 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Black-Box Attacks On Text Classifiers Using Multi-Objective Genetic Optimization Guided By Deep Networks
Nov 10, 2020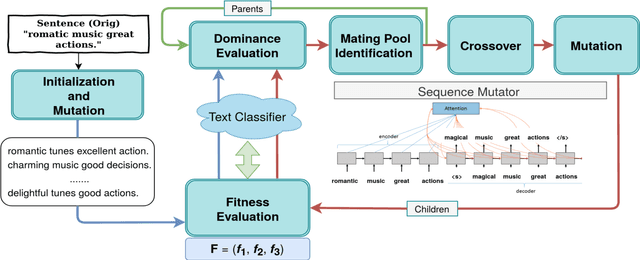

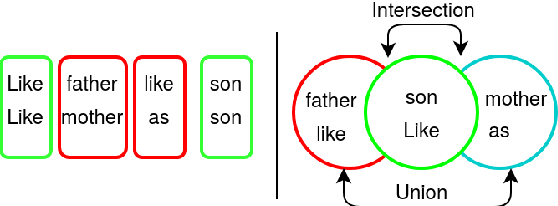

We propose a novel genetic-algorithm technique that generates black-box adversarial examples which successfully fool neural network based text classifiers. We perform a genetic search with multi-objective optimization guided by deep learning based inferences and Seq2Seq mutation to generate semantically similar but imperceptible adversaries. We compare our approach with DeepWordBug (DWB) on SST and IMDB sentiment datasets by attacking three trained models viz. char-LSTM, word-LSTM and elmo-LSTM. On an average, we achieve an attack success rate of 65.67% for SST and 36.45% for IMDB across the three models showing an improvement of 49.48% and 101% respectively. Furthermore, our qualitative study indicates that 94% of the time, the users were not able to distinguish between an original and adversarial sample.
Reducing Overlearning through Disentangled Representations by Suppressing Unknown Tasks
May 20, 2020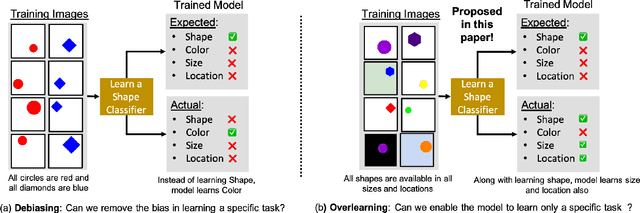
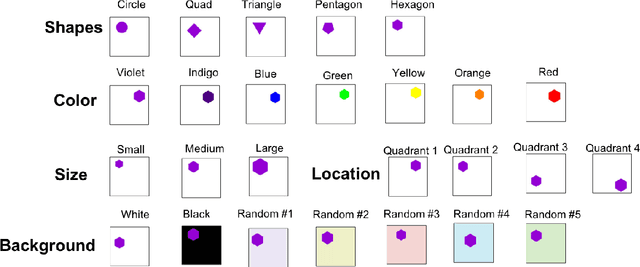
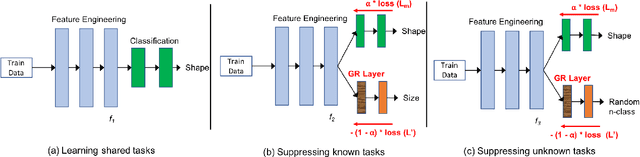
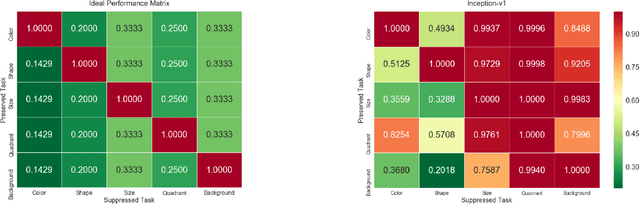
Existing deep learning approaches for learning visual features tend to overlearn and extract more information than what is required for the task at hand. From a privacy preservation perspective, the input visual information is not protected from the model; enabling the model to become more intelligent than it is trained to be. Current approaches for suppressing additional task learning assume the presence of ground truth labels for the tasks to be suppressed during training time. In this research, we propose a three-fold novel contribution: (i) a model-agnostic solution for reducing model overlearning by suppressing all the unknown tasks, (ii) a novel metric to measure the trust score of a trained deep learning model, and (iii) a simulated benchmark dataset, PreserveTask, having five different fundamental image classification tasks to study the generalization nature of models. In the first set of experiments, we learn disentangled representations and suppress overlearning of five popular deep learning models: VGG16, VGG19, Inception-v1, MobileNet, and DenseNet on PreserverTask dataset. Additionally, we show results of our framework on color-MNIST dataset and practical applications of face attribute preservation in Diversity in Faces (DiF) and IMDB-Wiki dataset.
