 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoverage Testing of Deep Learning Models using Dataset Characterization
Nov 17, 2019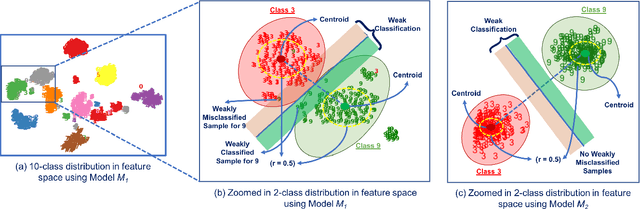

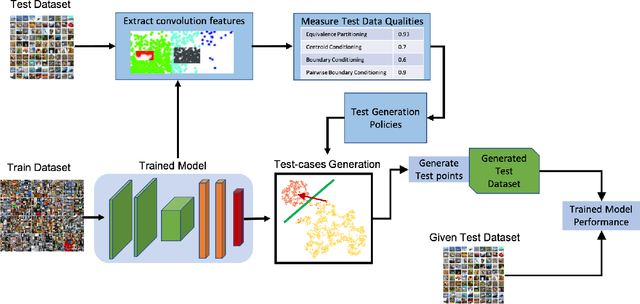

Deep Neural Networks (DNNs), with its promising performance, are being increasingly used in safety critical applications such as autonomous driving, cancer detection, and secure authentication. With growing importance in deep learning, there is a requirement for a more standardized framework to evaluate and test deep learning models. The primary challenge involved in automated generation of extensive test cases are: (i) neural networks are difficult to interpret and debug and (ii) availability of human annotators to generate specialized test points. In this research, we explain the necessity to measure the quality of a dataset and propose a test case generation system guided by the dataset properties. From a testing perspective, four different dataset quality dimensions are proposed: (i) equivalence partitioning, (ii) centroid positioning, (iii) boundary conditioning, and (iv) pair-wise boundary conditioning. The proposed system is evaluated on well known image classification datasets such as MNIST, Fashion-MNIST, CIFAR10, CIFAR100, and SVHN against popular deep learning models such as LeNet, ResNet-20, VGG-19. Further, we conduct various experiments to demonstrate the effectiveness of systematic test case generation system for evaluating deep learning models.
Relational Representation Learning for Dynamic (Knowledge) Graphs: A Survey
May 27, 2019
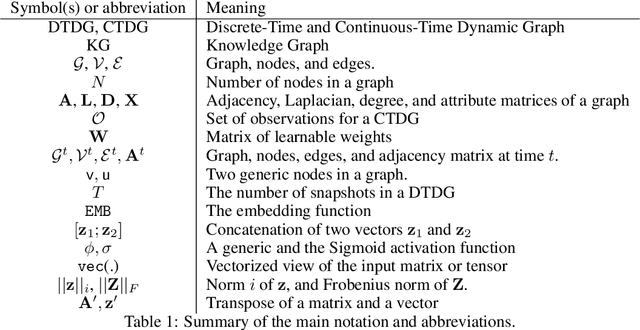
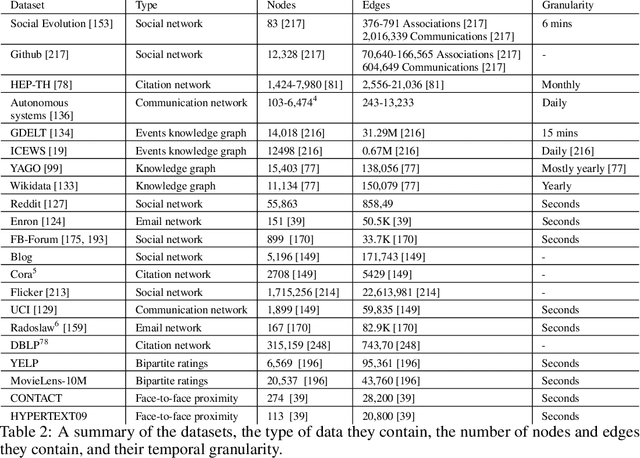
Graphs arise naturally in many real-world applications including social networks, recommender systems, ontologies, biology, and computational finance. Traditionally, machine learning models for graphs have been mostly designed for static graphs. However, many applications involve evolving graphs. This introduces important challenges for learning and inference since nodes, attributes, and edges change over time. In this survey, we review the recent advances in representation learning for dynamic graphs, including dynamic knowledge graphs. We describe existing models from an encoder-decoder perspective, categorize these encoders and decoders based on the techniques they employ, and analyze the approaches in each category. We also review several prominent applications and widely used datasets, and highlight directions for future research.
Residual Codean Autoencoder for Facial Attribute Analysis
Mar 20, 2018


