 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Use ChatGPT To Write Our Paper! Benchmarking LLMs To Write the Introduction of a Research Paper
Aug 19, 2025
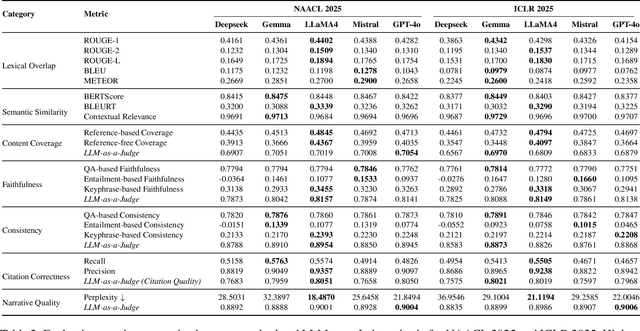
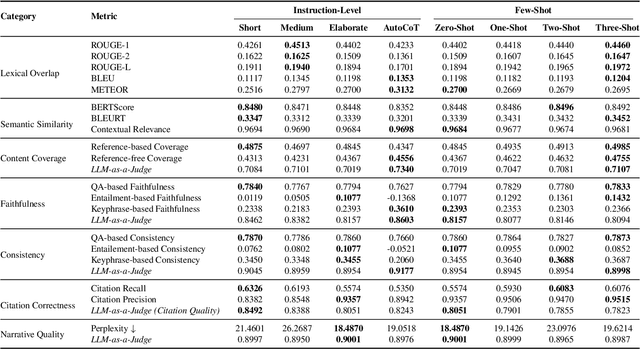
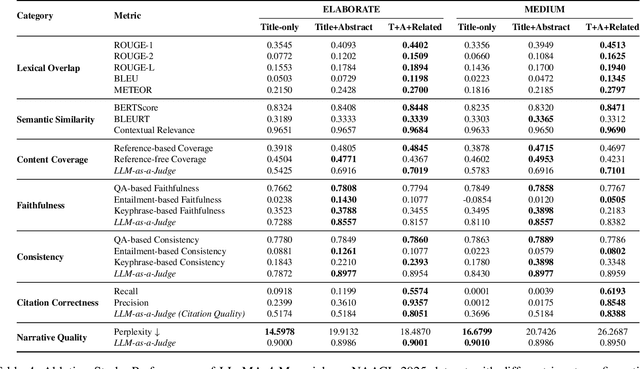
As researchers increasingly adopt LLMs as writing assistants, generating high-quality research paper introductions remains both challenging and essential. We introduce Scientific Introduction Generation (SciIG), a task that evaluates LLMs' ability to produce coherent introductions from titles, abstracts, and related works. Curating new datasets from NAACL 2025 and ICLR 2025 papers, we assess five state-of-the-art models, including both open-source (DeepSeek-v3, Gemma-3-12B, LLaMA 4-Maverick, MistralAI Small 3.1) and closed-source GPT-4o systems, across multiple dimensions: lexical overlap, semantic similarity, content coverage, faithfulness, consistency, citation correctness, and narrative quality. Our comprehensive framework combines automated metrics with LLM-as-a-judge evaluations. Results demonstrate LLaMA-4 Maverick's superior performance on most metrics, particularly in semantic similarity and faithfulness. Moreover, three-shot prompting consistently outperforms fewer-shot approaches. These findings provide practical insights into developing effective research writing assistants and set realistic expectations for LLM-assisted academic writing. To foster reproducibility and future research, we will publicly release all code and datasets.
Infogen: Generating Complex Statistical Infographics from Documents
Jul 26, 2025Statistical infographics are powerful tools that simplify complex data into visually engaging and easy-to-understand formats. Despite advancements in AI, particularly with LLMs, existing efforts have been limited to generating simple charts, with no prior work addressing the creation of complex infographics from text-heavy documents that demand a deep understanding of the content. We address this gap by introducing the task of generating statistical infographics composed of multiple sub-charts (e.g., line, bar, pie) that are contextually accurate, insightful, and visually aligned. To achieve this, we define infographic metadata that includes its title and textual insights, along with sub-chart-specific details such as their corresponding data and alignment. We also present Infodat, the first benchmark dataset for text-to-infographic metadata generation, where each sample links a document to its metadata. We propose Infogen, a two-stage framework where fine-tuned LLMs first generate metadata, which is then converted into infographic code. Extensive evaluations on Infodat demonstrate that Infogen achieves state-of-the-art performance, outperforming both closed and open-source LLMs in text-to-statistical infographic generation.
