 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Pre- and Post-Processing on type-based Embeddings in Lexical Semantic Change Detection
Jan 26, 2021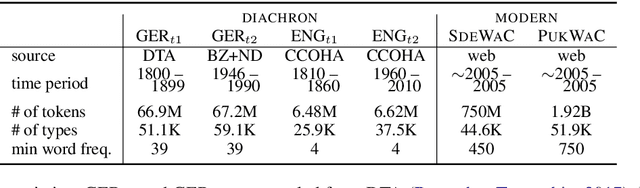
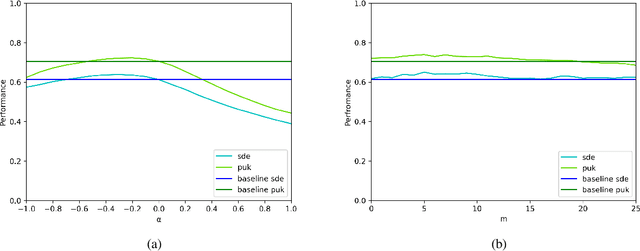

Lexical semantic change detection is a new and innovative research field. The optimal fine-tuning of models including pre- and post-processing is largely unclear. We optimize existing models by (i) pre-training on large corpora and refining on diachronic target corpora tackling the notorious small data problem, and (ii) applying post-processing transformations that have been shown to improve performance on synchronic tasks. Our results provide a guide for the application and optimization of lexical semantic change detection models across various learning scenarios.
OP-IMS @ DIACR-Ita: Back to the Roots: SGNS+OP+CD still rocks Semantic Change Detection
Nov 06, 2020

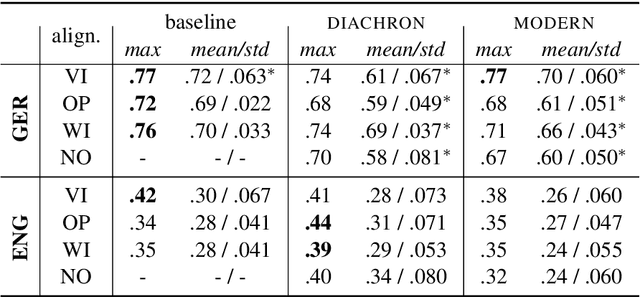
We present the results of our participation in the DIACR-Ita shared task on lexical semantic change detection for Italian. We exploit one of the earliest and most influential semantic change detection models based on Skip-Gram with Negative Sampling, Orthogonal Procrustes alignment and Cosine Distance and obtain the winning submission of the shared task with near to perfect accuracy .94. Our results once more indicate that, within the present task setup in lexical semantic change detection, the traditional type-based approaches yield excellent performance.
IMS at SemEval-2020 Task 1: How low can you go? Dimensionality in Lexical Semantic Change Detection
Aug 07, 2020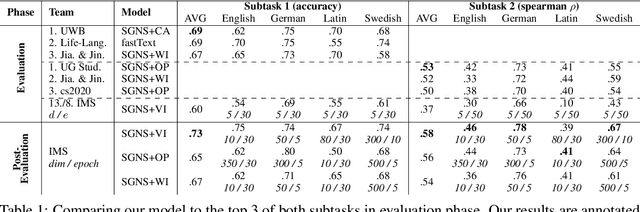
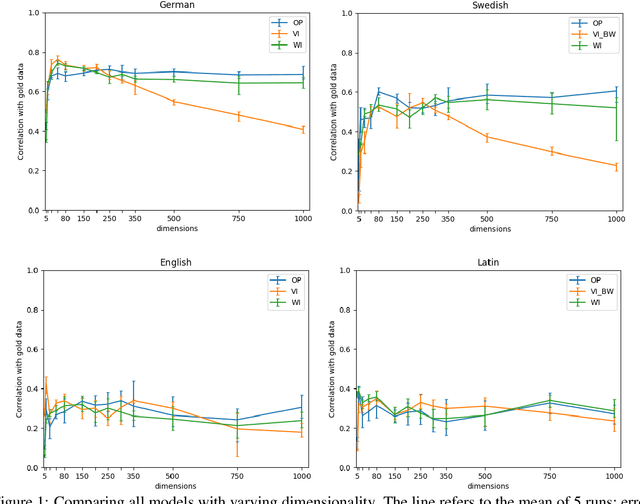
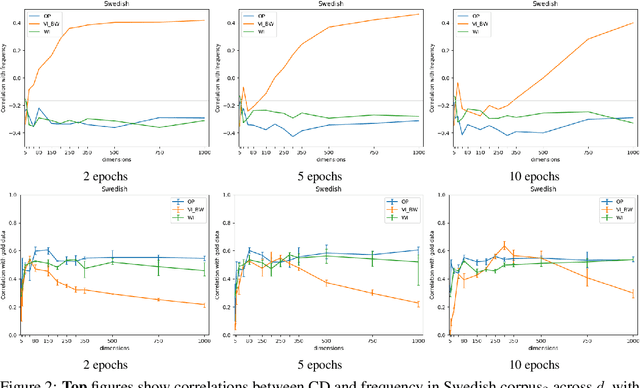

We present the results of our system for SemEval-2020 Task 1 that exploits a commonly used lexical semantic change detection model based on Skip-Gram with Negative Sampling. Our system focuses on Vector Initialization (VI) alignment, compares VI to the currently top-ranking models for Subtask 2 and demonstrates that these can be outperformed if we optimize VI dimensionality. We demonstrate that differences in performance can largely be attributed to model-specific sources of noise, and we reveal a strong relationship between dimensionality and frequency-induced noise in VI alignment. Our results suggest that lexical semantic change models integrating vector space alignment should pay more attention to the role of the dimensionality parameter.