 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurse of Knowledge: When Complex Evaluation Context Benefits yet Biases LLM Judges
Sep 03, 2025As large language models (LLMs) grow more capable, they face increasingly diverse and complex tasks, making reliable evaluation challenging. The paradigm of LLMs as judges has emerged as a scalable solution, yet prior work primarily focuses on simple settings. Their reliability in complex tasks--where multi-faceted rubrics, unstructured reference answers, and nuanced criteria are critical--remains understudied. In this paper, we constructed ComplexEval, a challenge benchmark designed to systematically expose and quantify Auxiliary Information Induced Biases. We systematically investigated and validated 6 previously unexplored biases across 12 basic and 3 advanced scenarios. Key findings reveal: (1) all evaluated models exhibit significant susceptibility to these biases, with bias magnitude scaling with task complexity; (2) notably, Large Reasoning Models (LRMs) show paradoxical vulnerability. Our in-depth analysis offers crucial insights for improving the accuracy and verifiability of evaluation signals, paving the way for more general and robust evaluation models.
ThinkDial: An Open Recipe for Controlling Reasoning Effort in Large Language Models
Aug 26, 2025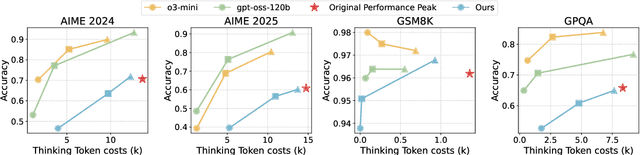
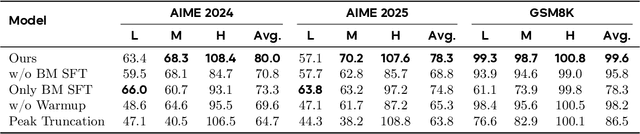
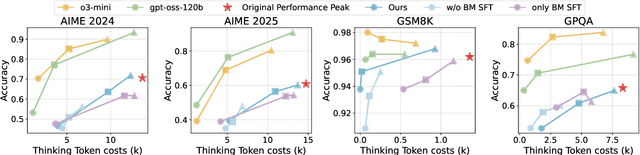

Large language models (LLMs) with chain-of-thought reasoning have demonstrated remarkable problem-solving capabilities, but controlling their computational effort remains a significant challenge for practical deployment. Recent proprietary systems like OpenAI's gpt-oss series have introduced discrete operational modes for intuitive reasoning control, but the open-source community has largely failed to achieve such capabilities. In this paper, we introduce ThinkDial, the first open-recipe end-to-end framework that successfully implements gpt-oss-style controllable reasoning through discrete operational modes. Our system enables seamless switching between three distinct reasoning regimes: High mode (full reasoning capability), Medium mode (50 percent token reduction with <10 percent performance degradation), and Low mode (75 percent token reduction with <15 percent performance degradation). We achieve this through an end-to-end training paradigm that integrates budget-mode control throughout the entire pipeline: budget-mode supervised fine-tuning that embeds controllable reasoning capabilities directly into the learning process, and two-phase budget-aware reinforcement learning with adaptive reward shaping. Extensive experiments demonstrate that ThinkDial achieves target compression-performance trade-offs with clear response length reductions while maintaining performance thresholds. The framework also exhibits strong generalization capabilities on out-of-distribution tasks.
