 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models Defining A New Era In Sensor-based Human Activity Recognition: A Survey And Outlook
Apr 03, 2026Sensor-based Human Activity Recognition (HAR) underpins many ubiquitous and wearable computing applications, yet current models remain limited by scarce labels, sensor heterogeneity, and weak generalization across users, devices, and contexts. Foundation models, which are generally pretrained at scale using self-supervised and multimodal learning, offer a unifying paradigm to address these challenges by learning reusable, adaptable representations for activity understanding. This survey synthesizes emerging foundation models for sensor-based HAR. We first clarify foundational concepts, definitions, and evaluation criteria, then organize existing work using a lifecycle-oriented taxonomy spanning input design, pretraining, adaptation, and utilization. Rather than enumerating individual models, we analyze recurring design patterns and trade-offs across nine technical axes, including modality scope, tokenization, architectures, learning paradigms, adaptation mechanisms, and deployment settings. From this synthesis, we identify three dominant development trajectories: (1) HAR-specific foundation models trained from scratch on large sensor corpora, (2) adaptation of general time-series or multimodal foundation models to sensor-based HAR, and (3) integration of large language models for reasoning, annotation, and human-AI interaction. We conclude by highlighting open challenges in data curation, multimodal alignment, personalization, privacy, and responsible deployment, and outline directions toward general-purpose, interpretable, and human-centered foundation models for activity understanding. A complete, continuously updated index of papers and models is available in our companion repository: https://github.com/zhaxidele/Foundation-Models-Defining-A-New-Era-In-Human-Activity-Recognition.
Embedded Inter-Subject Variability in Adversarial Learning for Inertial Sensor-Based Human Activity Recognition
Mar 05, 2026This paper addresses the problem of Human Activity Recognition (HAR) using data from wearable inertial sensors. An important challenge in HAR is the model's generalization capabilities to new unseen individuals due to inter-subject variability, i.e., the same activity is performed differently by different individuals. To address this problem, we propose a novel deep adversarial framework that integrates the concept of inter-subject variability in the adversarial task, thereby encouraging subject-invariant feature representations and enhancing the classification performance in the HAR problem. Our approach outperforms previous methods in three well-established HAR datasets using a leave-one-subject-out (LOSO) cross-validation. Further results indicate that our proposed adversarial task effectively reduces inter-subject variability among different users in the feature space, and it outperforms adversarial tasks from previous works when integrated into our framework. Code: https://github.com/FranciscoCalatrava/EmbeddedSubjectVariability.git
TinierHAR: Towards Ultra-Lightweight Deep Learning Models for Efficient Human Activity Recognition on Edge Devices
Jul 10, 2025Human Activity Recognition (HAR) on resource-constrained wearable devices demands inference models that harmonize accuracy with computational efficiency. This paper introduces TinierHAR, an ultra-lightweight deep learning architecture that synergizes residual depthwise separable convolutions, gated recurrent units (GRUs), and temporal aggregation to achieve SOTA efficiency without compromising performance. Evaluated across 14 public HAR datasets, TinierHAR reduces Parameters by 2.7x (vs. TinyHAR) and 43.3x (vs. DeepConvLSTM), and MACs by 6.4x and 58.6x, respectively, while maintaining the averaged F1-scores. Beyond quantitative gains, this work provides the first systematic ablation study dissecting the contributions of spatial-temporal components across proposed TinierHAR, prior SOTA TinyHAR, and the classical DeepConvLSTM, offering actionable insights for designing efficient HAR systems. We finally discussed the findings and suggested principled design guidelines for future efficient HAR. To catalyze edge-HAR research, we open-source all materials in this work for future benchmarking\footnote{https://github.com/zhaxidele/TinierHAR}
TxP: Reciprocal Generation of Ground Pressure Dynamics and Activity Descriptions for Improving Human Activity Recognition
May 04, 2025
