 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexical Semantic Change Discovery
Jun 06, 2021
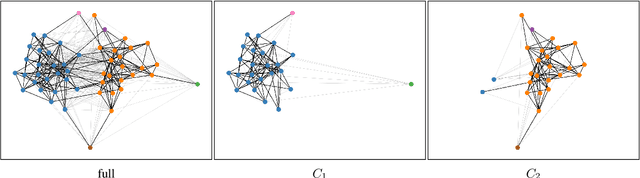

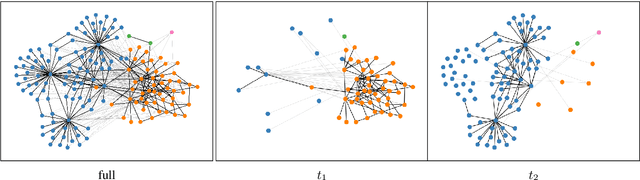
While there is a large amount of research in the field of Lexical Semantic Change Detection, only few approaches go beyond a standard benchmark evaluation of existing models. In this paper, we propose a shift of focus from change detection to change discovery, i.e., discovering novel word senses over time from the full corpus vocabulary. By heavily fine-tuning a type-based and a token-based approach on recently published German data, we demonstrate that both models can successfully be applied to discover new words undergoing meaning change. Furthermore, we provide an almost fully automated framework for both evaluation and discovery.
Explaining and Improving BERT Performance on Lexical Semantic Change Detection
Mar 12, 2021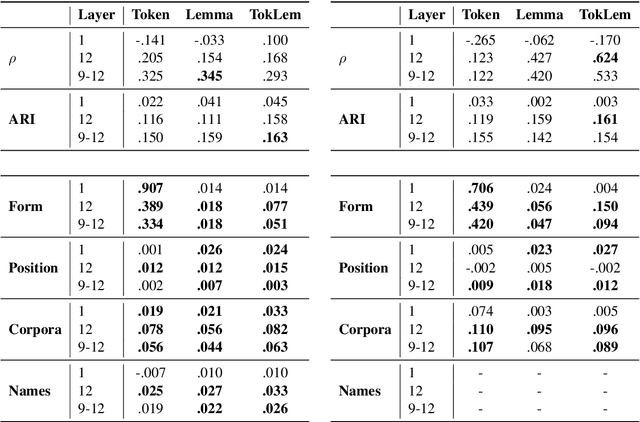
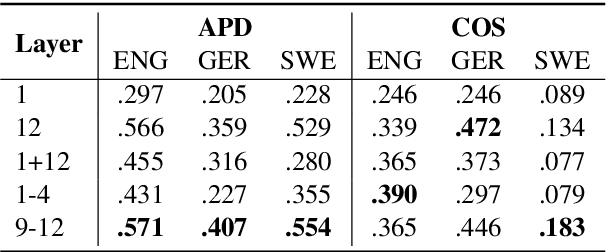
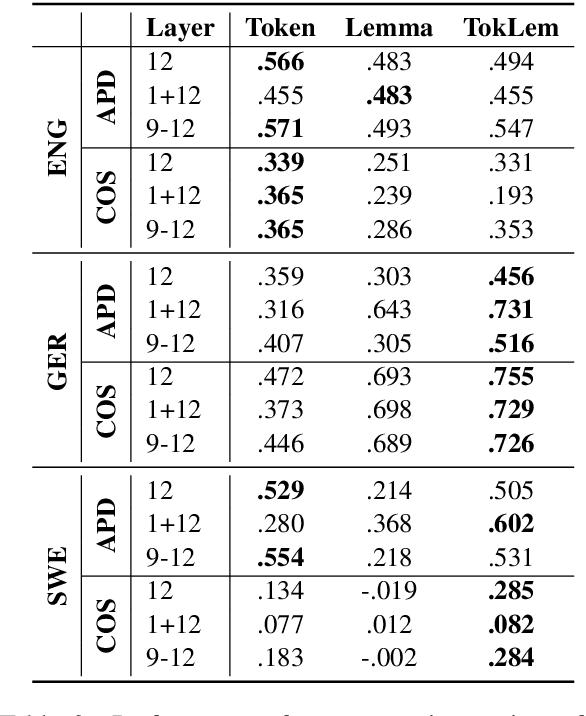
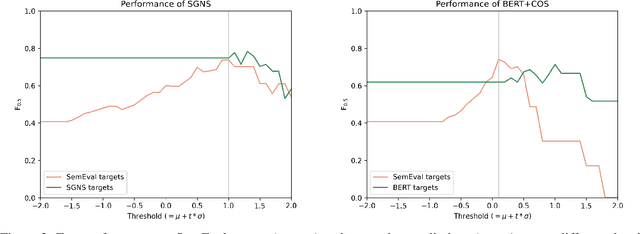
Type- and token-based embedding architectures are still competing in lexical semantic change detection. The recent success of type-based models in SemEval-2020 Task 1 has raised the question why the success of token-based models on a variety of other NLP tasks does not translate to our field. We investigate the influence of a range of variables on clusterings of BERT vectors and show that its low performance is largely due to orthographic information on the target word, which is encoded even in the higher layers of BERT representations. By reducing the influence of orthography we considerably improve BERT's performance.
Effects of Pre- and Post-Processing on type-based Embeddings in Lexical Semantic Change Detection
Jan 26, 2021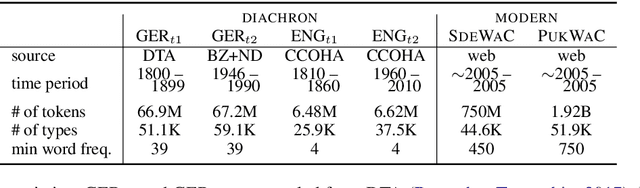
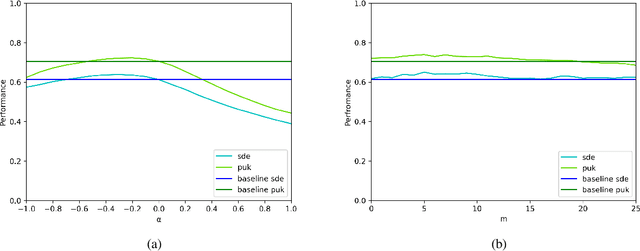

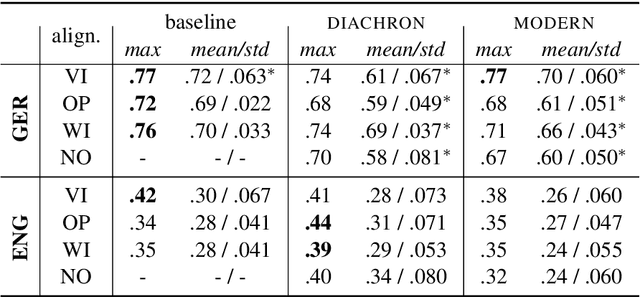
Lexical semantic change detection is a new and innovative research field. The optimal fine-tuning of models including pre- and post-processing is largely unclear. We optimize existing models by (i) pre-training on large corpora and refining on diachronic target corpora tackling the notorious small data problem, and (ii) applying post-processing transformations that have been shown to improve performance on synchronic tasks. Our results provide a guide for the application and optimization of lexical semantic change detection models across various learning scenarios.