 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness and Reasoning Fidelity of Large Language Models in Long-Context Code Question Answering
Feb 19, 2026Large language models (LLMs) increasingly assist software engineering tasks that require reasoning over long code contexts, yet their robustness under varying input conditions remains unclear. We conduct a systematic study of long-context code question answering using controlled ablations that test sensitivity to answer format, distractors, and context scale. Extending LongCodeBench Python dataset with new COBOL and Java question-answer sets, we evaluate state-of-the-art models under three settings: (i) shuffled multiple-choice options, (ii) open-ended questions and (iii) needle-in-a-haystack contexts containing relevant and adversarially irrelevant information. Results show substantial performance drops in both shuffled multiple-choice options and open-ended questions, and brittle behavior in the presence of irrelevant cues. Our findings highlight limitations of current long-context evaluations and provide a broader benchmark for assessing code reasoning in both legacy and modern systems.
Lost in Transcription: How Speech-to-Text Errors Derail Code Understanding
Jan 20, 2026Code understanding is a foundational capability in software engineering tools and developer workflows. However, most existing systems are designed for English-speaking users interacting via keyboards, which limits accessibility in multilingual and voice-first settings, particularly in regions like India. Voice-based interfaces offer a more inclusive modality, but spoken queries involving code present unique challenges due to the presence of non-standard English usage, domain-specific vocabulary, and custom identifiers such as variable and function names, often combined with code-mixed expressions. In this work, we develop a multilingual speech-driven framework for code understanding that accepts spoken queries in a user native language, transcribes them using Automatic Speech Recognition (ASR), applies code-aware ASR output refinement using Large Language Models (LLMs), and interfaces with code models to perform tasks such as code question answering and code retrieval through benchmarks such as CodeSearchNet, CoRNStack, and CodeQA. Focusing on four widely spoken Indic languages and English, we systematically characterize how transcription errors impact downstream task performance. We also identified key failure modes in ASR for code and demonstrated that LLM-guided refinement significantly improves performance across both transcription and code understanding stages. Our findings underscore the need for code-sensitive adaptations in speech interfaces and offer a practical solution for building robust, multilingual voice-driven programming tools.
CodeSAM: Source Code Representation Learning by Infusing Self-Attention with Multi-Code-View Graphs
Nov 21, 2024



Machine Learning (ML) for software engineering (SE) has gained prominence due to its ability to significantly enhance the performance of various SE applications. This progress is largely attributed to the development of generalizable source code representations that effectively capture the syntactic and semantic characteristics of code. In recent years, pre-trained transformer-based models, inspired by natural language processing (NLP), have shown remarkable success in SE tasks. However, source code contains structural and semantic properties embedded within its grammar, which can be extracted from structured code-views like the Abstract Syntax Tree (AST), Data-Flow Graph (DFG), and Control-Flow Graph (CFG). These code-views can complement NLP techniques, further improving SE tasks. Unfortunately, there are no flexible frameworks to infuse arbitrary code-views into existing transformer-based models effectively. Therefore, in this work, we propose CodeSAM, a novel scalable framework to infuse multiple code-views into transformer-based models by creating self-attention masks. We use CodeSAM to fine-tune a small language model (SLM) like CodeBERT on the downstream SE tasks of semantic code search, code clone detection, and program classification. Experimental results show that by using this technique, we improve downstream performance when compared to SLMs like GraphCodeBERT and CodeBERT on all three tasks by utilizing individual code-views or a combination of code-views during fine-tuning. We believe that these results are indicative that techniques like CodeSAM can help create compact yet performant code SLMs that fit in resource constrained settings.
ConCodeEval: Evaluating Large Language Models for Code Constraints in Domain-Specific Languages
Jul 03, 2024

Recent work shows Large Language Models (LLMs) struggle to understand natural language constraints for various text generation tasks in zero- and few-shot settings. While, in the code domain, there is wide usage of constraints in code format to maintain the integrity of code written in Domain-Specific Languages (DSLs), yet there has been no work evaluating LLMs with these constraints. We propose two novel tasks to assess the controllability of LLMs using hard and soft constraints represented as code across five representations. Our findings suggest that LLMs struggle to comprehend constraints in all representations irrespective of their portions in the pre-training data. While models are better at comprehending constraints in JSON, YAML, and natural language representations, they struggle with constraints represented in XML and the resource-rich language Python.