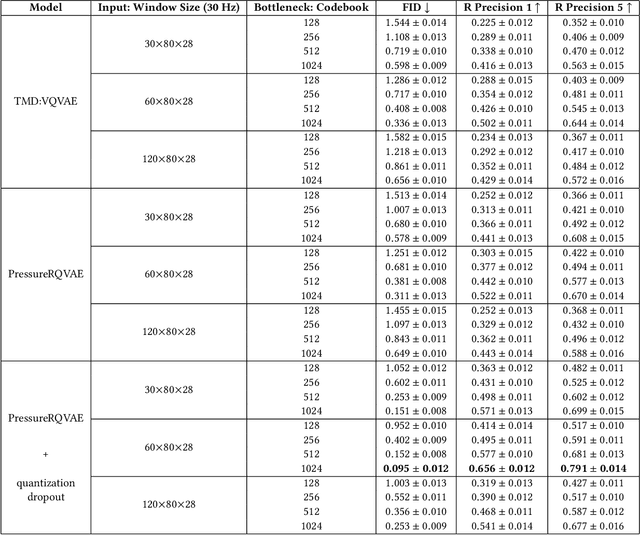


Sensor-based human activity recognition (HAR) has predominantly focused on Inertial Measurement Units and vision data, often overlooking the capabilities unique to pressure sensors, which capture subtle body dynamics and shifts in the center of mass. Despite their potential for postural and balance-based activities, pressure sensors remain underutilized in the HAR domain due to limited datasets. To bridge this gap, we propose to exploit generative foundation models with pressure-specific HAR techniques. Specifically, we present a bidirectional Text$\times$Pressure model that uses generative foundation models to interpret pressure data as natural language. TxP accomplishes two tasks: (1) Text2Pressure, converting activity text descriptions into pressure sequences, and (2) Pressure2Text, generating activity descriptions and classifications from dynamic pressure maps. Leveraging pre-trained models like CLIP and LLaMA 2 13B Chat, TxP is trained on our synthetic PressLang dataset, containing over 81,100 text-pressure pairs. Validated on real-world data for activities such as yoga and daily tasks, TxP provides novel approaches to data augmentation and classification grounded in atomic actions. This consequently improved HAR performance by up to 12.4\% in macro F1 score compared to the state-of-the-art, advancing pressure-based HAR with broader applications and deeper insights into human movement.
Hybrid CNN-Dilated Self-attention Model Using Inertial and Body-Area Electrostatic Sensing for Gym Workout Recognition, Counting, and User Authentification
Mar 08, 2025While human body capacitance ($HBC$) has been explored as a novel wearable motion sensing modality, its competence has never been quantitatively demonstrated compared to that of the dominant inertial measurement unit ($IMU$) in practical scenarios. This work is thus motivated to evaluate the contribution of $HBC$ in wearable motion sensing. A real-life case study, gym workout tracking, is described to assess the effectiveness of $HBC$ as a complement to $IMU$ in activity recognition. Fifty gym sessions from ten volunteers were collected, bringing a fifty-hour annotated $IMU$ and $HBC$ dataset. With a hybrid CNN-Dilated neural network model empowered with the self-attention mechanism, $HBC$ slightly improves accuracy to the $IMU$ for workout recognition and has substantial advantages over $IMU$ for repetition counting. This work helps to enhance the understanding of $HBC$, a novel wearable motion-sensing modality based on the body-area electrostatic field. All materials presented in this work are open-sourced to promote further study \footnote{https://github.com/zhaxidele/Toolkit-for-HBC-sensing}.
Beyond Confusion: A Fine-grained Dialectical Examination of Human Activity Recognition Benchmark Datasets
Dec 12, 2024



The research of machine learning (ML) algorithms for human activity recognition (HAR) has made significant progress with publicly available datasets. However, most research prioritizes statistical metrics over examining negative sample details. While recent models like transformers have been applied to HAR datasets with limited success from the benchmark metrics, their counterparts have effectively solved problems on similar levels with near 100% accuracy. This raises questions about the limitations of current approaches. This paper aims to address these open questions by conducting a fine-grained inspection of six popular HAR benchmark datasets. We identified for some parts of the data, none of the six chosen state-of-the-art ML methods can correctly classify, denoted as the intersect of false classifications (IFC). Analysis of the IFC reveals several underlying problems, including ambiguous annotations, irregularities during recording execution, and misaligned transition periods. We contribute to the field by quantifying and characterizing annotated data ambiguities, providing a trinary categorization mask for dataset patching, and stressing potential improvements for future data collections.
GenAI Assisting Medical Training
Oct 21, 2024

Medical procedures such as venipuncture and cannulation are essential for nurses and require precise skills. Learning this skill, in turn, is a challenge for educators due to the number of teachers per class and the complexity of the task. The study aims to help students with skill acquisition and alleviate the educator's workload by integrating generative AI methods to provide real-time feedback on medical procedures such as venipuncture and cannulation.