Leveraging Self-Attention for Input-Dependent Soft Prompting in LLMs
Jun 05, 2025


The performance of large language models in domain-specific tasks necessitates fine-tuning, which is computationally expensive and technically challenging. This paper focuses on parameter-efficient fine-tuning using soft prompting, a promising approach that adapts pre-trained models to downstream tasks by learning a small set of parameters. We propose a novel Input Dependent Soft Prompting technique with a self-Attention Mechanism (ID-SPAM) that generates soft prompts based on the input tokens and attends different tokens with varying importance. Our method is simple and efficient, keeping the number of trainable parameters small. We show the merits of the proposed approach compared to state-of-the-art techniques on various tasks and show the improved zero shot domain transfer capability.
Taming LLMs with Negative Samples: A Reference-Free Framework to Evaluate Presentation Content with Actionable Feedback
May 23, 2025The generation of presentation slides automatically is an important problem in the era of generative AI. This paper focuses on evaluating multimodal content in presentation slides that can effectively summarize a document and convey concepts to a broad audience. We introduce a benchmark dataset, RefSlides, consisting of human-made high-quality presentations that span various topics. Next, we propose a set of metrics to characterize different intrinsic properties of the content of a presentation and present REFLEX, an evaluation approach that generates scores and actionable feedback for these metrics. We achieve this by generating negative presentation samples with different degrees of metric-specific perturbations and use them to fine-tune LLMs. This reference-free evaluation technique does not require ground truth presentations during inference. Our extensive automated and human experiments demonstrate that our evaluation approach outperforms classical heuristic-based and state-of-the-art large language model-based evaluations in generating scores and explanations.
Is this a bad table? A Closer Look at the Evaluation of Table Generation from Text
Jun 21, 2024



Understanding whether a generated table is of good quality is important to be able to use it in creating or editing documents using automatic methods. In this work, we underline that existing measures for table quality evaluation fail to capture the overall semantics of the tables, and sometimes unfairly penalize good tables and reward bad ones. We propose TabEval, a novel table evaluation strategy that captures table semantics by first breaking down a table into a list of natural language atomic statements and then compares them with ground truth statements using entailment-based measures. To validate our approach, we curate a dataset comprising of text descriptions for 1,250 diverse Wikipedia tables, covering a range of topics and structures, in contrast to the limited scope of existing datasets. We compare TabEval with existing metrics using unsupervised and supervised text-to-table generation methods, demonstrating its stronger correlation with human judgments of table quality across four datasets.
Enhancing Presentation Slide Generation by LLMs with a Multi-Staged End-to-End Approach
Jun 01, 2024Generating presentation slides from a long document with multimodal elements such as text and images is an important task. This is time consuming and needs domain expertise if done manually. Existing approaches for generating a rich presentation from a document are often semi-automatic or only put a flat summary into the slides ignoring the importance of a good narrative. In this paper, we address this research gap by proposing a multi-staged end-to-end model which uses a combination of LLM and VLM. We have experimentally shown that compared to applying LLMs directly with state-of-the-art prompting, our proposed multi-staged solution is better in terms of automated metrics and human evaluation.
PostDoc: Generating Poster from a Long Multimodal Document Using Deep Submodular Optimization
May 30, 2024A poster from a long input document can be considered as a one-page easy-to-read multimodal (text and images) summary presented on a nice template with good design elements. Automatic transformation of a long document into a poster is a very less studied but challenging task. It involves content summarization of the input document followed by template generation and harmonization. In this work, we propose a novel deep submodular function which can be trained on ground truth summaries to extract multimodal content from the document and explicitly ensures good coverage, diversity and alignment of text and images. Then, we use an LLM based paraphraser and propose to generate a template with various design aspects conditioned on the input content. We show the merits of our approach through extensive automated and human evaluations.
Presentations are not always linear! GNN meets LLM for Document-to-Presentation Transformation with Attribution
May 21, 2024Automatically generating a presentation from the text of a long document is a challenging and useful problem. In contrast to a flat summary, a presentation needs to have a better and non-linear narrative, i.e., the content of a slide can come from different and non-contiguous parts of the given document. However, it is difficult to incorporate such non-linear mapping of content to slides and ensure that the content is faithful to the document. LLMs are prone to hallucination and their performance degrades with the length of the input document. Towards this, we propose a novel graph based solution where we learn a graph from the input document and use a combination of graph neural network and LLM to generate a presentation with attribution of content for each slide. We conduct thorough experiments to show the merit of our approach compared to directly using LLMs for this task.
