 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"You might also like this model": Data Driven Approach for Recommending Deep Learning Models for Unknown Image Datasets
Paper and Code
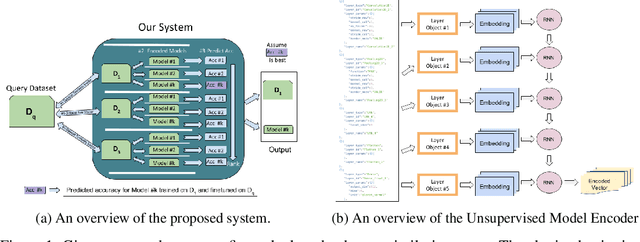
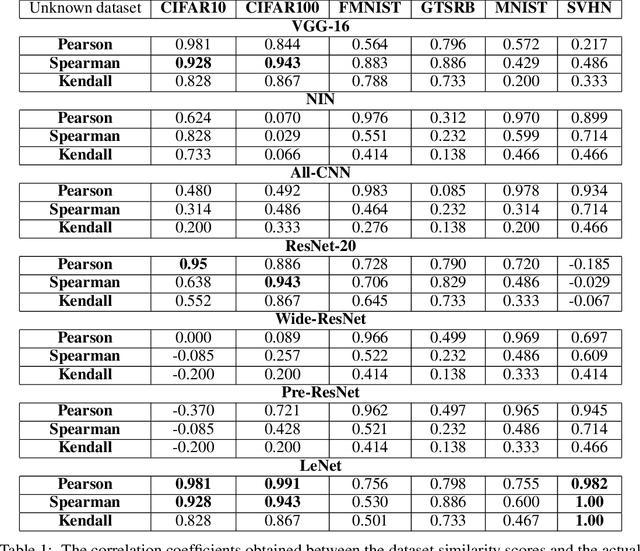
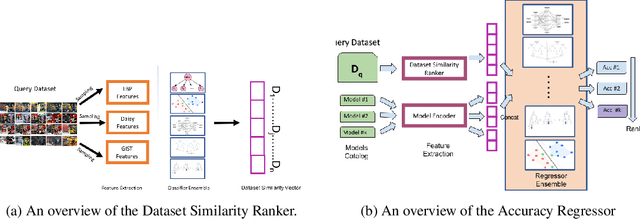

For an unknown (new) classification dataset, choosing an appropriate deep learning architecture is often a recursive, time-taking, and laborious process. In this research, we propose a novel technique to recommend a suitable architecture from a repository of known models. Further, we predict the performance accuracy of the recommended architecture on the given unknown dataset, without the need for training the model. We propose a model encoder approach to learn a fixed length representation of deep learning architectures along with its hyperparameters, in an unsupervised fashion. We manually curate a repository of image datasets with corresponding known deep learning models and show that the predicted accuracy is a good estimator of the actual accuracy. We discuss the implications of the proposed approach for three benchmark images datasets and also the challenges in using the approach for text modality. To further increase the reproducibility of the proposed approach, the entire implementation is made publicly available along with the trained models.