Benchmarking Popular Classification Models' Robustness to Random and Targeted Corruptions
Jan 31, 2020
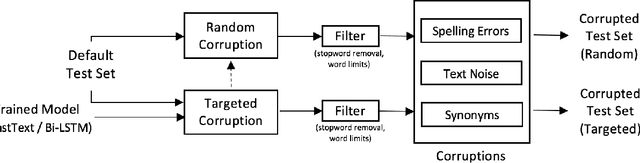

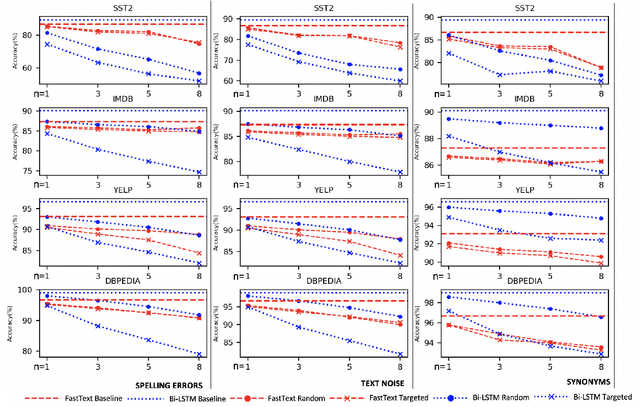
Text classification models, especially neural networks based models, have reached very high accuracy on many popular benchmark datasets. Yet, such models when deployed in real world applications, tend to perform badly. The primary reason is that these models are not tested against sufficient real world natural data. Based on the application users, the vocabulary and the style of the model's input may greatly vary. This emphasizes the need for a model agnostic test dataset, which consists of various corruptions that are natural to appear in the wild. Models trained and tested on such benchmark datasets, will be more robust against real world data. However, such data sets are not easily available. In this work, we address this problem, by extending the benchmark datasets along naturally occurring corruptions such as Spelling Errors, Text Noise and Synonyms and making them publicly available. Through extensive experiments, we compare random and targeted corruption strategies using Local Interpretable Model-Agnostic Explanations(LIME). We report the vulnerabilities in two popular text classification models along these corruptions and also find that targeted corruptions can expose vulnerabilities of a model better than random choices in most cases.
