 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScript Gap: Evaluating LLM Triage on Indian Languages in Native vs Roman Scripts in a Real World Setting
Dec 11, 2025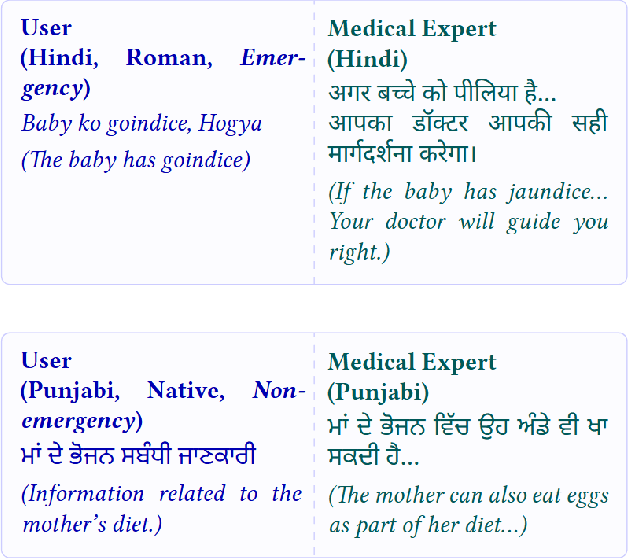
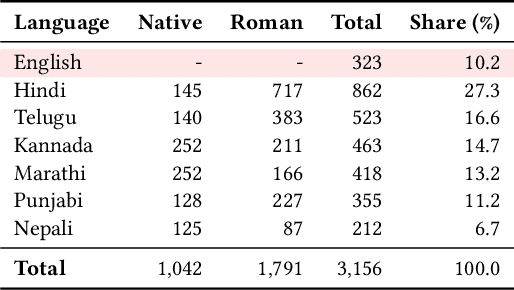


Large Language Models (LLMs) are increasingly deployed in high-stakes clinical applications in India. In many such settings, speakers of Indian languages frequently communicate using romanized text rather than native scripts, yet existing research rarely evaluates this orthographic variation using real-world data. We investigate how romanization impacts the reliability of LLMs in a critical domain: maternal and newborn healthcare triage. We benchmark leading LLMs on a real-world dataset of user-generated queries spanning five Indian languages and Nepali. Our results reveal consistent degradation in performance for romanized messages, with F1 scores trailing those of native scripts by 5-12 points. At our partner maternal health organization in India, this gap could cause nearly 2 million excess errors in triage. Crucially, this performance gap by scripts is not due to a failure in clinical reasoning. We demonstrate that LLMs often correctly infer the semantic intent of romanized queries. Nevertheless, their final classification outputs remain brittle in the presence of orthographic noise in romanized inputs. Our findings highlight a critical safety blind spot in LLM-based health systems: models that appear to understand romanized input may still fail to act on it reliably.
Monolith to Microservices: Representing Application Software through Heterogeneous GNN
Dec 17, 2021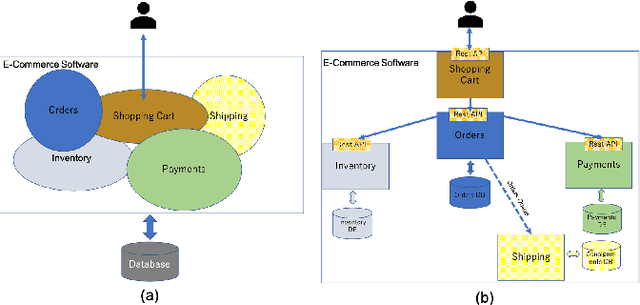


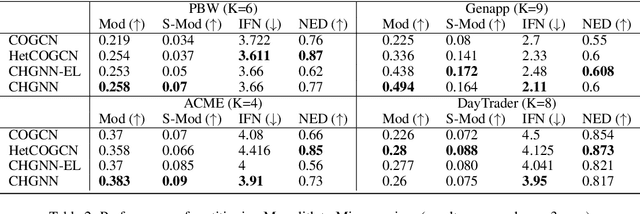
Monolith software applications encapsulate all functional capabilities into a single deployable unit. While there is an intention to maintain clean separation of functionalities even within the monolith, they tend to get compromised with the growing demand for new functionalities, changing team members, tough timelines, non-availability of skill sets, etc. As such applications age, they become hard to understand and maintain. Therefore, microservice architectures are increasingly used as they advocate building an application through multiple smaller sized, loosely coupled functional services, wherein each service owns a single functional responsibility. This approach has made microservices architecture as the natural choice for cloud based applications. But the challenges in the automated separation of functional modules for the already written monolith code slows down their migration task. Graphs are a natural choice to represent software applications. Various software artifacts like programs, tables and files become nodes in the graph and the different relationships they share, such as function calls, inheritance, resource(tables, files) access types (Create, Read, Update, Delete) can be represented as links in the graph. We therefore deduce this traditional application decomposition problem to a heterogeneous graph based clustering task. Our solution is the first of its kind to leverage heterogeneous graph neural network to learn representations of such diverse software entities and their relationships for the clustering task. We study the effectiveness by comparing with works from both software engineering and existing graph representation based techniques. We experiment with applications written in an object oriented language like Java and a procedural language like COBOL and show that our work is applicable across different programming paradigms.
