 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing BERT for German Compound Semantics
May 20, 2025This paper investigates the extent to which pretrained German BERT encodes knowledge of noun compound semantics. We comprehensively vary combinations of target tokens, layers, and cased vs. uncased models, and evaluate them by predicting the compositionality of 868 gold standard compounds. Looking at representational patterns within the transformer architecture, we observe trends comparable to equivalent prior work on English, with compositionality information most easily recoverable in the early layers. However, our strongest results clearly lag behind those reported for English, suggesting an inherently more difficult task in German. This may be due to the higher productivity of compounding in German than in English and the associated increase in constituent-level ambiguity, including in our target compound set.
Unveiling the Mystery of Visual Attributes of Concrete and Abstract Concepts: Variability, Nearest Neighbors, and Challenging Categories
Oct 15, 2024



The visual representation of a concept varies significantly depending on its meaning and the context where it occurs; this poses multiple challenges both for vision and multimodal models. Our study focuses on concreteness, a well-researched lexical-semantic variable, using it as a case study to examine the variability in visual representations. We rely on images associated with approximately 1,000 abstract and concrete concepts extracted from two different datasets: Bing and YFCC. Our goals are: (i) evaluate whether visual diversity in the depiction of concepts can reliably distinguish between concrete and abstract concepts; (ii) analyze the variability of visual features across multiple images of the same concept through a nearest neighbor analysis; and (iii) identify challenging factors contributing to this variability by categorizing and annotating images. Our findings indicate that for classifying images of abstract versus concrete concepts, a combination of basic visual features such as color and texture is more effective than features extracted by more complex models like Vision Transformer (ViT). However, ViTs show better performances in the nearest neighbor analysis, emphasizing the need for a careful selection of visual features when analyzing conceptual variables through modalities other than text.
A Dataset for Physical and Abstract Plausibility and Sources of Human Disagreement
Apr 05, 2024



We present a novel dataset for physical and abstract plausibility of events in English. Based on naturally occurring sentences extracted from Wikipedia, we infiltrate degrees of abstractness, and automatically generate perturbed pseudo-implausible events. We annotate a filtered and balanced subset for plausibility using crowd-sourcing, and perform extensive cleansing to ensure annotation quality. In-depth quantitative analyses indicate that annotators favor plausibility over implausibility and disagree more on implausible events. Furthermore, our plausibility dataset is the first to capture abstractness in events to the same extent as concreteness, and we find that event abstractness has an impact on plausibility ratings: more concrete event participants trigger a perception of implausibility.
Willkommens-Merkel, Chaos-Johnson, and Tore-Klose: Modeling the Evaluative Meaning of German Personal Name Compounds
Apr 05, 2024We present a comprehensive computational study of the under-investigated phenomenon of personal name compounds (PNCs) in German such as Willkommens-Merkel ('Welcome-Merkel'). Prevalent in news, social media, and political discourse, PNCs are hypothesized to exhibit an evaluative function that is reflected in a more positive or negative perception as compared to the respective personal full name (such as Angela Merkel). We model 321 PNCs and their corresponding full names at discourse level, and show that PNCs bear an evaluative nature that can be captured through a variety of computational methods. Specifically, we assess through valence information whether a PNC is more positively or negatively evaluative than the person's name, by applying and comparing two approaches using (i) valence norms and (ii) pretrained language models (PLMs). We further enrich our data with personal, domain-specific, and extra-linguistic information and perform a range of regression analyses revealing that factors including compound and modifier valence, domain, and political party membership influence how a PNC is evaluated.
Semantics of Multiword Expressions in Transformer-Based Models: A Survey
Jan 27, 2024Multiword expressions (MWEs) are composed of multiple words and exhibit variable degrees of compositionality. As such, their meanings are notoriously difficult to model, and it is unclear to what extent this issue affects transformer architectures. Addressing this gap, we provide the first in-depth survey of MWE processing with transformer models. We overall find that they capture MWE semantics inconsistently, as shown by reliance on surface patterns and memorized information. MWE meaning is also strongly localized, predominantly in early layers of the architecture. Representations benefit from specific linguistic properties, such as lower semantic idiosyncrasy and ambiguity of target expressions. Our findings overall question the ability of transformer models to robustly capture fine-grained semantics. Furthermore, we highlight the need for more directly comparable evaluation setups.
The DURel Annotation Tool: Human and Computational Measurement of Semantic Proximity, Sense Clusters and Semantic Change
Nov 21, 2023
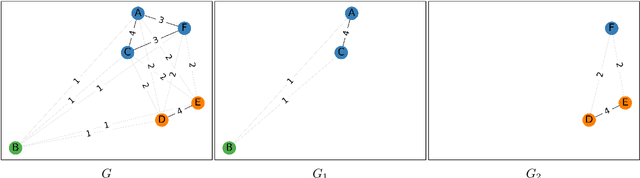