"You might also like this model": Data Driven Approach for Recommending Deep Learning Models for Unknown Image Datasets
Nov 26, 2019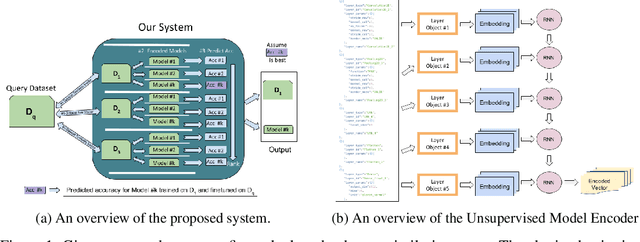
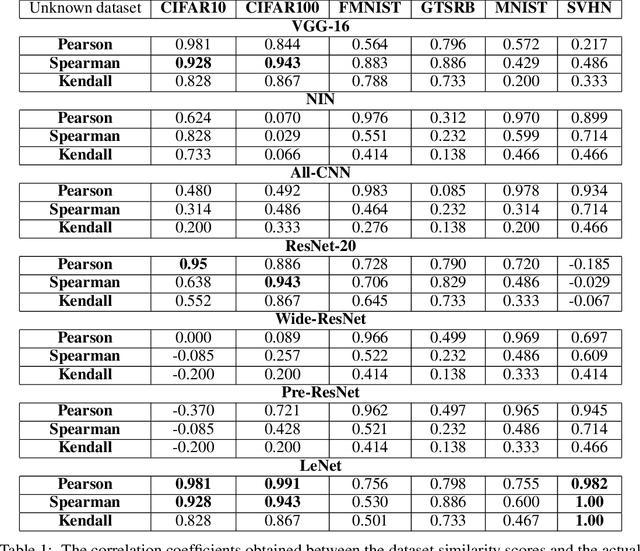
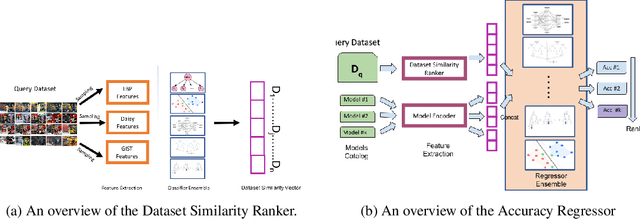

For an unknown (new) classification dataset, choosing an appropriate deep learning architecture is often a recursive, time-taking, and laborious process. In this research, we propose a novel technique to recommend a suitable architecture from a repository of known models. Further, we predict the performance accuracy of the recommended architecture on the given unknown dataset, without the need for training the model. We propose a model encoder approach to learn a fixed length representation of deep learning architectures along with its hyperparameters, in an unsupervised fashion. We manually curate a repository of image datasets with corresponding known deep learning models and show that the predicted accuracy is a good estimator of the actual accuracy. We discuss the implications of the proposed approach for three benchmark images datasets and also the challenges in using the approach for text modality. To further increase the reproducibility of the proposed approach, the entire implementation is made publicly available along with the trained models.
Coverage Testing of Deep Learning Models using Dataset Characterization
Nov 17, 2019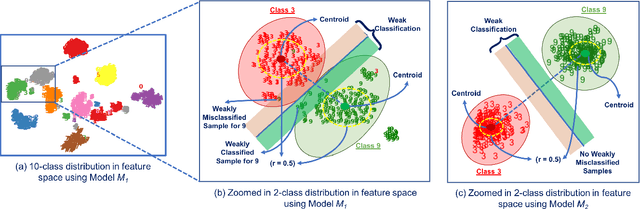

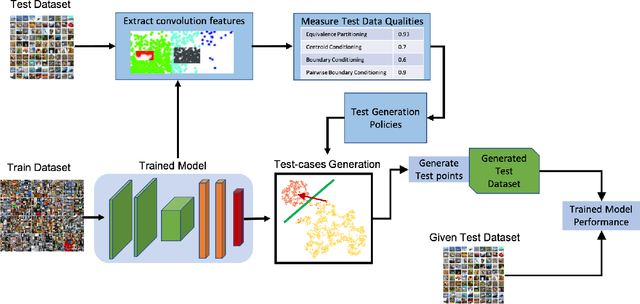

Deep Neural Networks (DNNs), with its promising performance, are being increasingly used in safety critical applications such as autonomous driving, cancer detection, and secure authentication. With growing importance in deep learning, there is a requirement for a more standardized framework to evaluate and test deep learning models. The primary challenge involved in automated generation of extensive test cases are: (i) neural networks are difficult to interpret and debug and (ii) availability of human annotators to generate specialized test points. In this research, we explain the necessity to measure the quality of a dataset and propose a test case generation system guided by the dataset properties. From a testing perspective, four different dataset quality dimensions are proposed: (i) equivalence partitioning, (ii) centroid positioning, (iii) boundary conditioning, and (iv) pair-wise boundary conditioning. The proposed system is evaluated on well known image classification datasets such as MNIST, Fashion-MNIST, CIFAR10, CIFAR100, and SVHN against popular deep learning models such as LeNet, ResNet-20, VGG-19. Further, we conduct various experiments to demonstrate the effectiveness of systematic test case generation system for evaluating deep learning models.
