 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Causal Inference for Data-free Structured Pruning
Dec 19, 2021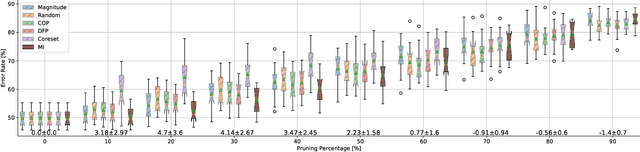
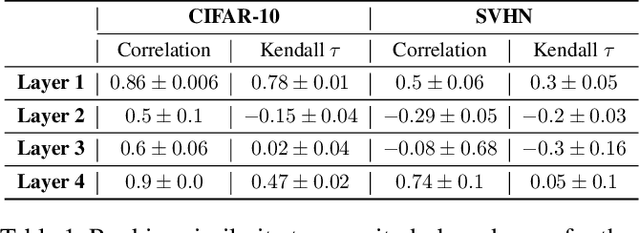
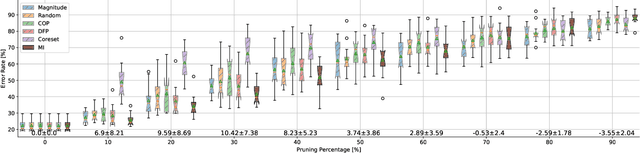

Neural networks (NNs) are making a large impact both on research and industry. Nevertheless, as NNs' accuracy increases, it is followed by an expansion in their size, required number of compute operations and energy consumption. Increase in resource consumption results in NNs' reduced adoption rate and real-world deployment impracticality. Therefore, NNs need to be compressed to make them available to a wider audience and at the same time decrease their runtime costs. In this work, we approach this challenge from a causal inference perspective, and we propose a scoring mechanism to facilitate structured pruning of NNs. The approach is based on measuring mutual information under a maximum entropy perturbation, sequentially propagated through the NN. We demonstrate the method's performance on two datasets and various NNs' sizes, and we show that our approach achieves competitive performance under challenging conditions.
Deeplite Neutrino: An End-to-End Framework for Constrained Deep Learning Model Optimization
Jan 13, 2021
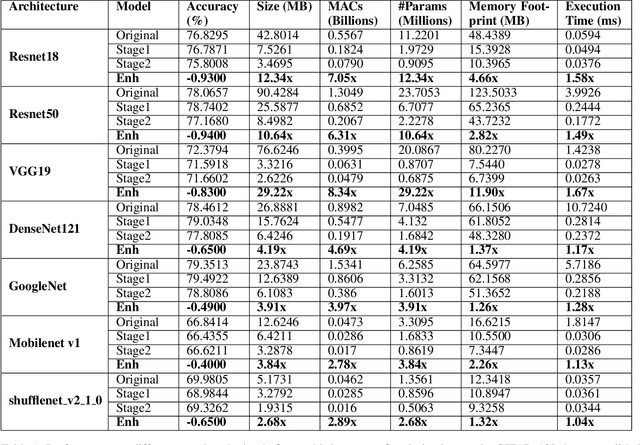
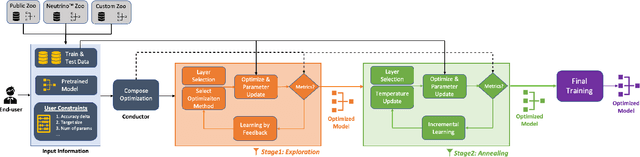
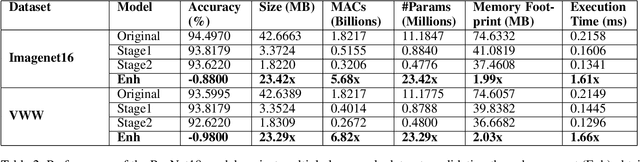
Designing deep learning-based solutions is becoming a race for training deeper models with a greater number of layers. While a large-size deeper model could provide competitive accuracy, it creates a lot of logistical challenges and unreasonable resource requirements during development and deployment. This has been one of the key reasons for deep learning models not being excessively used in various production environments, especially in edge devices. There is an immediate requirement for optimizing and compressing these deep learning models, to enable on-device intelligence. In this research, we introduce a black-box framework, Deeplite Neutrino for production-ready optimization of deep learning models. The framework provides an easy mechanism for the end-users to provide constraints such as a tolerable drop in accuracy or target size of the optimized models, to guide the whole optimization process. The framework is easy to include in an existing production pipeline and is available as a Python Package, supporting PyTorch and Tensorflow libraries. The optimization performance of the framework is shown across multiple benchmark datasets and popular deep learning models. Further, the framework is currently used in production and the results and testimonials from several clients are summarized.