We present the DURel tool that implements the annotation of semantic proximity between uses of words into an online, open source interface. The tool supports standardized human annotation as well as computational annotation, building on recent advances with Word-in-Context models. Annotator judgments are clustered with automatic graph clustering techniques and visualized for analysis. This allows to measure word senses with simple and intuitive micro-task judgments between use pairs, requiring minimal preparation efforts. The tool offers additional functionalities to compare the agreement between annotators to guarantee the inter-subjectivity of the obtained judgments and to calculate summary statistics giving insights into sense frequency distributions, semantic variation or changes of senses over time.
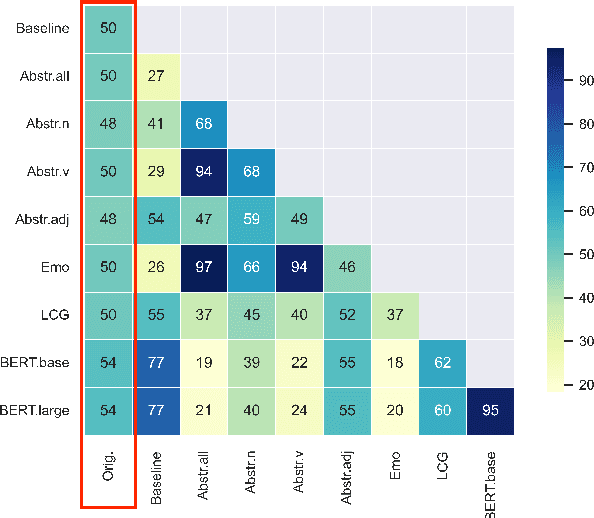
Investigating the Nature of Disagreements on Mid-Scale Ratings: A Case Study on the Abstractness-Concreteness Continuum
Nov 08, 2023


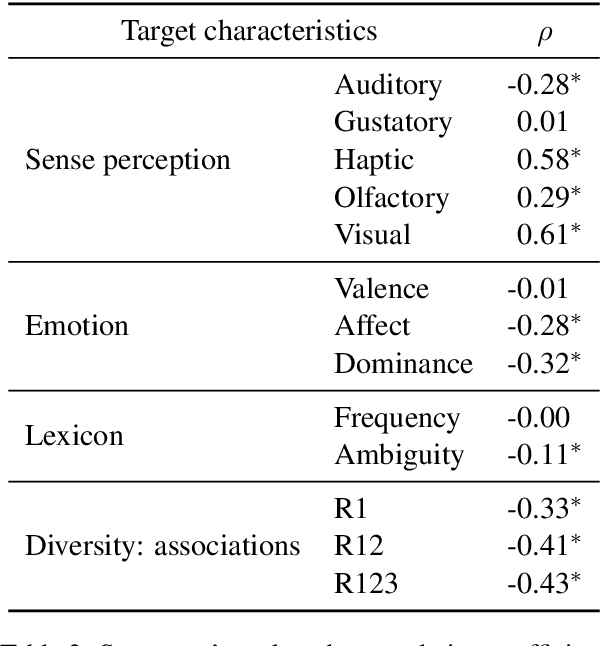
Humans tend to strongly agree on ratings on a scale for extreme cases (e.g., a CAT is judged as very concrete), but judgements on mid-scale words exhibit more disagreement. Yet, collected rating norms are heavily exploited across disciplines. Our study focuses on concreteness ratings and (i) implements correlations and supervised classification to identify salient multi-modal characteristics of mid-scale words, and (ii) applies a hard clustering to identify patterns of systematic disagreement across raters. Our results suggest to either fine-tune or filter mid-scale target words before utilising them.
Made of Steel? Learning Plausible Materials for Components in the Vehicle Repair Domain
Apr 28, 2023



We propose a novel approach to learn domain-specific plausible materials for components in the vehicle repair domain by probing Pretrained Language Models (PLMs) in a cloze task style setting to overcome the lack of annotated datasets. We devise a new method to aggregate salient predictions from a set of cloze query templates and show that domain-adaptation using either a small, high-quality or a customized Wikipedia corpus boosts performance. When exploring resource-lean alternatives, we find a distilled PLM clearly outperforming a classic pattern-based algorithm. Further, given that 98% of our domain-specific components are multiword expressions, we successfully exploit the compositionality assumption as a way to address data sparsity.
What Drives the Use of Metaphorical Language? Negative Insights from Abstractness, Affect, Discourse Coherence and Contextualized Word Representations
May 23, 2022

