 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShopping Queries Dataset: A Large-Scale ESCI Benchmark for Improving Product Search
Paper and Code



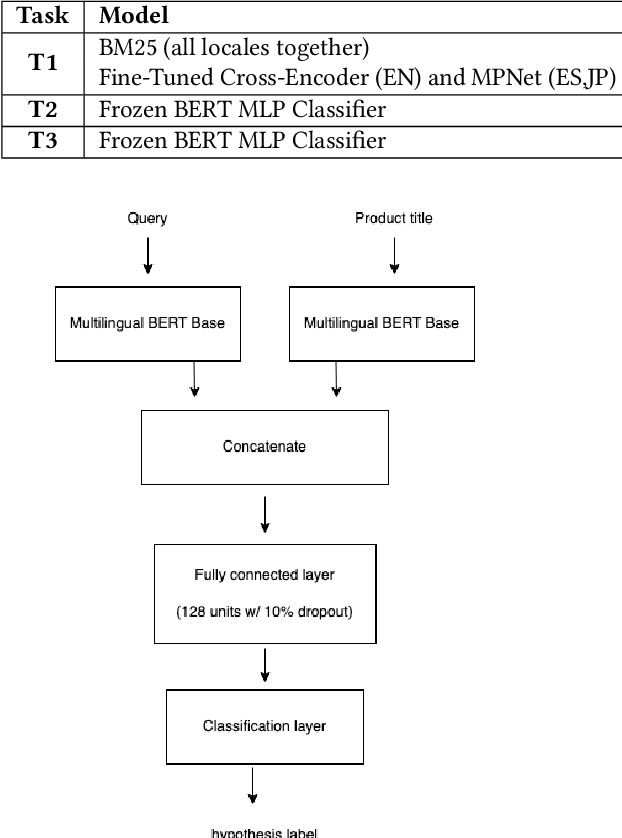
Improving the quality of search results can significantly enhance users experience and engagement with search engines. In spite of several recent advancements in the fields of machine learning and data mining, correctly classifying items for a particular user search query has been a long-standing challenge, which still has a large room for improvement. This paper introduces the "Shopping Queries Dataset", a large dataset of difficult Amazon search queries and results, publicly released with the aim of fostering research in improving the quality of search results. The dataset contains around 130 thousand unique queries and 2.6 million manually labeled (query,product) relevance judgements. The dataset is multilingual with queries in English, Japanese, and Spanish. The Shopping Queries Dataset is being used in one of the KDDCup'22 challenges. In this paper, we describe the dataset and present three evaluation tasks along with baseline results: (i) ranking the results list, (ii) classifying product results into relevance categories, and (iii) identifying substitute products for a given query. We anticipate that this data will become the gold standard for future research in the topic of product search.