Reducing Overlearning through Disentangled Representations by Suppressing Unknown Tasks
May 20, 2020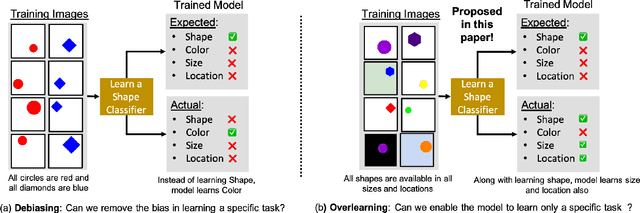
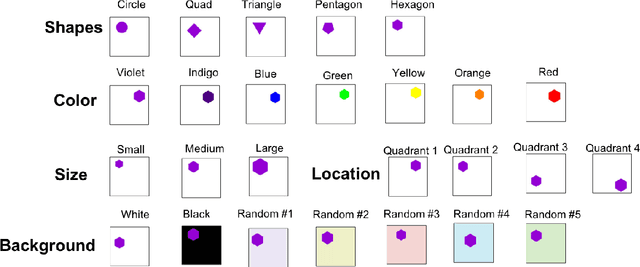
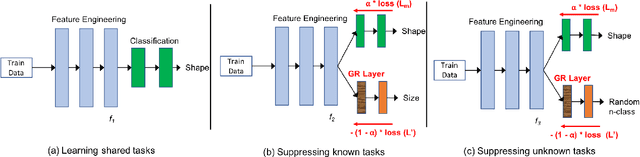
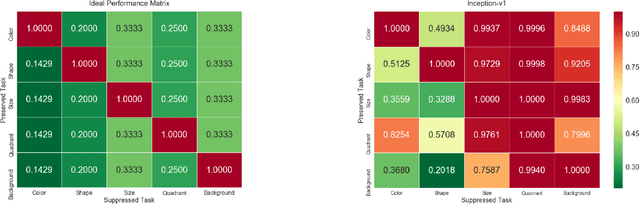
Existing deep learning approaches for learning visual features tend to overlearn and extract more information than what is required for the task at hand. From a privacy preservation perspective, the input visual information is not protected from the model; enabling the model to become more intelligent than it is trained to be. Current approaches for suppressing additional task learning assume the presence of ground truth labels for the tasks to be suppressed during training time. In this research, we propose a three-fold novel contribution: (i) a model-agnostic solution for reducing model overlearning by suppressing all the unknown tasks, (ii) a novel metric to measure the trust score of a trained deep learning model, and (iii) a simulated benchmark dataset, PreserveTask, having five different fundamental image classification tasks to study the generalization nature of models. In the first set of experiments, we learn disentangled representations and suppress overlearning of five popular deep learning models: VGG16, VGG19, Inception-v1, MobileNet, and DenseNet on PreserverTask dataset. Additionally, we show results of our framework on color-MNIST dataset and practical applications of face attribute preservation in Diversity in Faces (DiF) and IMDB-Wiki dataset.