Read between the lines -- Functionality Extraction From READMEs
Mar 15, 2024While text summarization is a well-known NLP task, in this paper, we introduce a novel and useful variant of it called functionality extraction from Git README files. Though this task is a text2text generation at an abstract level, it involves its own peculiarities and challenges making existing text2text generation systems not very useful. The motivation behind this task stems from a recent surge in research and development activities around the use of large language models for code-related tasks, such as code refactoring, code summarization, etc. We also release a human-annotated dataset called FuncRead, and develop a battery of models for the task. Our exhaustive experimentation shows that small size fine-tuned models beat any baseline models that can be designed using popular black-box or white-box large language models (LLMs) such as ChatGPT and Bard. Our best fine-tuned 7 Billion CodeLlama model exhibit 70% and 20% gain on the F1 score against ChatGPT and Bard respectively.
COMEX: A Tool for Generating Customized Source Code Representations
Jul 10, 2023

Learning effective representations of source code is critical for any Machine Learning for Software Engineering (ML4SE) system. Inspired by natural language processing, large language models (LLMs) like Codex and CodeGen treat code as generic sequences of text and are trained on huge corpora of code data, achieving state of the art performance on several software engineering (SE) tasks. However, valid source code, unlike natural language, follows a strict structure and pattern governed by the underlying grammar of the programming language. Current LLMs do not exploit this property of the source code as they treat code like a sequence of tokens and overlook key structural and semantic properties of code that can be extracted from code-views like the Control Flow Graph (CFG), Data Flow Graph (DFG), Abstract Syntax Tree (AST), etc. Unfortunately, the process of generating and integrating code-views for every programming language is cumbersome and time consuming. To overcome this barrier, we propose our tool COMEX - a framework that allows researchers and developers to create and combine multiple code-views which can be used by machine learning (ML) models for various