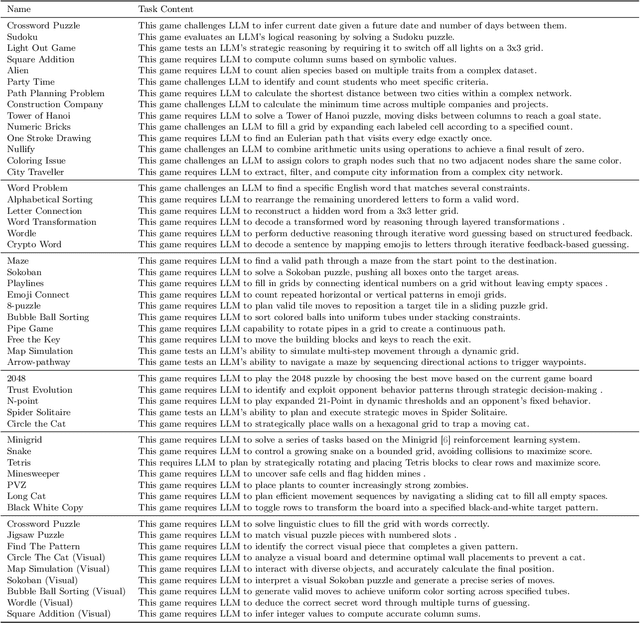
Enigmata: Scaling Logical Reasoning in Large Language Models with Synthetic Verifiable Puzzles
May 26, 2025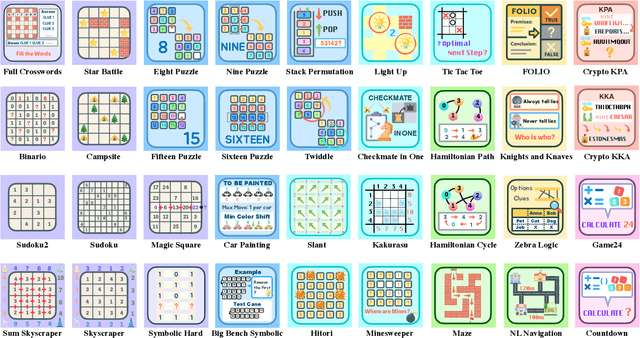
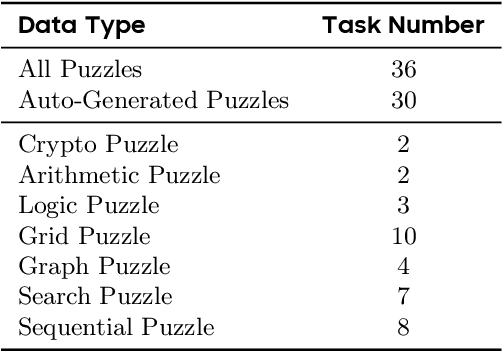

Large Language Models (LLMs), such as OpenAI's o1 and DeepSeek's R1, excel at advanced reasoning tasks like math and coding via Reinforcement Learning with Verifiable Rewards (RLVR), but still struggle with puzzles solvable by humans without domain knowledge. We introduce Enigmata, the first comprehensive suite tailored for improving LLMs with puzzle reasoning skills. It includes 36 tasks across seven categories, each with 1) a generator that produces unlimited examples with controllable difficulty and 2) a rule-based verifier for automatic evaluation. This generator-verifier design supports scalable, multi-task RL training, fine-grained analysis, and seamless RLVR integration. We further propose Enigmata-Eval, a rigorous benchmark, and develop optimized multi-task RLVR strategies. Our trained model, Qwen2.5-32B-Enigmata, consistently surpasses o3-mini-high and o1 on the puzzle reasoning benchmarks like Enigmata-Eval, ARC-AGI (32.8%), and ARC-AGI 2 (0.6%). It also generalizes well to out-of-domain puzzle benchmarks and mathematical reasoning, with little multi-tasking trade-off. When trained on larger models like Seed1.5-Thinking (20B activated parameters and 200B total parameters), puzzle data from Enigmata further boosts SoTA performance on advanced math and STEM reasoning tasks such as AIME (2024-2025), BeyondAIME and GPQA (Diamond), showing nice generalization benefits of Enigmata. This work offers a unified, controllable framework for advancing logical reasoning in LLMs. Resources of this work can be found at https://seed-enigmata.github.io.