"You might also like this model": Data Driven Approach for Recommending Deep Learning Models for Unknown Image Datasets
Nov 26, 2019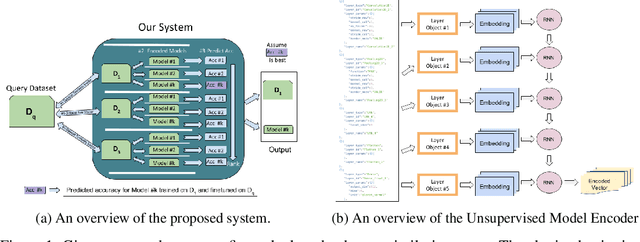
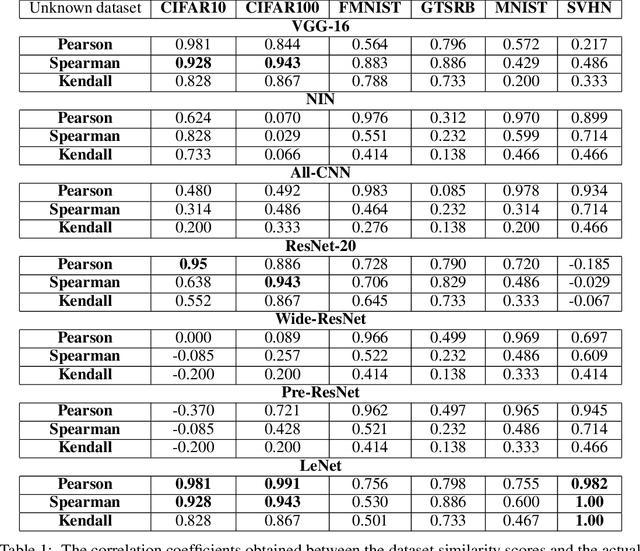
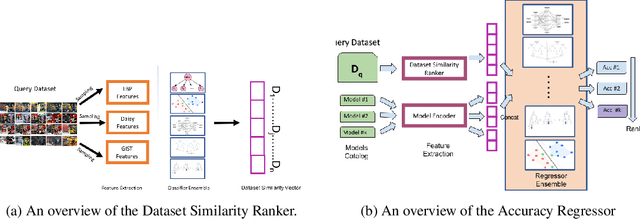

For an unknown (new) classification dataset, choosing an appropriate deep learning architecture is often a recursive, time-taking, and laborious process. In this research, we propose a novel technique to recommend a suitable architecture from a repository of known models. Further, we predict the performance accuracy of the recommended architecture on the given unknown dataset, without the need for training the model. We propose a model encoder approach to learn a fixed length representation of deep learning architectures along with its hyperparameters, in an unsupervised fashion. We manually curate a repository of image datasets with corresponding known deep learning models and show that the predicted accuracy is a good estimator of the actual accuracy. We discuss the implications of the proposed approach for three benchmark images datasets and also the challenges in using the approach for text modality. To further increase the reproducibility of the proposed approach, the entire implementation is made publicly available along with the trained models.