SE tasks. Some salient features of our tool are: (i) it works directly on source code (which need not be compilable), (ii) it currently supports Java and C#, (iii) it can analyze both method-level snippets and program-level snippets by using both intra-procedural and inter-procedural analysis, and (iv) it is easily extendable to other languages as it is built on tree-sitter - a widely used incremental parser that supports over 40 languages. We believe this easy-to-use code-view generation and customization tool will give impetus to research in source code representation learning methods and ML4SE. Tool: https://pypi.org/project/comex - GitHub: https://github.com/IBM/tree-sitter-codeviews - Demo: https://youtu.be/GER6U87FVbU
Prompting with Pseudo-Code Instructions
May 22, 2023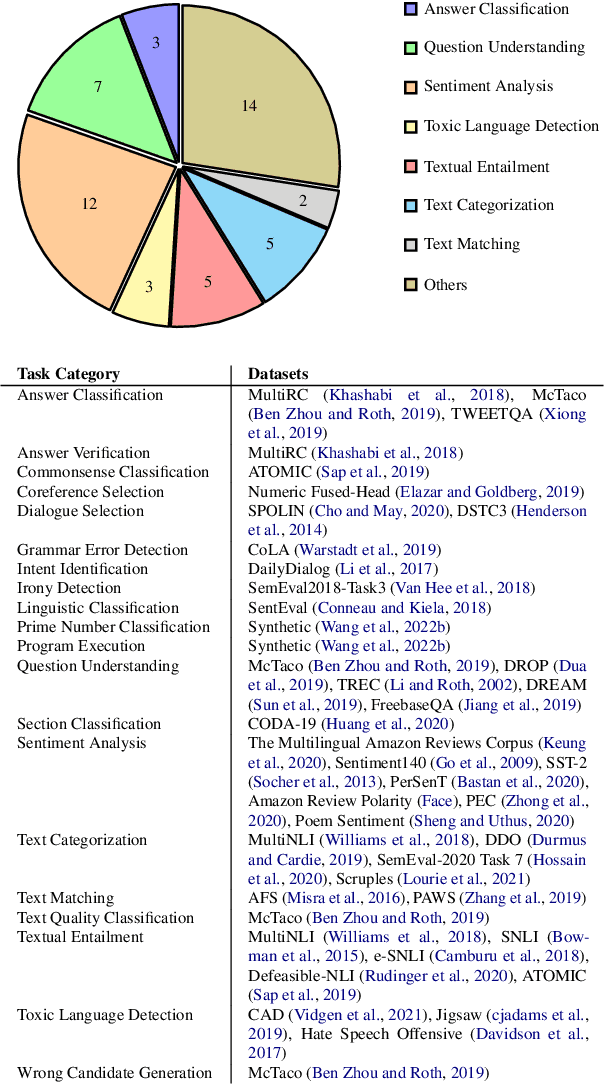
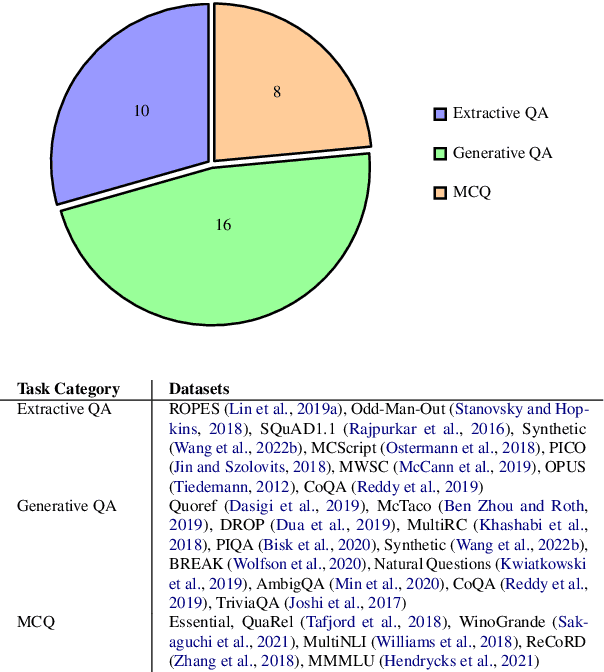
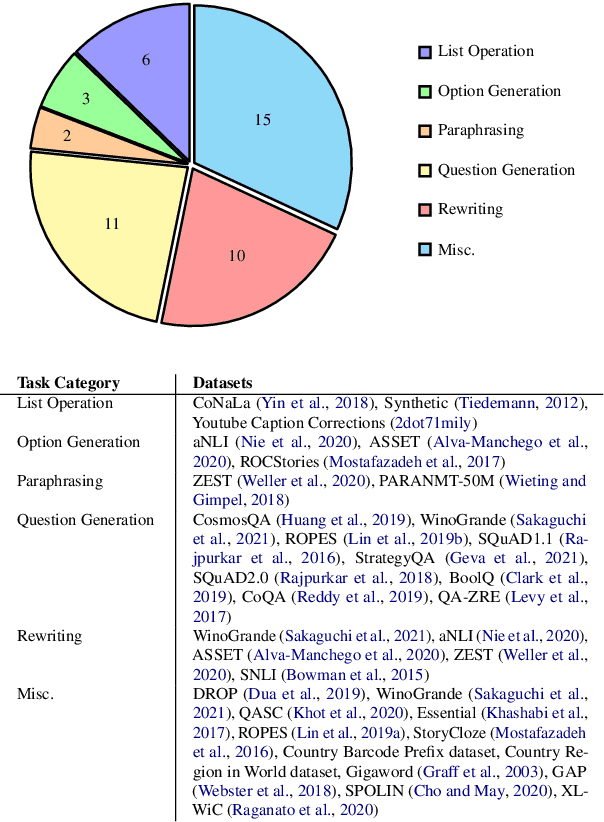
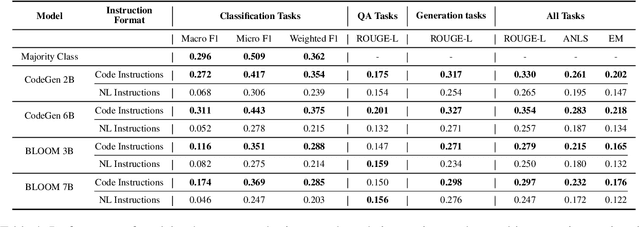
Prompting with natural language instructions has recently emerged as a popular method of harnessing the capabilities of large language models. Given the inherent ambiguity present in natural language, it is intuitive to consider the possible advantages of prompting with less ambiguous prompt styles, such as the use of pseudo-code. In this paper we explore if prompting via pseudo-code instructions helps improve the performance of pre-trained language models. We manually create a dataset of pseudo-code prompts for 132 different tasks spanning classification, QA and generative language tasks, sourced from the Super-NaturalInstructions dataset. Using these prompts along with their counterparts in natural language, we study their performance on two LLM families - BLOOM and CodeGen. Our experiments show that using pseudo-code instructions leads to better results, with an average increase (absolute) of 7-16 points in F1 scores for classification tasks and an improvement (relative) of 12-38% in aggregate ROUGE-L scores across all tasks. We include detailed ablation studies which indicate that code comments, docstrings, and the structural clues encoded in pseudo-code all contribute towards the improvement in performance. To the best of our knowledge our work is the first to demonstrate how pseudo-code prompts can be helpful in improving the performance of pre-trained LMs.