MuJo: Multimodal Joint Feature Space Learning for Human Activity Recognition
Jun 06, 2024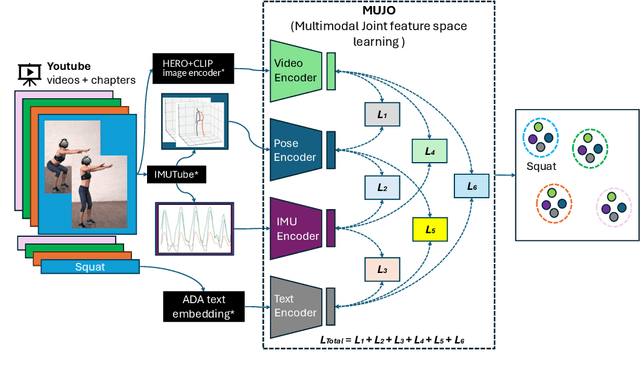
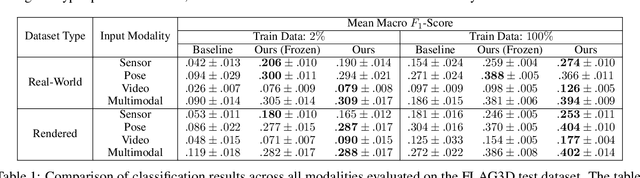
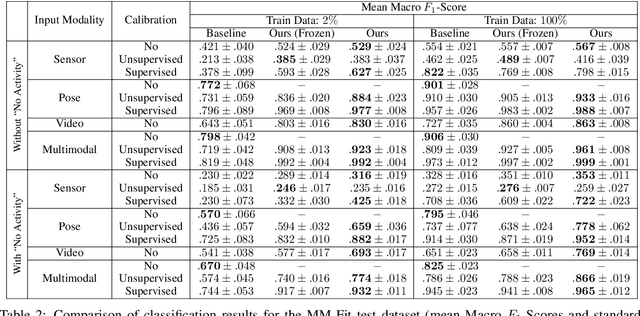
Human Activity Recognition is a longstanding problem in AI with applications in a broad range of areas: from healthcare, sports and fitness, security, and human computer interaction to robotics. The performance of HAR in real-world settings is strongly dependent on the type and quality of the input signal that can be acquired. Given an unobstructed, high-quality camera view of a scene, computer vision systems, in particular in conjunction with foundational models (e.g., CLIP), can today fairly reliably distinguish complex activities. On the other hand, recognition using modalities such as wearable sensors (which are often more broadly available, e.g, in mobile phones and smartwatches) is a more difficult problem, as the signals often contain less information and labeled training data is more difficult to acquire. In this work, we show how we can improve HAR performance across different modalities using multimodal contrastive pretraining. Our approach MuJo (Multimodal Joint Feature Space Learning), learns a multimodal joint feature space with video, language, pose, and IMU sensor data. The proposed approach combines contrastive and multitask learning methods and analyzes different multitasking strategies for learning a compact shared representation. A large dataset with parallel video, language, pose, and sensor data points is also introduced to support the research, along with an analysis of the robustness of the multimodal joint space for modal-incomplete and low-resource data. On the MM-Fit dataset, our model achieves an impressive Macro F1-Score of up to 0.992 with only 2% of the train data and 0.999 when using all available training data for classification tasks. Moreover, in the scenario where the MM-Fit dataset is unseen, we demonstrate a generalization performance of up to 0.638.
Enhancing Inertial Hand based HAR through Joint Representation of Language, Pose and Synthetic IMUs
Jun 03, 2024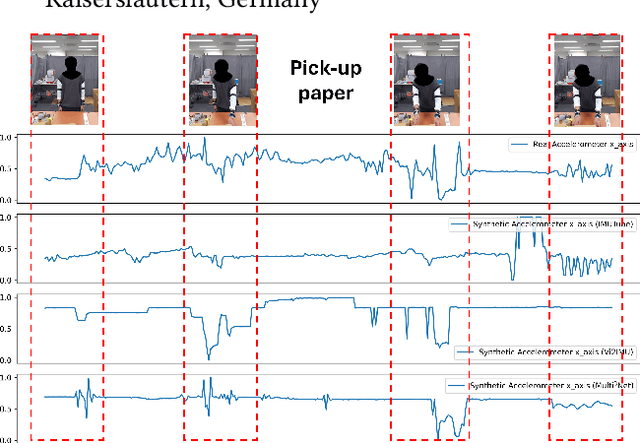
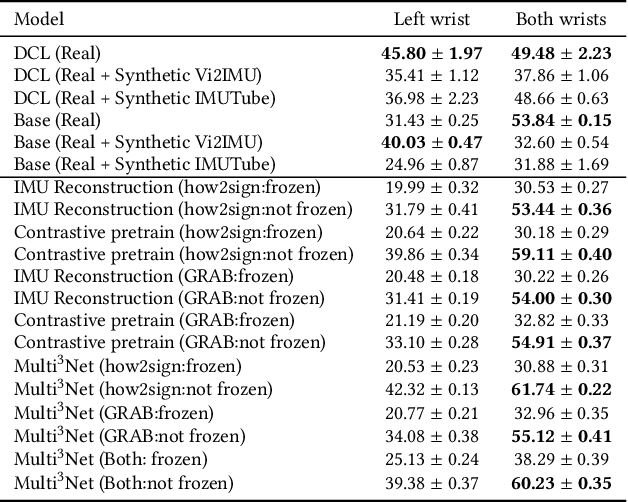
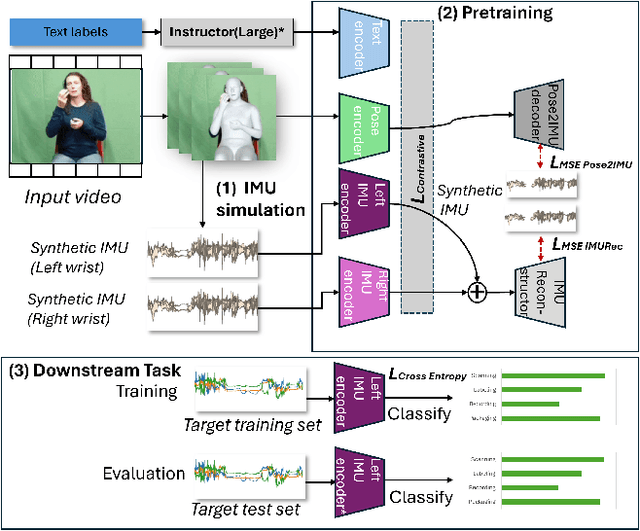
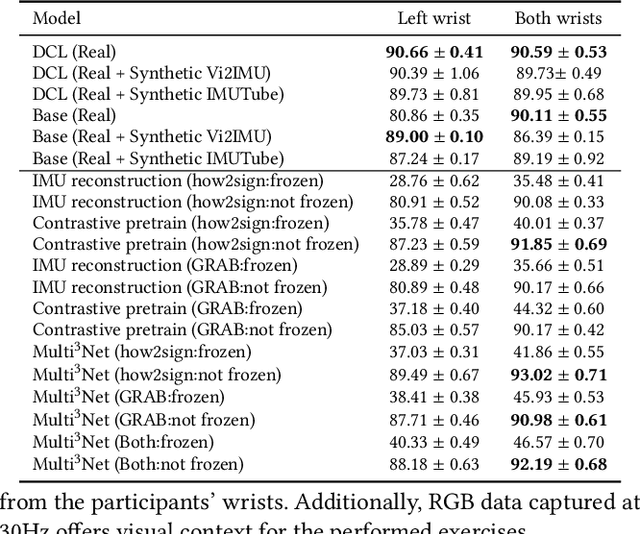