AuthorGAN: Improving GAN Reproducibility using a Modular GAN Framework
Nov 26, 2019
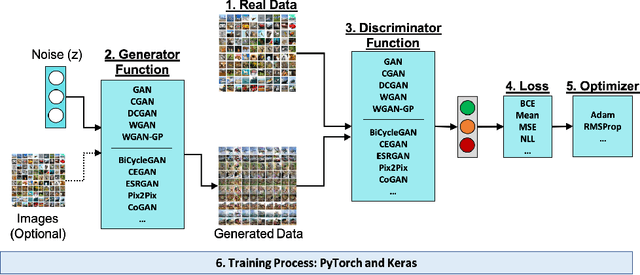
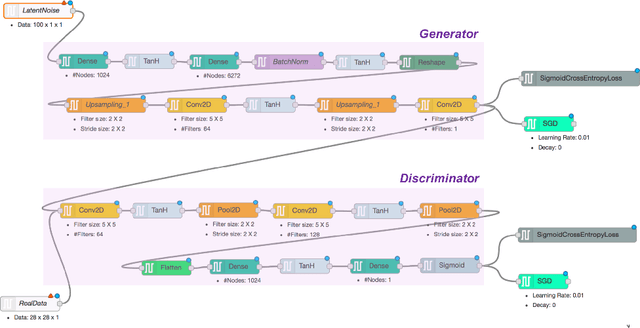
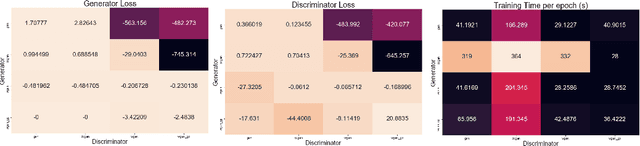
Generative models are becoming increasingly popular in the literature, with Generative Adversarial Networks (GAN) being the most successful variant, yet. With this increasing demand and popularity, it is becoming equally difficult and challenging to implement and consume GAN models. A qualitative user survey conducted across 47 practitioners show that expert level skill is required to use GAN model for a given task, despite the presence of various open source libraries. In this research, we propose a novel system called AuthorGAN, aiming to achieve true democratization of GAN authoring. A highly modularized library agnostic representation of GAN model is defined to enable interoperability of GAN architecture across different libraries such as Keras, Tensorflow, and PyTorch. An intuitive drag-and-drop based visual designer is built using node-red platform to enable custom architecture designing without the need for writing any code. Five different GAN models are implemented as a part of this framework and the performance of the different GAN models are shown using the benchmark MNIST dataset.
Coverage Testing of Deep Learning Models using Dataset Characterization
Nov 17, 2019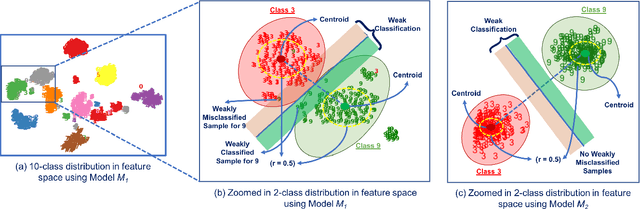

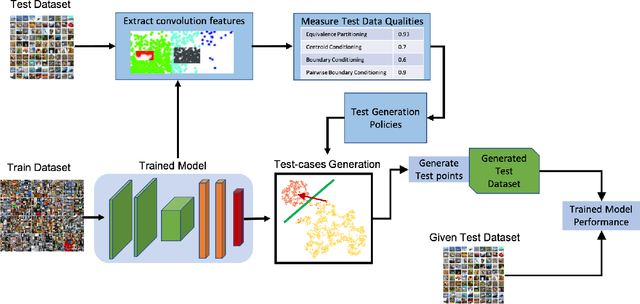

Deep Neural Networks (DNNs), with its promising performance, are being increasingly used in safety critical applications such as autonomous driving, cancer detection, and secure authentication. With growing importance in deep learning, there is a requirement for a more standardized framework to evaluate and test deep learning models. The primary challenge involved in automated generation of extensive test cases are: (i) neural networks are difficult to interpret and debug and (ii) availability of human annotators to generate specialized test points. In this research, we explain the necessity to measure the quality of a dataset and propose a test case generation system guided by the dataset properties. From a testing perspective, four different dataset quality dimensions are proposed: (i) equivalence partitioning, (ii) centroid positioning, (iii) boundary conditioning, and (iv) pair-wise boundary conditioning. The proposed system is evaluated on well known image classification datasets such as MNIST, Fashion-MNIST, CIFAR10, CIFAR100, and SVHN against popular deep learning models such as LeNet, ResNet-20, VGG-19. Further, we conduct various experiments to demonstrate the effectiveness of systematic test case generation system for evaluating deep learning models.