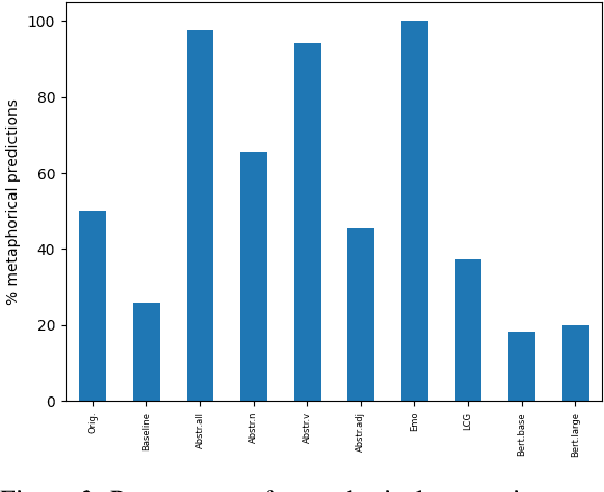
Given a specific discourse, which discourse properties trigger the use of metaphorical language, rather than using literal alternatives? For example, what drives people to say "grasp the meaning" rather than "understand the meaning" within a specific context? Many NLP approaches to metaphorical language rely on cognitive and (psycho-)linguistic insights and have successfully defined models of discourse coherence, abstractness and affect. In this work, we build five simple models relying on established cognitive and linguistic properties -- frequency, abstractness, affect, discourse coherence and contextualized word representations -- to predict the use of a metaphorical vs. synonymous literal expression in context. By comparing the models' outputs to human judgments, our study indicates that our selected properties are not sufficient to systematically explain metaphorical vs. literal language choices.
Features of Perceived Metaphoricity on the Discourse Level: Abstractness and Emotionality
May 18, 2022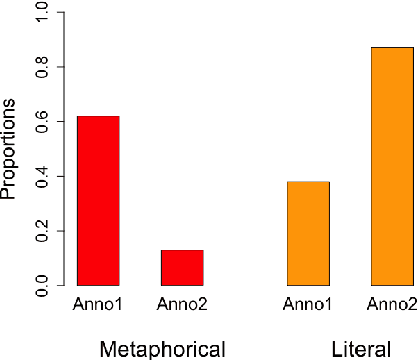


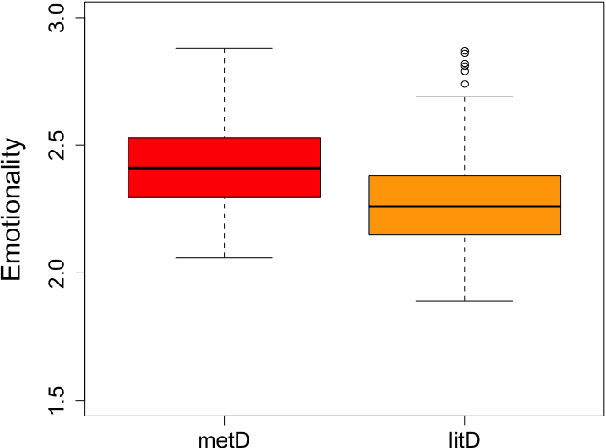
Research on metaphorical language has shown ties between abstractness and emotionality with regard to metaphoricity; prior work is however limited to the word and sentence levels, and up to date there is no empirical study establishing the extent to which this is also true on the discourse level. This paper explores which textual and perceptual features human annotators perceive as important for the metaphoricity of discourses and expressions, and addresses two research questions more specifically. First, is a metaphorically-perceived discourse more abstract and more emotional in comparison to a literally-perceived discourse? Second, is a metaphorical expression preceded by a more metaphorical/abstract/emotional context than a synonymous literal alternative? We used a dataset of 1,000 corpus-extracted discourses for which crowdsourced annotators (1) provided judgements on whether they perceived the discourses as more metaphorical or more literal, and (2) systematically listed lexical terms which triggered their decisions in (1). Our results indicate that metaphorical discourses are more emotional and to a certain extent more abstract than literal discourses. However, neither the metaphoricity nor the abstractness and emotionality of the preceding discourse seem to play a role in triggering the choice between synonymous metaphorical vs. literal expressions. Our dataset is available at https://www.ims.uni-stuttgart.de/data/discourse-met-lit.