Due to the scarcity of labeled sensor data in HAR, prior research has turned to video data to synthesize Inertial Measurement Units (IMU) data, capitalizing on its rich activity annotations. However, generating IMU data from videos presents challenges for HAR in real-world settings, attributed to the poor quality of synthetic IMU data and its limited efficacy in subtle, fine-grained motions. In this paper, we propose Multi$^3$Net, our novel multi-modal, multitask, and contrastive-based framework approach to address the issue of limited data. Our pretraining procedure uses videos from online repositories, aiming to learn joint representations of text, pose, and IMU simultaneously. By employing video data and contrastive learning, our method seeks to enhance wearable HAR performance, especially in recognizing subtle activities.Our experimental findings validate the effectiveness of our approach in improving HAR performance with IMU data. We demonstrate that models trained with synthetic IMU data generated from videos using our method surpass existing approaches in recognizing fine-grained activities.
Text me the data: Generating Ground Pressure Sequence from Textual Descriptions for HAR
Feb 22, 2024



In human activity recognition (HAR), the availability of substantial ground truth is necessary for training efficient models. However, acquiring ground pressure data through physical sensors itself can be cost-prohibitive, time-consuming. To address this critical need, we introduce Text-to-Pressure (T2P), a framework designed to generate extensive ground pressure sequences from textual descriptions of human activities using deep learning techniques. We show that the combination of vector quantization of sensor data along with simple text conditioned auto regressive strategy allows us to obtain high-quality generated pressure sequences from textual descriptions with the help of discrete latent correlation between text and pressure maps. We achieved comparable performance on the consistency between text and generated motion with an R squared value of 0.722, Masked R squared value of 0.892, and FID score of 1.83. Additionally, we trained a HAR model with the the synthesized data and evaluated it on pressure dynamics collected by a real pressure sensor which is on par with a model trained on only real data. Combining both real and synthesized training data increases the overall macro F1 score by 5.9 percent.