A Visual Programming Paradigm for Abstract Deep Learning Model Development
May 07, 2019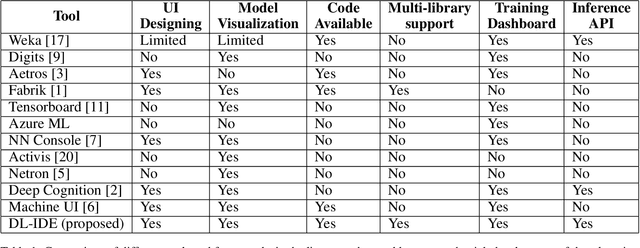
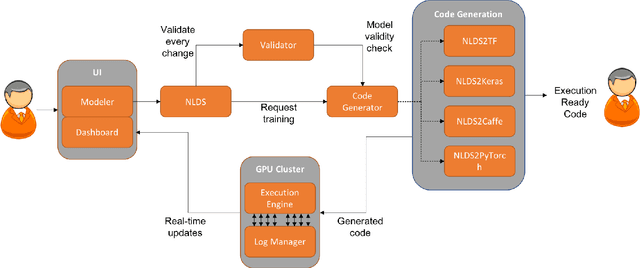
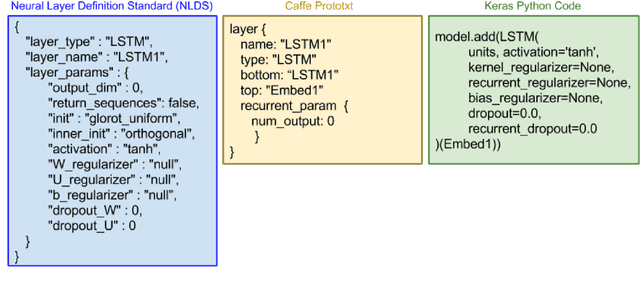
Deep learning is one of the fastest growing technologies in computer science with a plethora of applications. But this unprecedented growth has so far been limited to the consumption of deep learning experts. The primary challenge being a steep learning curve for learning the programming libraries and the lack of intuitive systems enabling non-experts to consume deep learning. Towards this goal, we study the effectiveness of a no-code paradigm for designing deep learning models. Particularly, a visual drag-and-drop interface is found more efficient when compared with the traditional programming and alternative visual programming paradigms. We conduct user studies of different expertise levels to measure the entry level barrier and the developer load across different programming paradigms. We obtain a System Usability Scale (SUS) of 90 and a NASA Task Load index (TLX) score of 21 for the proposed visual programming compared to 68 and 52, respectively, for the traditional programming methods.
On Matching Faces with Alterations due to Plastic Surgery and Disguise
Nov 18, 2018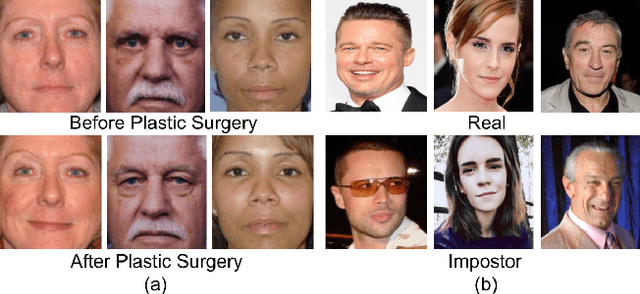
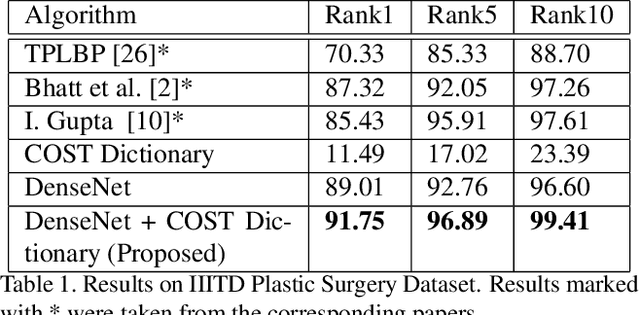
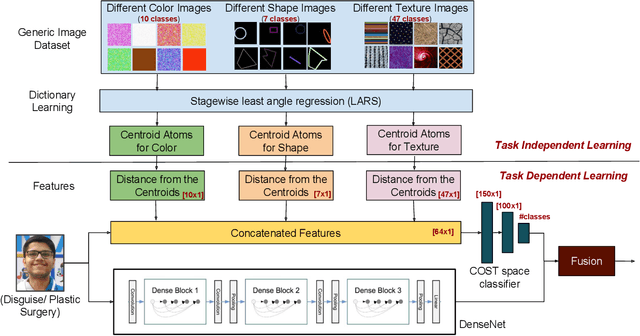

Plastic surgery and disguise variations are two of the most challenging co-variates of face recognition. The state-of-art deep learning models are not sufficiently successful due to the availability of limited training samples. In this paper, a novel framework is