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025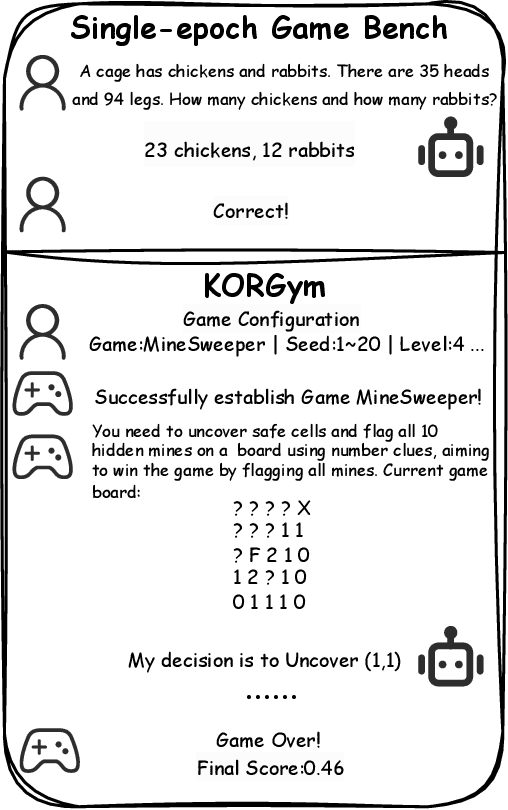
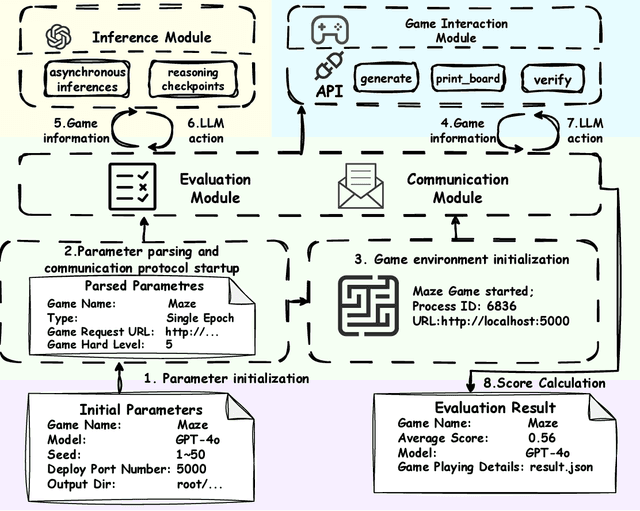

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
The Lighthouse of Language: Enhancing LLM Agents via Critique-Guided Improvement
Mar 20, 2025Large language models (LLMs) have recently transformed from text-based assistants to autonomous agents capable of planning, reasoning, and iteratively improving their actions. While numerical reward signals and verifiers can effectively rank candidate actions, they often provide limited contextual guidance. In contrast, natural language feedback better aligns with the generative capabilities of LLMs, providing richer and more actionable suggestions. However, parsing and implementing this feedback effectively can be challenging for LLM-based agents. In this work, we introduce Critique-Guided Improvement (CGI), a novel two-player framework, comprising an actor model that explores an environment and a critic model that generates detailed nature language feedback. By training the critic to produce fine-grained assessments and actionable revisions, and the actor to utilize these critiques, our approach promotes more robust exploration of alternative strategies while avoiding local optima. Experiments in three interactive environments show that CGI outperforms existing baselines by a substantial margin. Notably, even a small critic model surpasses GPT-4 in feedback quality. The resulting actor achieves state-of-the-art performance, demonstrating the power of explicit iterative guidance to enhance decision-making in LLM-based agents.
Implicit Reasoning in Transformers is Reasoning through Shortcuts
Mar 10, 2025Test-time compute is emerging as a new paradigm for enhancing language models' complex multi-step reasoning capabilities, as demonstrated by the success of OpenAI's o1 and o3, as well as DeepSeek's R1. Compared to explicit reasoning in test-time compute, implicit reasoning is more inference-efficient, requiring fewer generated tokens. However, why does the advanced reasoning capability fail to emerge in the implicit reasoning style? In this work, we train GPT-2 from scratch on a curated multi-step mathematical reasoning dataset and conduct analytical experiments to investigate how language models perform implicit reasoning in multi-step tasks. Our findings reveal: 1) Language models can perform step-by-step reasoning and achieve high accuracy in both in-domain and out-of-domain tests via implicit reasoning. However, this capability only emerges when trained on fixed-pattern data. 2) Conversely, implicit reasoning abilities emerging from training on unfixed-pattern data tend to overfit a specific pattern and fail to generalize further. Notably, this limitation is also observed in state-of-the-art large language models. These findings suggest that language models acquire implicit reasoning through shortcut learning, enabling strong performance on tasks with similar patterns while lacking generalization.
Hybrid CNN-Dilated Self-attention Model Using Inertial and Body-Area Electrostatic Sensing for Gym Workout Recognition, Counting, and User Authentification
Mar 08, 2025While human body capacitance ($HBC$) has been explored as a novel wearable motion sensing modality, its competence has never been quantitatively demonstrated compared to that of the dominant inertial measurement unit ($IMU$) in practical scenarios. This work is thus motivated to evaluate the contribution of $HBC$ in wearable motion sensing. A real-life case study, gym workout tracking, is described to assess the effectiveness of $HBC$ as a complement to $IMU$ in activity recognition. Fifty gym sessions from ten volunteers were collected, bringing a fifty-hour annotated $IMU$ and $HBC$ dataset. With a hybrid CNN-Dilated neural network model empowered with the self-attention mechanism, $HBC$ slightly improves accuracy to the $IMU$ for workout recognition and has substantial advantages over $IMU$ for repetition counting. This work helps to enhance the understanding of $HBC$, a novel wearable motion-sensing modality based on the body-area electrostatic field. All materials presented in this work are open-sourced to promote further study \footnote{https://github.com/zhaxidele/Toolkit-for-HBC-sensing}.