Monolith to Microservices: Representing Application Software through Heterogeneous GNN
Dec 17, 2021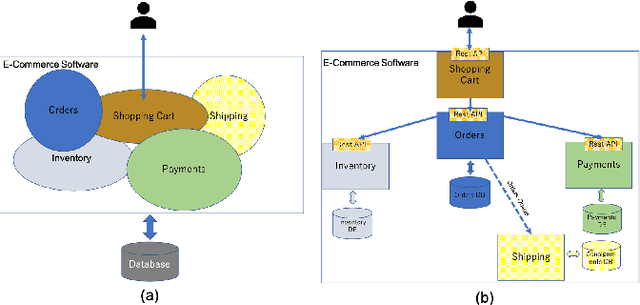


Monolith software applications encapsulate all functional capabilities into a single deployable unit. While there is an intention to maintain clean separation of functionalities even within the monolith, they tend to get compromised with the growing demand for new functionalities, changing team members, tough timelines, non-availability of skill sets, etc. As such applications age, they become hard to understand and maintain. Therefore, microservice architectures are increasingly used as they advocate building an application through multiple smaller sized, loosely coupled functional services, wherein each service owns a single functional responsibility. This approach has made microservices architecture as the natural choice for cloud based applications. But the challenges in the automated separation of functional modules for the already written monolith code slows down their migration task. Graphs are a natural choice to represent software applications. Various software artifacts like programs, tables and files become nodes in the graph and the different relationships they share, such as function calls, inheritance, resource(tables, files) access types (Create, Read, Update, Delete) can be represented as links in the graph. We therefore deduce this traditional application decomposition problem to a heterogeneous graph based clustering task. Our solution is the first of its kind to leverage heterogeneous graph neural network to learn representations of such diverse software entities and their relationships for the clustering task. We study the effectiveness by comparing with works from both software engineering and existing graph representation based techniques. We experiment with applications written in an object oriented language like Java and a procedural language like COBOL and show that our work is applicable across different programming paradigms.
Graph Neural Network to Dilute Outliers for Refactoring Monolith Application
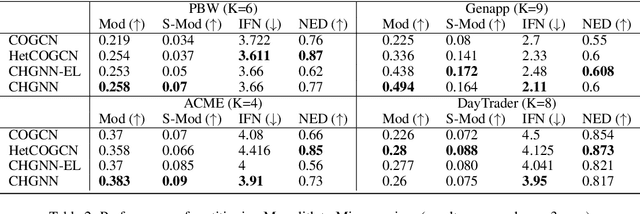
Feb 07, 2021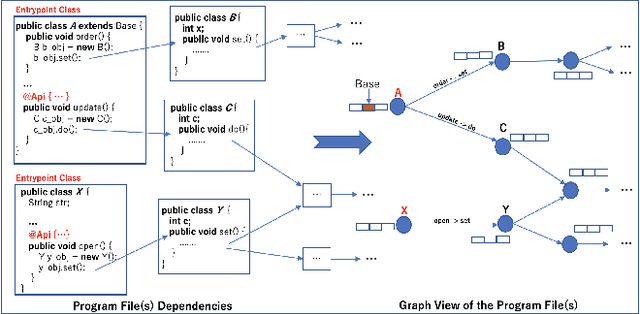
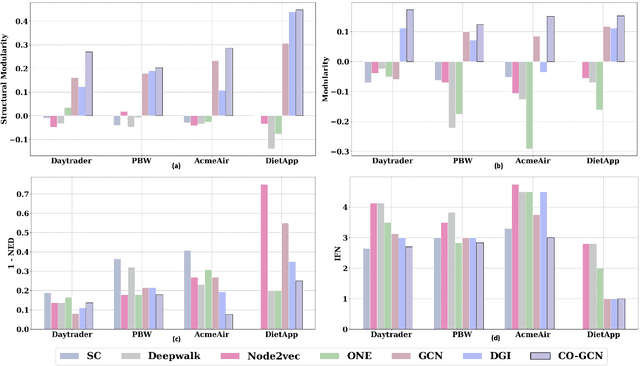
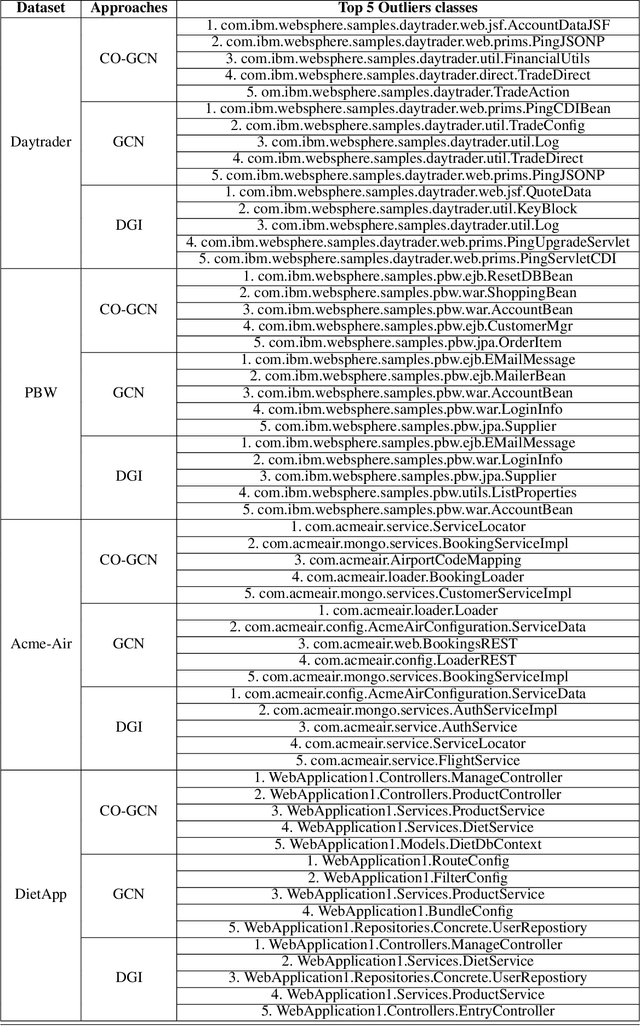