A Visual Programming Paradigm for Abstract Deep Learning Model Development
May 07, 2019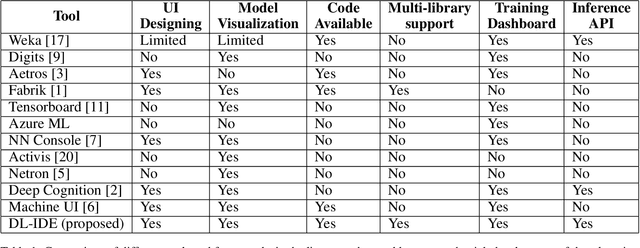
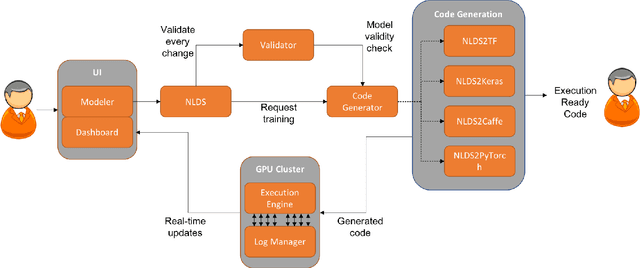
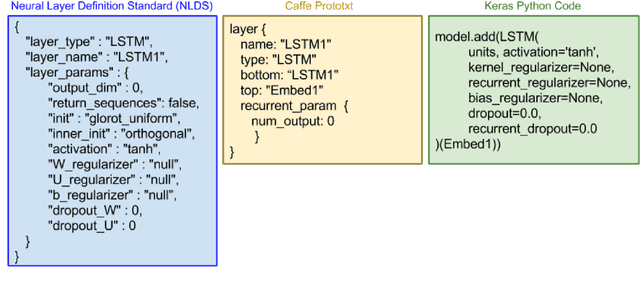
Deep learning is one of the fastest growing technologies in computer science with a plethora of applications. But this unprecedented growth has so far been limited to the consumption of deep learning experts. The primary challenge being a steep learning curve for learning the programming libraries and the lack of intuitive systems enabling non-experts to consume deep learning. Towards this goal, we study the effectiveness of a no-code paradigm for designing deep learning models. Particularly, a visual drag-and-drop interface is found more efficient when compared with the traditional programming and alternative visual programming paradigms. We conduct user studies of different expertise levels to measure the entry level barrier and the developer load across different programming paradigms. We obtain a System Usability Scale (SUS) of 90 and a NASA Task Load index (TLX) score of 21 for the proposed visual programming compared to 68 and 52, respectively, for the traditional programming methods.