Graph Neural Network to Dilute Outliers for Refactoring Monolith Application
Feb 07, 2021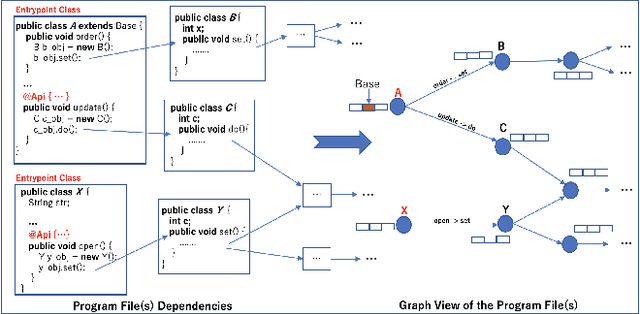
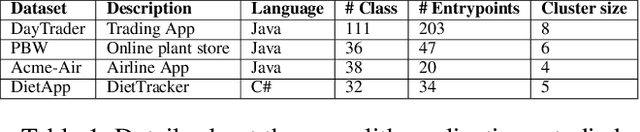
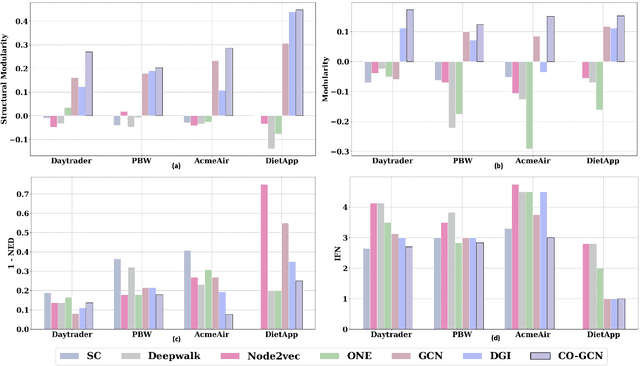
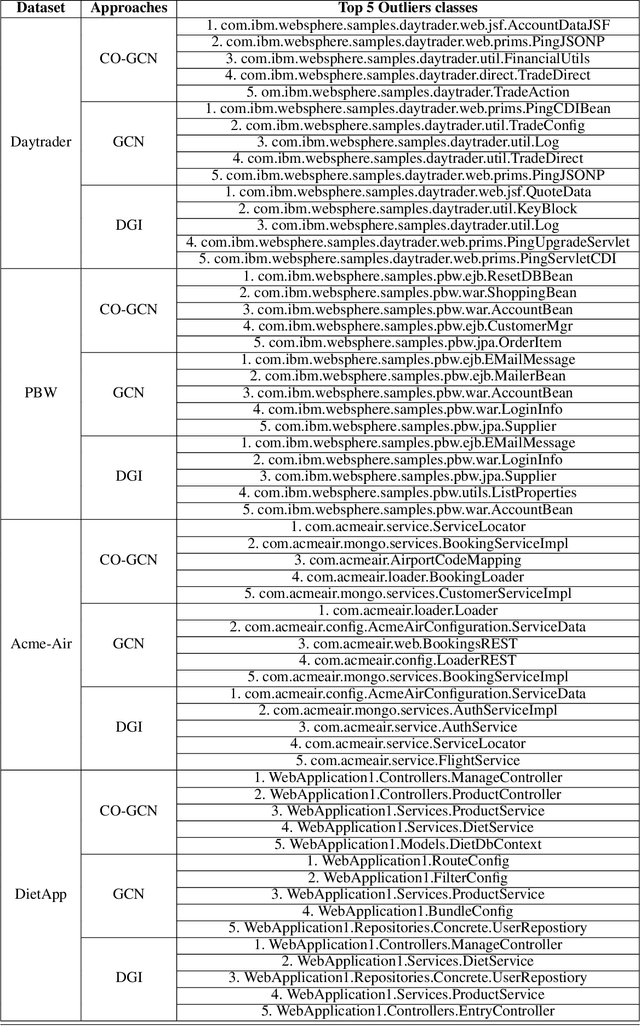
Microservices are becoming the defacto design choice for software architecture. It involves partitioning the software components into finer modules such that the development can happen independently. It also provides natural benefits when deployed on the cloud since resources can be allocated dynamically to necessary components based on demand. Therefore, enterprises as part of their journey to cloud, are increasingly looking to refactor their monolith application into one or more candidate microservices; wherein each service contains a group of software entities (e.g., classes) that are responsible for a common functionality. Graphs are a natural choice to represent a software system. Each software entity can be represented as nodes and its dependencies with other entities as links. Therefore, this problem of refactoring can be viewed as a graph based clustering task. In this work, we propose a novel method to adapt the recent advancements in graph neural networks in the context of code to better understand the software and apply them in the clustering task. In that process, we also identify the outliers in the graph which can be directly mapped to top refactor candidates in the software. Our solution is able to improve state-of-the-art performance compared to works from both software engineering and existing graph representation based techniques.