Shopping Queries Dataset: A Large-Scale ESCI Benchmark for Improving Product Search
Jun 14, 2022


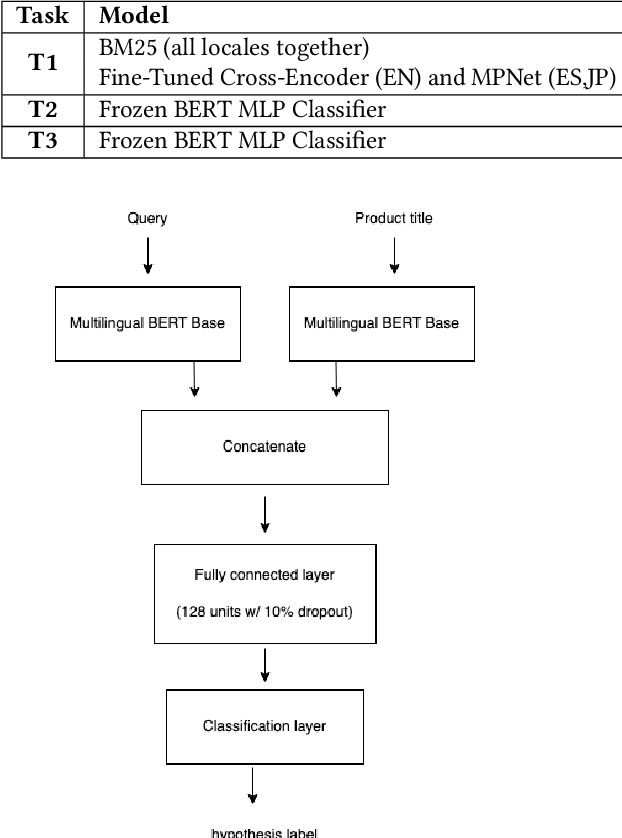
Improving the quality of search results can significantly enhance users experience and engagement with search engines. In spite of several recent advancements in the fields of machine learning and data mining, correctly classifying items for a particular user search query has been a long-standing challenge, which still has a large room for improvement. This paper introduces the "Shopping Queries Dataset", a large dataset of difficult Amazon search queries and results, publicly released with the aim of fostering research in improving the quality of search results. The dataset contains around 130 thousand unique queries and 2.6 million manually labeled (query,product) relevance judgements. The dataset is multilingual with queries in English, Japanese, and Spanish. The Shopping Queries Dataset is being used in one of the KDDCup'22 challenges. In this paper, we describe the dataset and present three evaluation tasks along with baseline results: (i) ranking the results list, (ii) classifying product results into relevance categories, and (iii) identifying substitute products for a given query. We anticipate that this data will become the gold standard for future research in the topic of product search.
Monolith to Microservices: Representing Application Software through Heterogeneous GNN
Dec 17, 2021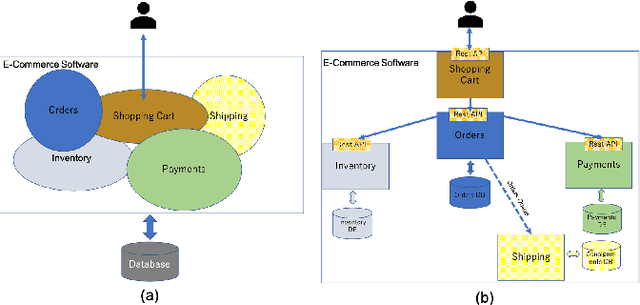


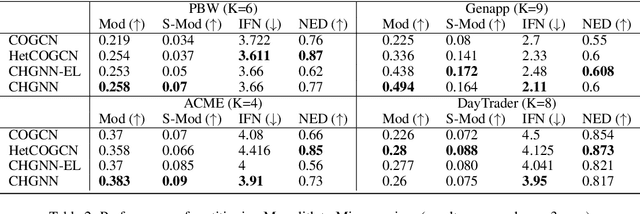
Monolith software applications encapsulate all functional capabilities into a single deployable unit. While there is an intention to maintain clean separation of functionalities even within the monolith, they tend to get compromised with the growing demand for new functionalities, changing team members, tough timelines, non-availability of skill sets, etc. As such applications age, they become hard to understand and maintain. Therefore, microservice architectures are increasingly used as they advocate building an application through multiple smaller sized, loosely coupled functional services, wherein each service owns a single functional responsibility. This approach has made microservices architecture as the natural choice for cloud based applications. But the challenges in the automated separation of functional modules for the already written monolith code slows down their migration task. Graphs are a natural choice to represent software applications. Various software artifacts like programs, tables and files become nodes in the graph and the different relationships they share, such as function calls, inheritance, resource(tables, files) access types (Create, Read, Update, Delete) can be represented as links in the graph. We therefore deduce this traditional application decomposition problem to a heterogeneous graph based clustering task. Our solution is the first of its kind to leverage heterogeneous graph neural network to learn representations of such diverse software entities and their relationships for the clustering task. We study the effectiveness by comparing with works from both software engineering and existing graph representation based techniques. We experiment with applications written in an object oriented language like Java and a procedural language like COBOL and show that our work is applicable across different programming paradigms.