Explaining Deep Learning Models using Causal Inference
Nov 11, 2018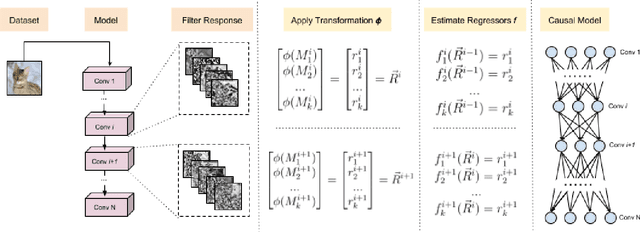
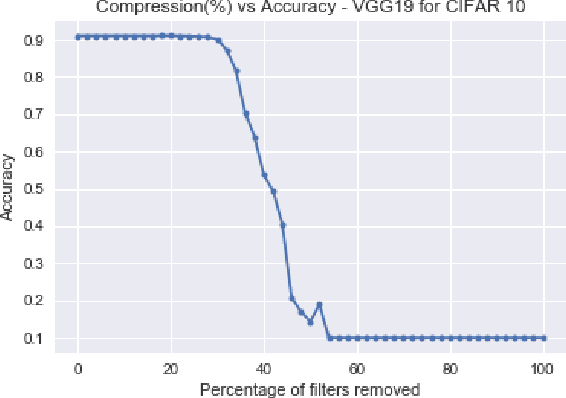

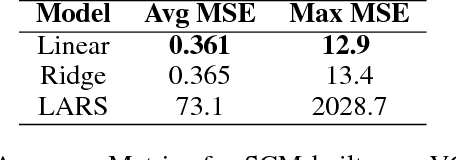
Although deep learning models have been successfully applied to a variety of tasks, due to the millions of parameters, they are becoming increasingly opaque and complex. In order to establish trust for their widespread commercial use, it is important to formalize a principled framework to reason over these models. In this work, we use ideas from causal inference to describe a general framework to reason over CNN models. Specifically, we build a Structural Causal Model (SCM) as an abstraction over a specific aspect of the CNN. We also formulate a method to quantitatively rank the filters of a convolution layer according to their counterfactual importance. We illustrate our approach with popular CNN architectures such as LeNet5, VGG19, and ResNet32.
Adversarial Black-Box Attacks for Automatic Speech Recognition Systems Using Multi-Objective Genetic Optimization
Nov 04, 2018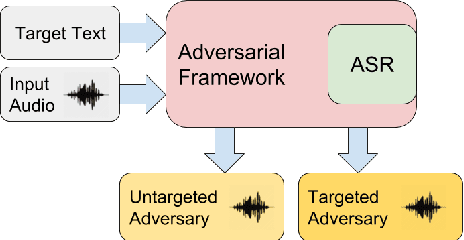

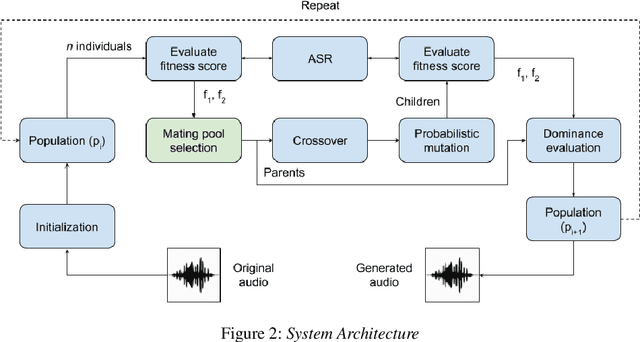
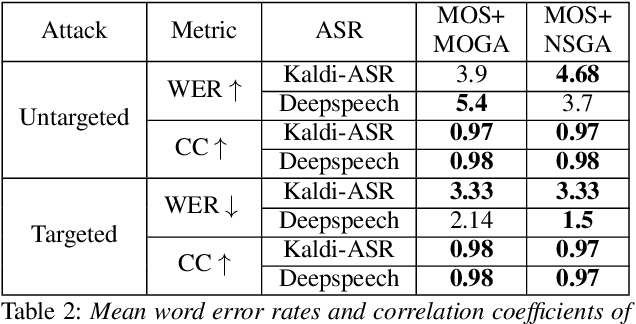
Fooling deep neural networks with adversarial input have exposed a significant vulnerability in current state-of-the-art systems in multiple domains. Both black-box and white-box approaches have been used to either replicate the model itself or to craft examples which cause the model to fail. In this work, we use a multi-objective genetic algorithm based approach to perform both targeted and un-targeted black-box attacks on automatic speech recognition (ASR) systems. The main contribution of this research is the proposal of a generic framework which can be used to attack any ASR system, even if it's internal working is hidden. During the un-targeted attacks, the Word Error Rates (WER) of the ASR degrades from 0.5 to 5.4, indicating the potency of our approach. In targeted attacks, our solution reaches a WER of 2.14. In both attacks, the adversarial samples maintain a high acoustic similarity of 0.98 and 0.97.
