 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum-inspired Embeddings Projection and Similarity Metrics for Representation Learning
Jan 08, 2025



Over the last decade, representation learning, which embeds complex information extracted from large amounts of data into dense vector spaces, has emerged as a key technique in machine learning. Among other applications, it has been a key building block for large language models and advanced computer vision systems based on contrastive learning. A core component of representation learning systems is the projection head, which maps the original embeddings into different, often compressed spaces, while preserving the similarity relationship between vectors. In this paper, we propose a quantum-inspired projection head that includes a corresponding quantum-inspired similarity metric. Specifically, we map classical embeddings onto quantum states in Hilbert space and introduce a quantum circuit-based projection head to reduce embedding dimensionality. To evaluate the effectiveness of this approach, we extended the BERT language model by integrating our projection head for embedding compression. We compared the performance of embeddings, which were compressed using our quantum-inspired projection head, with those compressed using a classical projection head on information retrieval tasks using the TREC 2019 and TREC 2020 Deep Learning benchmarks. The results demonstrate that our quantum-inspired method achieves competitive performance relative to the classical method while utilizing 32 times fewer parameters. Furthermore, when trained from scratch, it notably excels, particularly on smaller datasets. This work not only highlights the effectiveness of the quantum-inspired approach but also emphasizes the utility of efficient, ad hoc low-entanglement circuit simulations within neural networks as a powerful quantum-inspired technique.
Benefiting from Quantum? A Comparative Study of Q-Seg, Quantum-Inspired Techniques, and U-Net for Crack Segmentation
Oct 14, 2024Exploring the potential of quantum hardware for enhancing classical and real-world applications is an ongoing challenge. This study evaluates the performance of quantum and quantum-inspired methods compared to classical models for crack segmentation. Using annotated gray-scale image patches of concrete samples, we benchmark a classical mean Gaussian mixture technique, a quantum-inspired fermion-based method, Q-Seg a quantum annealing-based method, and a U-Net deep learning architecture. Our results indicate that quantum-inspired and quantum methods offer a promising alternative for image segmentation, particularly for complex crack patterns, and could be applied in near-future applications.
MuJo: Multimodal Joint Feature Space Learning for Human Activity Recognition
Jun 06, 2024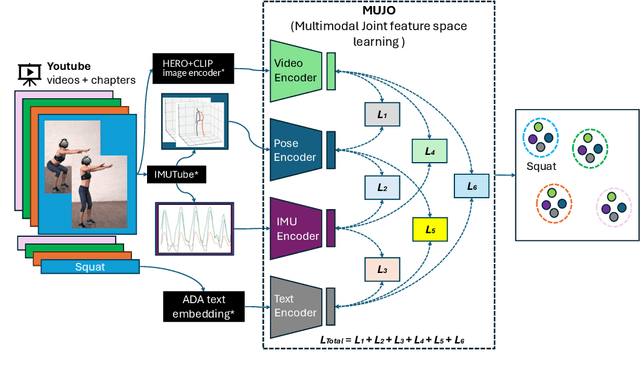
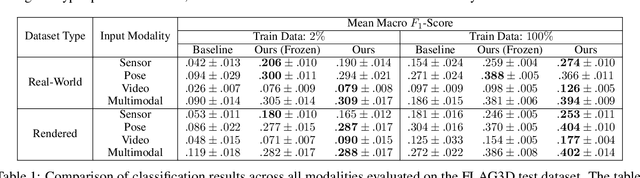
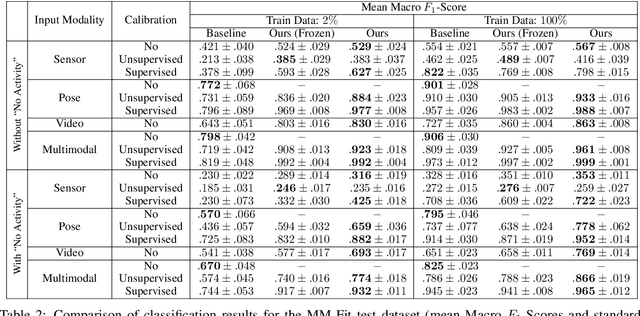
Human Activity Recognition is a longstanding problem in AI with applications in a broad range of areas: from healthcare, sports and fitness, security, and human computer interaction to robotics. The performance of HAR in real-world settings is strongly dependent on the type and quality of the input signal that can be acquired. Given an unobstructed, high-quality camera view of a scene, computer vision systems, in particular in conjunction with foundational models (e.g., CLIP), can today fairly reliably distinguish complex activities. On the other hand, recognition using modalities such as wearable sensors (which are often more broadly available, e.g, in mobile phones and smartwatches) is a more difficult problem, as the signals often contain less information and labeled training data is more difficult to acquire. In this work, we show how we can improve HAR performance across different modalities using multimodal contrastive pretraining. Our approach MuJo (Multimodal Joint Feature Space Learning), learns a multimodal joint feature space with video, language, pose, and IMU sensor data. The proposed approach combines contrastive and multitask learning methods and analyzes different multitasking strategies for learning a compact shared representation. A large dataset with parallel video, language, pose, and sensor data points is also introduced to support the research, along with an analysis of the robustness of the multimodal joint space for modal-incomplete and low-resource data. On the MM-Fit dataset, our model achieves an impressive Macro F1-Score of up to 0.992 with only 2% of the train data and 0.999 when using all available training data for classification tasks. Moreover, in the scenario where the MM-Fit dataset is unseen, we demonstrate a generalization performance of up to 0.638.
Unreflected Acceptance -- Investigating the Negative Consequences of ChatGPT-Assisted Problem Solving in Physics Education
Aug 21, 2023Large language models (LLMs) have recently gained popularity. However, the impact of their general availability through ChatGPT on sensitive areas of everyday life, such as education, remains unclear. Nevertheless, the societal impact on established educational methods is already being experienced by both students and educators. Our work focuses on higher physics education and examines problem solving strategies. In a study, students with a background in physics were assigned to solve physics exercises, with one group having access to an internet search engine (N=12) and the other group being allowed to use ChatGPT (N=27). We evaluated their performance, strategies, and interaction with the provided tools. Our results showed that nearly half of the solutions provided with the support of ChatGPT were mistakenly assumed to be correct by the students, indicating that they overly trusted ChatGPT even in their field of expertise. Likewise, in 42% of cases, students used copy & paste to query ChatGPT -- an approach only used in 4% of search engine queries -- highlighting the stark differences in interaction behavior between the groups and indicating limited reflection when using ChatGPT. In our work, we demonstrated a need to (1) guide students on how to interact with LLMs and (2) create awareness of potential shortcomings for users.