 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMS at SemEval-2020 Task 1: How low can you go? Dimensionality in Lexical Semantic Change Detection
Paper and Code
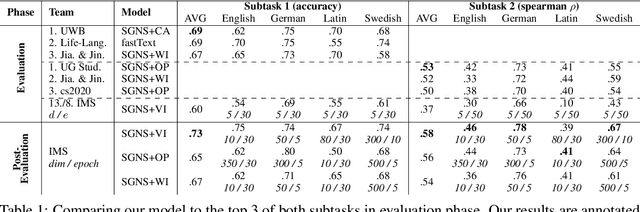
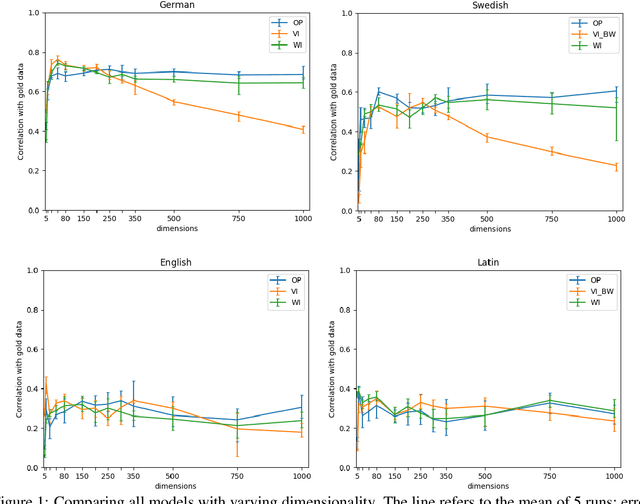
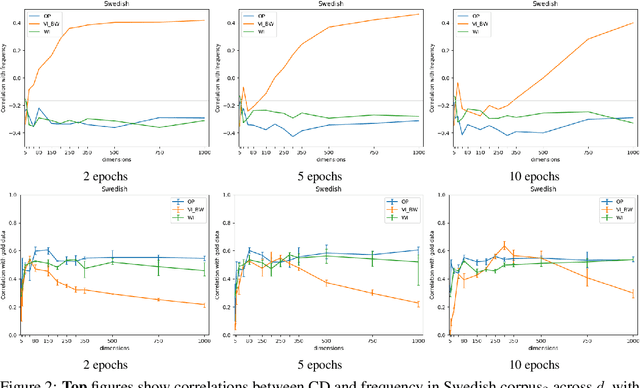

We present the results of our system for SemEval-2020 Task 1 that exploits a commonly used lexical semantic change detection model based on Skip-Gram with Negative Sampling. Our system focuses on Vector Initialization (VI) alignment, compares VI to the currently top-ranking models for Subtask 2 and demonstrates that these can be outperformed if we optimize VI dimensionality. We demonstrate that differences in performance can largely be attributed to model-specific sources of noise, and we reveal a strong relationship between dimensionality and frequency-induced noise in VI alignment. Our results suggest that lexical semantic change models integrating vector space alignment should pay more attention to the role of the dimensionality parameter.