Sanskrit Sandhi Splitting using $\pmb{seq2^2}$
Aug 27, 2018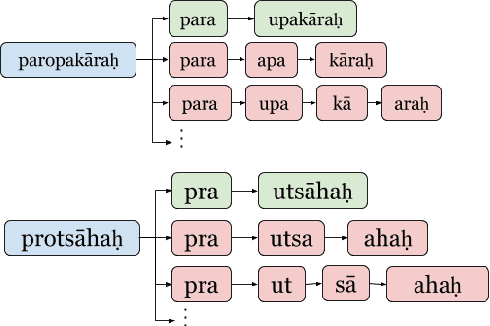
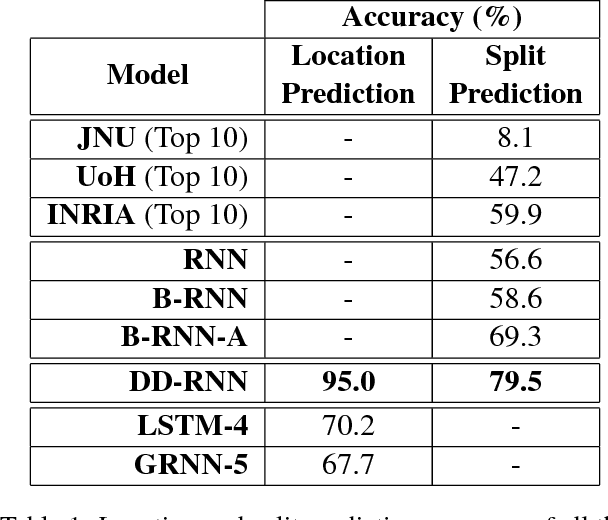
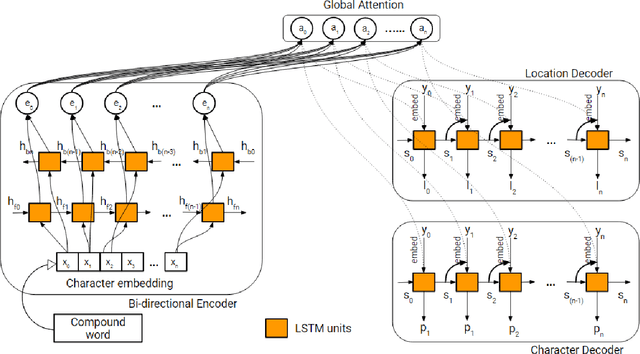
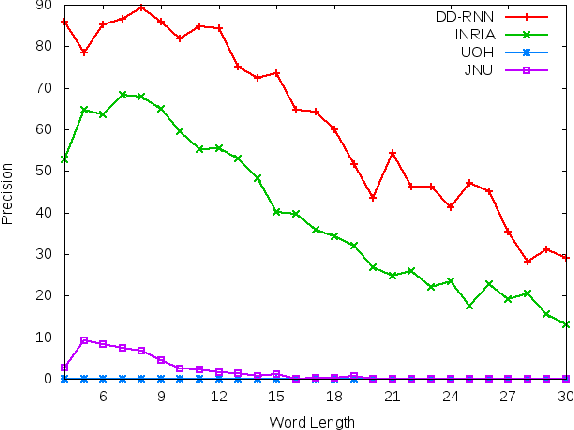
In Sanskrit, small words (morphemes) are combined to form compound words through a process known as Sandhi. Sandhi splitting is the process of splitting a given compound word into its constituent morphemes. Although rules governing word splitting exists in the language, it is highly challenging to identify the location of the splits in a compound word. Though existing Sandhi splitting systems incorporate these pre-defined splitting rules, they have a low accuracy as the same compound word might be broken down in multiple ways to provide syntactically correct splits. In this research, we propose a novel deep learning architecture called Double Decoder RNN (DD-RNN), which (i) predicts the location of the split(s) with 95% accuracy, and (ii) predicts the constituent words (learning the Sandhi splitting rules) with 79.5% accuracy, outperforming the state-of-art by 20%. Additionally, we show the generalization capability of our deep learning model, by showing competitive results in the problem of Chinese word segmentation, as well.