proposed which transfers fundamental visual features learnt from a generic image dataset to supplement a supervised face recognition model. The proposed algorithm combines off-the-shelf supervised classifier and a generic, task independent network which encodes information related to basic visual cues such as color, shape, and texture. Experiments are performed on IIITD plastic surgery face dataset and Disguised Faces in the Wild (DFW) dataset. Results showcase that the proposed algorithm achieves state of the art results on both the datasets. Specifically on the DFW database, the proposed algorithm yields over 87% verification accuracy at 1% false accept rate which is 53.8% better than baseline results computed using VGGFace.
Explaining Deep Learning Models using Causal Inference
Nov 11, 2018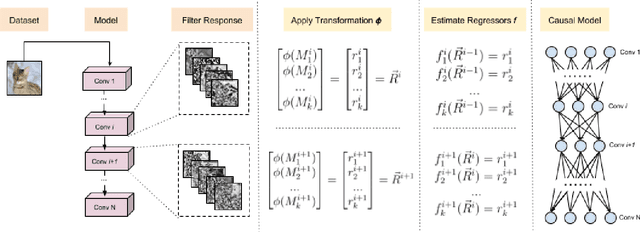
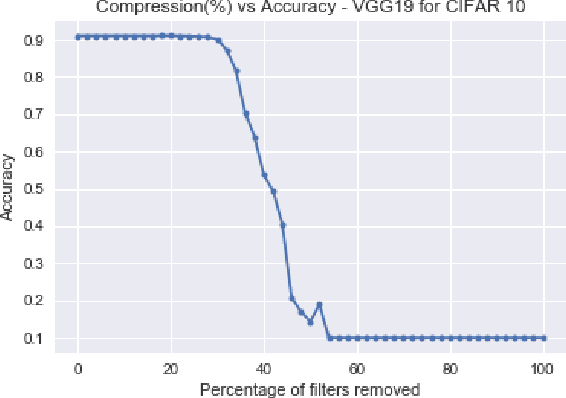

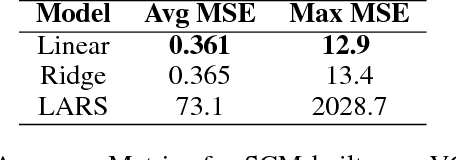
Although deep learning models have been successfully applied to a variety of tasks, due to the millions of parameters, they are becoming increasingly opaque and complex. In order to establish trust for their widespread commercial use, it is important to formalize a principled framework to reason over these models. In this work, we use ideas from causal inference to describe a general framework to reason over CNN models. Specifically, we build a Structural Causal Model (SCM) as an abstraction over a specific aspect of the CNN. We also formulate a method to quantitatively rank the filters of a convolution layer according to their counterfactual importance. We illustrate our approach with popular CNN architectures such as LeNet5, VGG19, and ResNet32.
