 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuJo: Multimodal Joint Feature Space Learning for Human Activity Recognition
Jun 06, 2024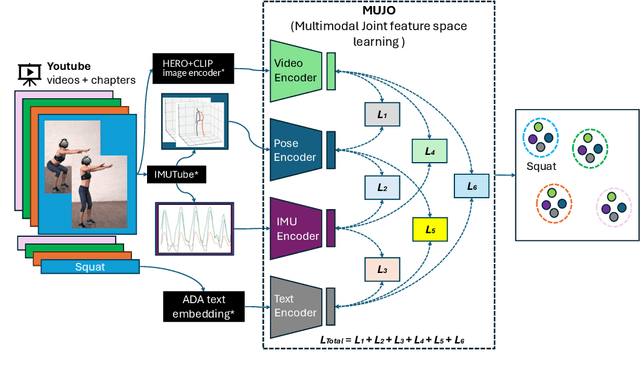
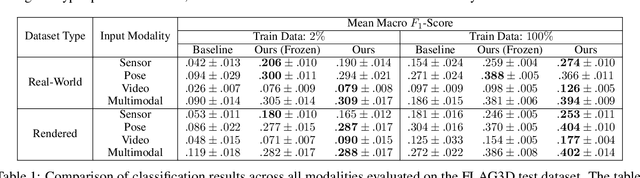
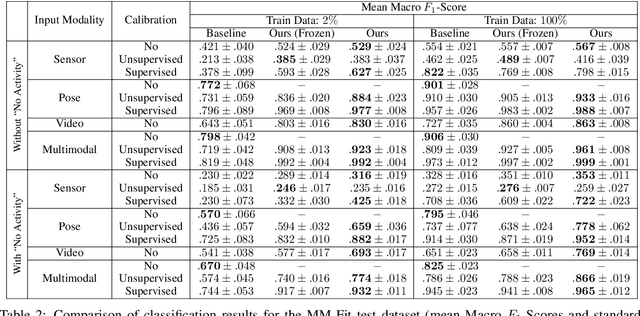
Human Activity Recognition is a longstanding problem in AI with applications in a broad range of areas: from healthcare, sports and fitness, security, and human computer interaction to robotics. The performance of HAR in real-world settings is strongly dependent on the type and quality of the input signal that can be acquired. Given an unobstructed, high-quality camera view of a scene, computer vision systems, in particular in conjunction with foundational models (e.g., CLIP), can today fairly reliably distinguish complex activities. On the other hand, recognition using modalities such as wearable sensors (which are often more broadly available, e.g, in mobile phones and smartwatches) is a more difficult problem, as the signals often contain less information and labeled training data is more difficult to acquire. In this work, we show how we can improve HAR performance across different modalities using multimodal contrastive pretraining. Our approach MuJo (Multimodal Joint Feature Space Learning), learns a multimodal joint feature space with video, language, pose, and IMU sensor data. The proposed approach combines contrastive and multitask learning methods and analyzes different multitasking strategies for learning a compact shared representation. A large dataset with parallel video, language, pose, and sensor data points is also introduced to support the research, along with an analysis of the robustness of the multimodal joint space for modal-incomplete and low-resource data. On the MM-Fit dataset, our model achieves an impressive Macro F1-Score of up to 0.992 with only 2% of the train data and 0.999 when using all available training data for classification tasks. Moreover, in the scenario where the MM-Fit dataset is unseen, we demonstrate a generalization performance of up to 0.638.
InterroLang: Exploring NLP Models and Datasets through Dialogue-based Explanations
Oct 23, 2023While recently developed NLP explainability methods let us open the black box in various ways (Madsen et al., 2022), a missing ingredient in this endeavor is an interactive tool offering a conversational interface. Such a dialogue system can help users explore datasets and models with explanations in a contextualized manner, e.g. via clarification or follow-up questions, and through a natural language interface. We adapt the conversational explanation framework TalkToModel (Slack et al., 2022) to the NLP domain, add new NLP-specific operations such as free-text rationalization, and illustrate its generalizability on three NLP tasks (dialogue act classification, question answering, hate speech detection). To recognize user queries for explanations, we evaluate fine-tuned and few-shot prompting models and implement a novel Adapter-based approach. We then conduct two user studies on (1) the perceived correctness and helpfulness of the dialogues, and (2) the simulatability, i.e. how objectively helpful dialogical explanations are for humans in figuring out the model's predicted label when it's not shown. We found rationalization and feature attribution were helpful in explaining the model behavior. Moreover, users could more reliably predict the model outcome based on an explanation dialogue rather than one-off explanations.