Microservices are becoming the defacto design choice for software architecture. It involves partitioning the software components into finer modules such that the development can happen independently. It also provides natural benefits when deployed on the cloud since resources can be allocated dynamically to necessary components based on demand. Therefore, enterprises as part of their journey to cloud, are increasingly looking to refactor their monolith application into one or more candidate microservices; wherein each service contains a group of software entities (e.g., classes) that are responsible for a common functionality. Graphs are a natural choice to represent a software system. Each software entity can be represented as nodes and its dependencies with other entities as links. Therefore, this problem of refactoring can be viewed as a graph based clustering task. In this work, we propose a novel method to adapt the recent advancements in graph neural networks in the context of code to better understand the software and apply them in the clustering task. In that process, we also identify the outliers in the graph which can be directly mapped to top refactor candidates in the software. Our solution is able to improve state-of-the-art performance compared to works from both software engineering and existing graph representation based techniques.
Adversarial Black-Box Attacks On Text Classifiers Using Multi-Objective Genetic Optimization Guided By Deep Networks
Nov 10, 2020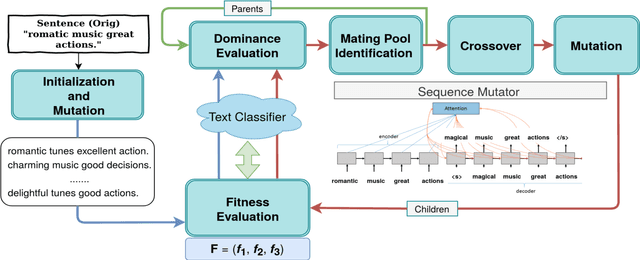


We propose a novel genetic-algorithm technique that generates black-box adversarial examples which successfully fool neural network based text classifiers. We perform a genetic search with multi-objective optimization guided by deep learning based inferences and Seq2Seq mutation to generate semantically similar but imperceptible adversaries. We compare our approach with DeepWordBug (DWB) on SST and IMDB sentiment datasets by attacking three trained models viz. char-LSTM, word-LSTM and elmo-LSTM. On an average, we achieve an attack success rate of 65.67% for SST and 36.45% for IMDB across the three models showing an improvement of 49.48% and 101% respectively. Furthermore, our qualitative study indicates that 94% of the time, the users were not able to distinguish between an original and adversarial sample.