Sanskrit Sandhi Splitting using $\pmb{seq2^2}$
Aug 27, 2018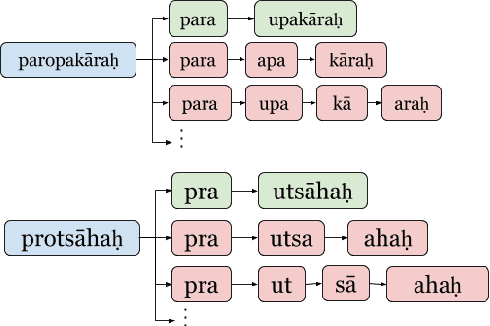
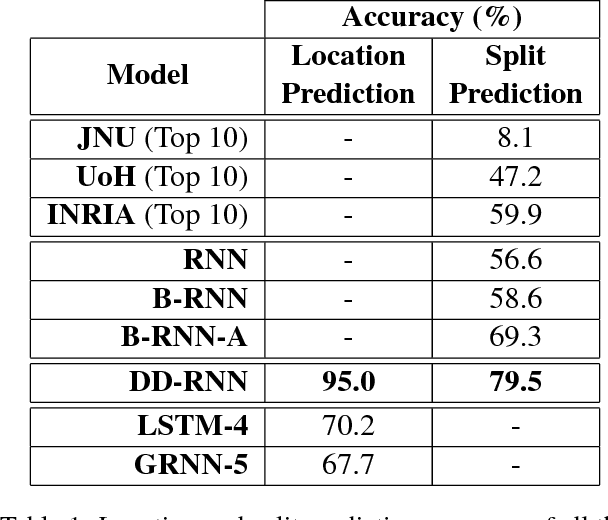
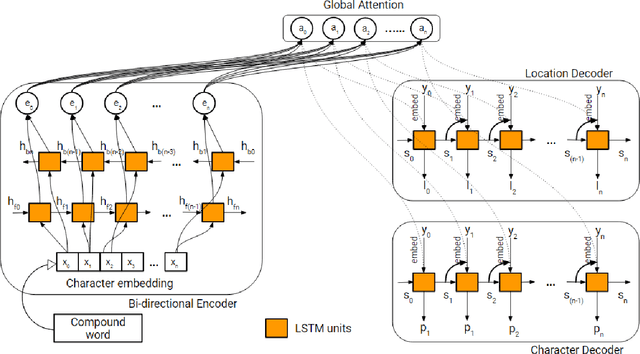
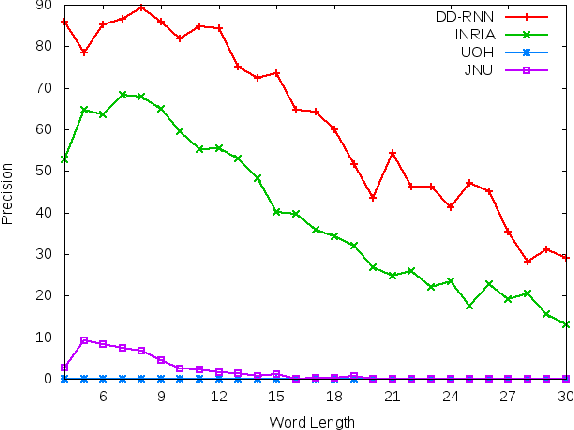
In Sanskrit, small words (morphemes) are combined to form compound words through a process known as Sandhi. Sandhi splitting is the process of splitting a given compound word into its constituent morphemes. Although rules governing word splitting exists in the language, it is highly challenging to identify the location of the splits in a compound word. Though existing Sandhi splitting systems incorporate these pre-defined splitting rules, they have a low accuracy as the same compound word might be broken down in multiple ways to provide syntactically correct splits. In this research, we propose a novel deep learning architecture called Double Decoder RNN (DD-RNN), which (i) predicts the location of the split(s) with 95% accuracy, and (ii) predicts the constituent words (learning the Sandhi splitting rules) with 79.5% accuracy, outperforming the state-of-art by 20%. Additionally, we show the generalization capability of our deep learning model, by showing competitive results in the problem of Chinese word segmentation, as well.