Synthesis of Compositional Animations from Textual Descriptions
Mar 31, 2021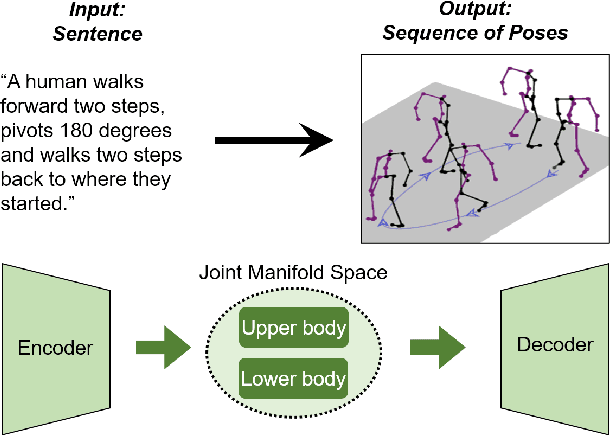
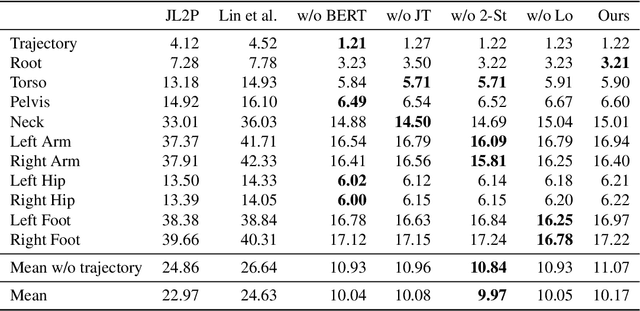
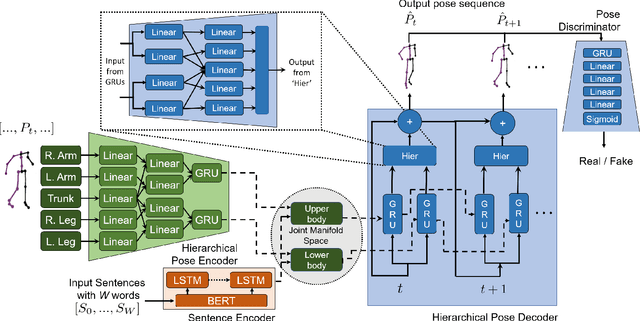
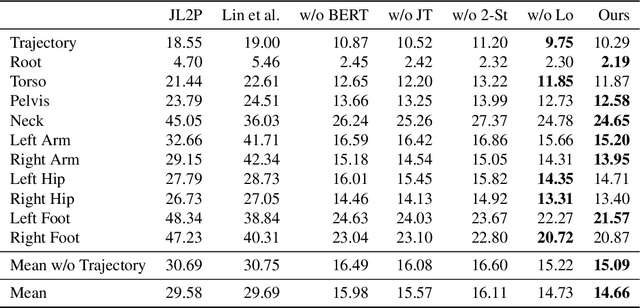
"How can we animate 3D-characters from a movie script or move robots by simply telling them what we would like them to do?" "How unstructured and complex can we make a sentence and still generate plausible movements from it?" These are questions that need to be answered in the long-run, as the field is still in its infancy. Inspired by these problems, we present a new technique for generating compositional actions, which handles complex input sentences. Our output is a 3D pose sequence depicting the actions in the input sentence. We propose a hierarchical two-stream sequential model to explore a finer joint-level mapping between natural language sentences and 3D pose sequences corresponding to the given motion. We learn two manifold representations of the motion -- one each for the upper body and the lower body movements. Our model can generate plausible pose sequences for short sentences describing single actions as well as long compositional sentences describing multiple sequential and superimposed actions. We evaluate our proposed model on the publicly available KIT Motion-Language Dataset containing 3D pose data with human-annotated sentences. Experimental results show that our model advances the state-of-the-art on text-based motion synthesis in objective evaluations by a margin of 50%. Qualitative evaluations based on a user study indicate that our synthesized motions are perceived to be the closest to the ground-truth motion captures for both short and compositional sentences.
Few-shot Learning for Slot Tagging with Attentive Relational Network
Mar 03, 2021



Metric-based learning is a well-known family of methods for few-shot learning, especially in computer vision. Recently, they have been used in many natural language processing applications but not for slot tagging. In this paper, we explore metric-based learning methods in the slot tagging task and propose a novel metric-based learning architecture - Attentive Relational Network. Our proposed method extends relation networks, making them more suitable for natural language processing applications in general, by leveraging pretrained contextual embeddings such as ELMO and BERT and by using attention mechanism. The results on SNIPS data show that our proposed method outperforms other state-of-the-art metric-based learning methods.
Second-order Co-occurrence Sensitivity of Skip-Gram with Negative Sampling
Jun 07, 2019
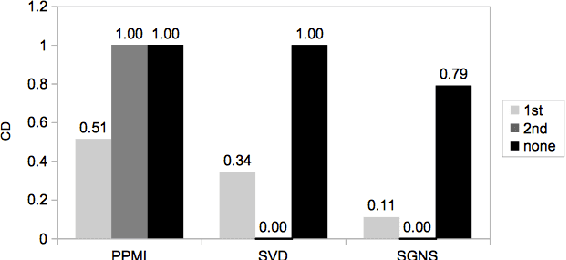

We simulate first- and second-order context overlap and show that Skip-Gram with Negative Sampling is similar to Singular Value Decomposition in capturing second-order co-occurrence information, while Pointwise Mutual Information is agnostic to it. We support the results with an empirical study finding that the models react differently when provided with additional second-order information. Our findings reveal a basic property of Skip-Gram with Negative Sampling and point towards an explanation of its success on a variety of tasks.