 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Mystery of Visual Attributes of Concrete and Abstract Concepts: Variability, Nearest Neighbors, and Challenging Categories
Oct 15, 2024



The visual representation of a concept varies significantly depending on its meaning and the context where it occurs; this poses multiple challenges both for vision and multimodal models. Our study focuses on concreteness, a well-researched lexical-semantic variable, using it as a case study to examine the variability in visual representations. We rely on images associated with approximately 1,000 abstract and concrete concepts extracted from two different datasets: Bing and YFCC. Our goals are: (i) evaluate whether visual diversity in the depiction of concepts can reliably distinguish between concrete and abstract concepts; (ii) analyze the variability of visual features across multiple images of the same concept through a nearest neighbor analysis; and (iii) identify challenging factors contributing to this variability by categorizing and annotating images. Our findings indicate that for classifying images of abstract versus concrete concepts, a combination of basic visual features such as color and texture is more effective than features extracted by more complex models like Vision Transformer (ViT). However, ViTs show better performances in the nearest neighbor analysis, emphasizing the need for a careful selection of visual features when analyzing conceptual variables through modalities other than text.
Reducing Overlearning through Disentangled Representations by Suppressing Unknown Tasks
May 20, 2020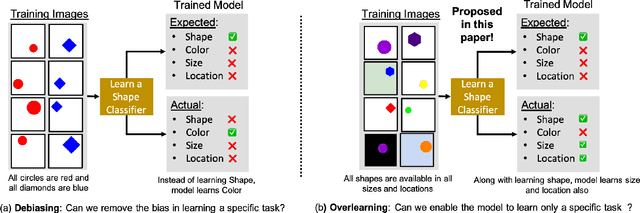
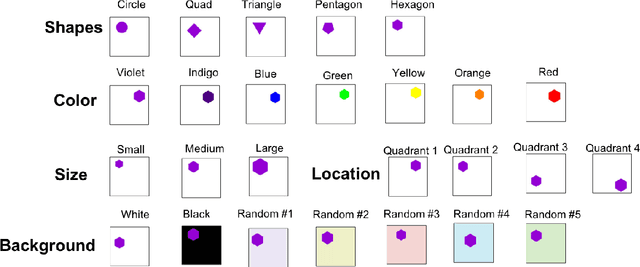
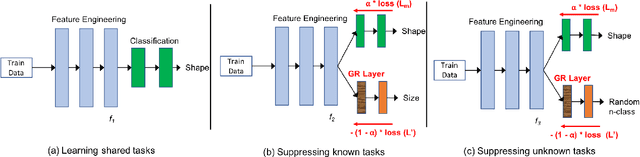
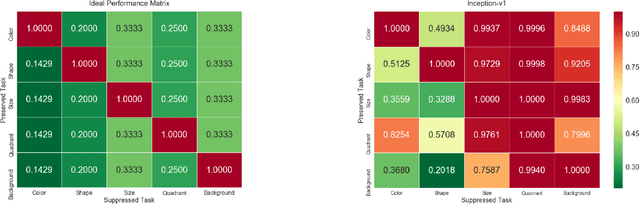
Existing deep learning approaches for learning visual features tend to overlearn and extract more information than what is required for the task at hand. From a privacy preservation perspective, the input visual information is not protected from the model; enabling the model to become more intelligent than it is trained to be. Current approaches for suppressing additional task learning assume the presence of ground truth labels for the tasks to be suppressed during training time. In this research, we propose a three-fold novel contribution: (i) a model-agnostic solution for reducing model overlearning by suppressing all the unknown tasks, (ii) a novel metric to measure the trust score of a trained deep learning model, and (iii) a simulated benchmark dataset, PreserveTask, having five different fundamental image classification tasks to study the generalization nature of models. In the first set of experiments, we learn disentangled representations and suppress overlearning of five popular deep learning models: VGG16, VGG19, Inception-v1, MobileNet, and DenseNet on PreserverTask dataset. Additionally, we show results of our framework on color-MNIST dataset and practical applications of face attribute preservation in Diversity in Faces (DiF) and IMDB-Wiki dataset.