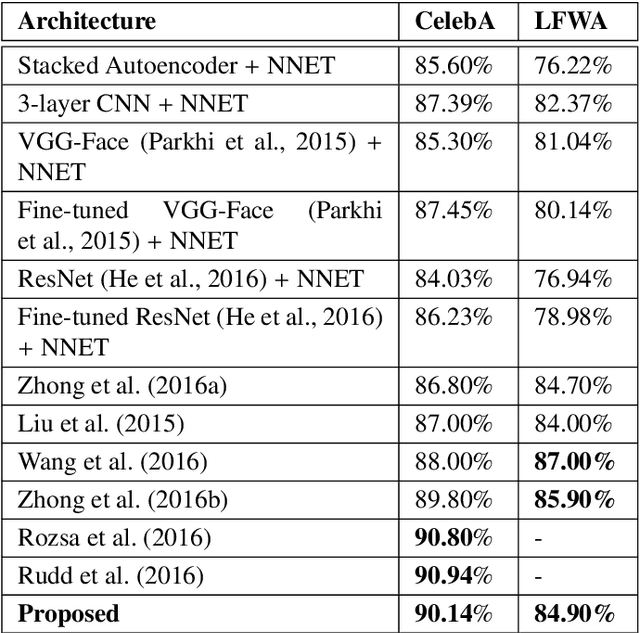
Facial attributes can provide rich ancillary information which can be utilized for different applications such as targeted marketing, human computer interaction, and law enforcement. This research focuses on facial attribute prediction using a novel deep learning formulation, termed as R-Codean autoencoder. The paper first presents Cosine similarity based loss function in an autoencoder which is then incorporated into the Euclidean distance based autoencoder to formulate R-Codean. The proposed loss function thus aims to incorporate both magnitude and direction of image vectors during feature learning. Further, inspired by the utility of shortcut connections in deep models to facilitate learning of optimal parameters, without incurring the problem of vanishing gradient, the proposed formulation is extended to incorporate shortcut connections in the architecture. The proposed R-Codean autoencoder is utilized in facial attribute prediction framework which incorporates patch-based weighting mechanism for assigning higher weights to relevant patches for each attribute. The experimental results on publicly available CelebA and LFWA datasets demonstrate the efficacy of the proposed approach in addressing this challenging problem.
DLPaper2Code: Auto-generation of Code from Deep Learning Research Papers
Nov 09, 2017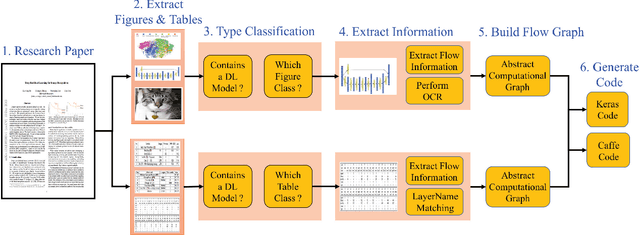
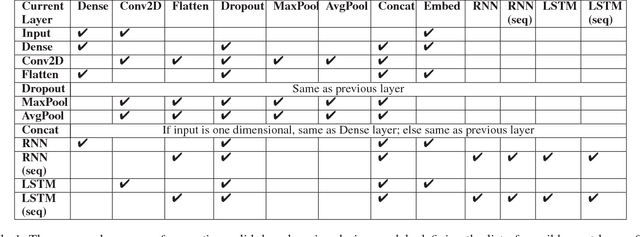

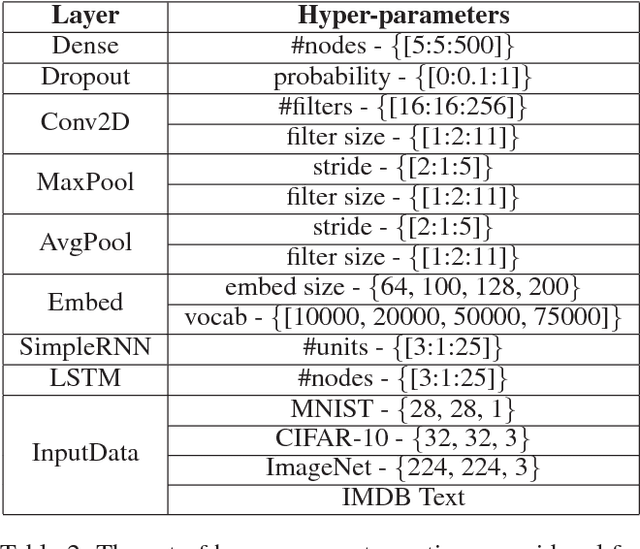
With an abundance of research papers in deep learning, reproducibility or adoption of the existing works becomes a challenge. This is due to the lack of open source implementations provided by the authors. Further, re-implementing research papers in a different library is a daunting task. To address these challenges, we propose a novel extensible approach, DLPaper2Code, to extract and understand deep learning design flow diagrams and tables available in a research paper and convert them to an abstract computational graph. The extracted computational graph is then converted into execution ready source code in both Keras and Caffe, in real-time. An arXiv-like website is created where the automatically generated designs is made publicly available for 5,000 research papers. The generated designs could be rated and edited using an intuitive drag-and-drop UI framework in a crowdsourced manner. To evaluate our approach, we create a simulated dataset with over 216,000 valid design visualizations using a manually defined grammar. Experiments on the simulated dataset show that the proposed framework provide more than $93\%$ accuracy in flow diagram content extraction.