Traditional Chinese Medicine
Jun 03, 2024



Large language models (LLMs) have performed remarkably well in various natural language processing tasks by benchmarking, including in the Western medical domain. However, the professional evaluation benchmarks for LLMs have yet to be covered in the traditional Chinese medicine(TCM) domain, which has a profound history and vast influence. To address this research gap, we introduce TCM-Bench, an comprehensive benchmark for evaluating LLM performance in TCM. It comprises the TCM-ED dataset, consisting of 5,473 questions sourced from the TCM Licensing Exam (TCMLE), including 1,300 questions with authoritative analysis. It covers the core components of TCMLE, including TCM basis and clinical practice. To evaluate LLMs beyond accuracy of question answering, we propose TCMScore, a metric tailored for evaluating the quality of answers generated by LLMs for TCM related questions. It comprehensively considers the consistency of TCM semantics and knowledge. After conducting comprehensive experimental analyses from diverse perspectives, we can obtain the following findings: (1) The unsatisfactory performance of LLMs on this benchmark underscores their significant room for improvement in TCM. (2) Introducing domain knowledge can enhance LLMs' performance. However, for in-domain models like ZhongJing-TCM, the quality of generated analysis text has decreased, and we hypothesize that their fine-tuning process affects the basic LLM capabilities. (3) Traditional metrics for text generation quality like Rouge and BertScore are susceptible to text length and surface semantic ambiguity, while domain-specific metrics such as TCMScore can further supplement and explain their evaluation results. These findings highlight the capabilities and limitations of LLMs in the TCM and aim to provide a more profound assistance to medical research.
Unlearning with Fisher Masking
Oct 09, 2023



Machine unlearning aims to revoke some training data after learning in response to requests from users, model developers, and administrators. Most previous methods are based on direct fine-tuning, which may neither remove data completely nor retain full performances on the remain data. In this work, we find that, by first masking some important parameters before fine-tuning, the performances of unlearning could be significantly improved. We propose a new masking strategy tailored to unlearning based on Fisher information. Experiments on various datasets and network structures show the effectiveness of the method: without any fine-tuning, the proposed Fisher masking could unlearn almost completely while maintaining most of the performance on the remain data. It also exhibits stronger stability compared to other unlearning baselines
ANALOGYKB: Unlocking Analogical Reasoning of Language Models with A Million-scale Knowledge Base
May 10, 2023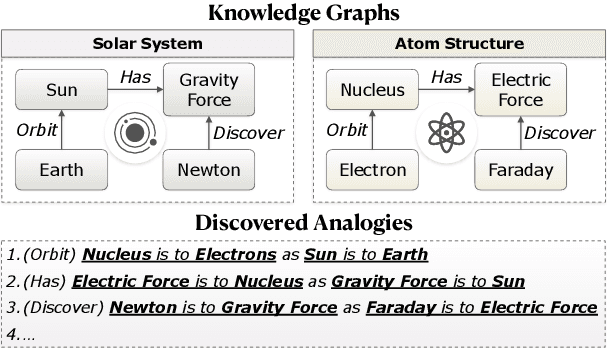


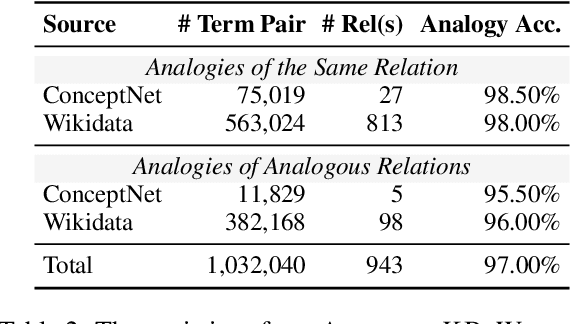
Analogical reasoning is a fundamental cognitive ability of humans. However, current language models (LMs) still struggle to achieve human-like performance in analogical reasoning tasks due to a lack of resources for model training. In this work, we address this gap by proposing ANALOGYKB, a million-scale analogy knowledge base (KB) derived from existing knowledge graphs (KGs). ANALOGYKB identifies two types of analogies from the KGs: 1) analogies of the same relations, which can be directly extracted from the KGs, and 2) analogies of analogous relations, which are identified with a selection and filtering pipeline enabled by large LMs (InstructGPT), followed by minor human efforts for data quality control. Evaluations on a series of datasets of two analogical reasoning tasks (analogy recognition and generation) demonstrate that ANALOGYKB successfully enables LMs to achieve much better results than previous state-of-the-art methods.