CoSER: Coordinating LLM-Based Persona Simulation of Established Roles
Feb 13, 2025Role-playing language agents (RPLAs) have emerged as promising applications of large language models (LLMs). However, simulating established characters presents a challenging task for RPLAs, due to the lack of authentic character datasets and nuanced evaluation methods using such data. In this paper, we present CoSER, a collection of a high-quality dataset, open models, and an evaluation protocol towards effective RPLAs of established characters. The CoSER dataset covers 17,966 characters from 771 renowned books. It provides authentic dialogues with real-world intricacies, as well as diverse data types such as conversation setups, character experiences and internal thoughts. Drawing from acting methodology, we introduce given-circumstance acting for training and evaluating role-playing LLMs, where LLMs sequentially portray multiple characters in book scenes. Using our dataset, we develop CoSER 8B and CoSER 70B, i.e., advanced open role-playing LLMs built on LLaMA-3.1 models. Extensive experiments demonstrate the value of the CoSER dataset for RPLA training, evaluation and retrieval. Moreover, CoSER 70B exhibits state-of-the-art performance surpassing or matching GPT-4o on our evaluation and three existing benchmarks, i.e., achieving 75.80% and 93.47% accuracy on the InCharacter and LifeChoice benchmarks respectively.
Agent-R: Training Language Model Agents to Reflect via Iterative Self-Training
Jan 20, 2025Large Language Models (LLMs) agents are increasingly pivotal for addressing complex tasks in interactive environments. Existing work mainly focuses on enhancing performance through behavior cloning from stronger experts, yet such approaches often falter in real-world applications, mainly due to the inability to recover from errors. However, step-level critique data is difficult and expensive to collect. Automating and dynamically constructing self-critique datasets is thus crucial to empowering models with intelligent agent capabilities. In this work, we propose an iterative self-training framework, Agent-R, that enables language Agent to Reflect on the fly. Unlike traditional methods that reward or penalize actions based on correctness, Agent-R leverages MCTS to construct training data that recover correct trajectories from erroneous ones. A key challenge of agent reflection lies in the necessity for timely revision rather than waiting until the end of a rollout. To address this, we introduce a model-guided critique construction mechanism: the actor model identifies the first error step (within its current capability) in a failed trajectory. Starting from it, we splice it with the adjacent correct path, which shares the same parent node in the tree. This strategy enables the model to learn reflection based on its current policy, therefore yielding better learning efficiency. To further explore the scalability of this self-improvement paradigm, we investigate iterative refinement of both error correction capabilities and dataset construction. Our findings demonstrate that Agent-R continuously improves the model's ability to recover from errors and enables timely error correction. Experiments on three interactive environments show that Agent-R effectively equips agents to correct erroneous actions while avoiding loops, achieving superior performance compared to baseline methods (+5.59%).
ToolHop: A Query-Driven Benchmark for Evaluating Large Language Models in Multi-Hop Tool Use
Jan 07, 2025Effective evaluation of multi-hop tool use is critical for analyzing the understanding, reasoning, and function-calling capabilities of large language models (LLMs). However, progress has been hindered by a lack of reliable evaluation datasets. To address this, we present ToolHop, a dataset comprising 995 user queries and 3,912 associated tools, specifically designed for rigorous evaluation of multi-hop tool use. ToolHop ensures diverse queries, meaningful interdependencies, locally executable tools, detailed feedback, and verifiable answers through a novel query-driven data construction approach that includes tool creation, document refinement, and code generation. We evaluate 14 LLMs across five model families (i.e., LLaMA3.1, Qwen2.5, Gemini1.5, Claude3.5, and GPT), uncovering significant challenges in handling multi-hop tool-use scenarios. The leading model, GPT-4o, achieves an accuracy of 49.04%, underscoring substantial room for improvement. Further analysis reveals variations in tool-use strategies for various families, offering actionable insights to guide the development of more effective approaches. Code and data can be found in https://huggingface.co/datasets/bytedance-research/ToolHop.