Fault in your stars: An Analysis of Android App Reviews
Aug 11, 2018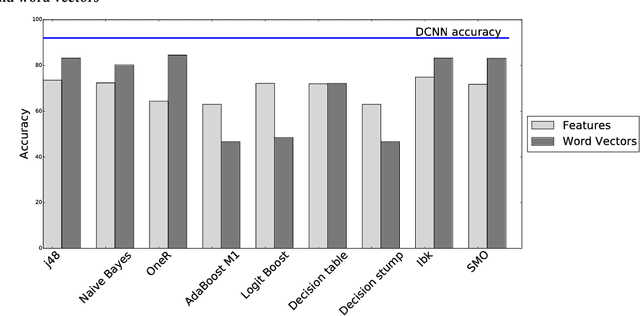
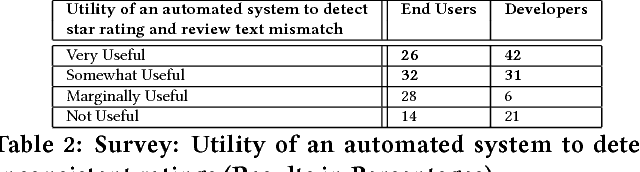
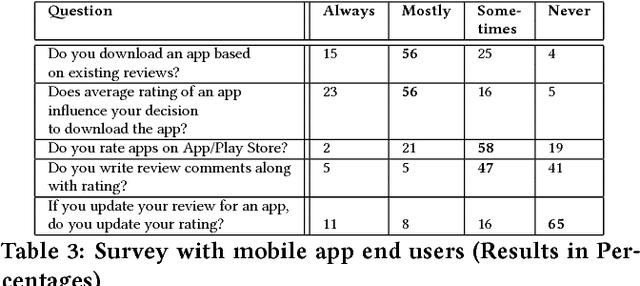
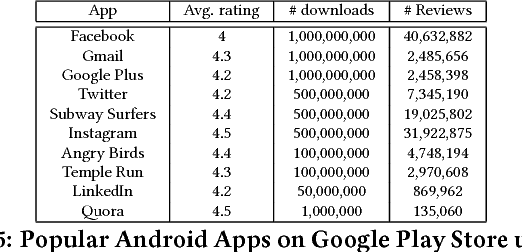
Mobile app distribution platforms such as Google Play Store allow users to share their feedback about downloaded apps in the form of a review comment and a corresponding star rating. Typically, the star rating ranges from one to five stars, with one star denoting a high sense of dissatisfaction with the app and five stars denoting a high sense of satisfaction. Unfortunately, due to a variety of reasons, often the star rating provided by a user is inconsistent with the opinion expressed in the review. For example, consider the following review for the Facebook App on Android; "Awesome App". One would reasonably expect the rating for this review to be five stars, but the actual rating is one star! Such inconsistent ratings can lead to a deflated (or inflated) overall average rating of an app which can affect user downloads, as typically users look at the average star ratings while making a decision on downloading an app. Also, the app developers receive a biased feedback about the application that does not represent ground reality. This is especially significant for small apps with a few thousand downloads as even a small number of mismatched reviews can bring down the average rating drastically. In this paper, we conducted a study on this review-rating mismatch problem. We manually examined 8600 reviews from 10 popular Android apps and found that 20% of the ratings in our dataset were inconsistent with the review. Further, we developed three systems; two of which were based on traditional machine learning and one on deep learning to automatically identify reviews whose rating did not match with the opinion expressed in the review. Our deep learning system performed the best and had an accuracy of 92% in identifying the correct star rating to be associated with a given review.