Benchmarking Popular Classification Models' Robustness to Random and Targeted Corruptions
Jan 31, 2020
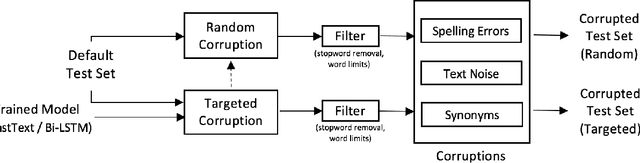

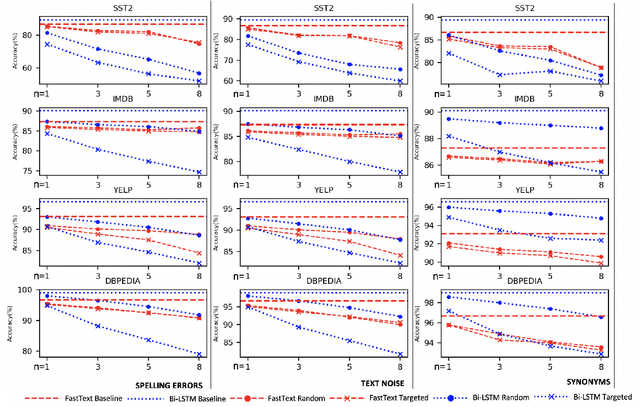
Text classification models, especially neural networks based models, have reached very high accuracy on many popular benchmark datasets. Yet, such models when deployed in real world applications, tend to perform badly. The primary reason is that these models are not tested against sufficient real world natural data. Based on the application users, the vocabulary and the style of the model's input may greatly vary. This emphasizes the need for a model agnostic test dataset, which consists of various corruptions that are natural to appear in the wild. Models trained and tested on such benchmark datasets, will be more robust against real world data. However, such data sets are not easily available. In this work, we address this problem, by extending the benchmark datasets along naturally occurring corruptions such as Spelling Errors, Text Noise and Synonyms and making them publicly available. Through extensive experiments, we compare random and targeted corruption strategies using Local Interpretable Model-Agnostic Explanations(LIME). We report the vulnerabilities in two popular text classification models along these corruptions and also find that targeted corruptions can expose vulnerabilities of a model better than random choices in most cases.