 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Self-Attention for Input-Dependent Soft Prompting in LLMs
Jun 05, 2025The performance of large language models in domain-specific tasks necessitates fine-tuning, which is computationally expensive and technically challenging. This paper focuses on parameter-efficient fine-tuning using soft prompting, a promising approach that adapts pre-trained models to downstream tasks by learning a small set of parameters. We propose a novel Input Dependent Soft Prompting technique with a self-Attention Mechanism (ID-SPAM) that generates soft prompts based on the input tokens and attends different tokens with varying importance. Our method is simple and efficient, keeping the number of trainable parameters small. We show the merits of the proposed approach compared to state-of-the-art techniques on various tasks and show the improved zero shot domain transfer capability.
REFINE-AF: A Task-Agnostic Framework to Align Language Models via Self-Generated Instructions using Reinforcement Learning from Automated Feedback
May 10, 2025Instruction-based Large Language Models (LLMs) have proven effective in numerous few-shot or zero-shot Natural Language Processing (NLP) tasks. However, creating human-annotated instruction data is time-consuming, expensive, and often limited in quantity and task diversity. Previous research endeavors have attempted to address this challenge by proposing frameworks capable of generating instructions in a semi-automated and task-agnostic manner directly from the model itself. Many of these efforts have relied on large API-only parameter-based models such as GPT-3.5 (175B), which are expensive, and subject to limits on a number of queries. This paper explores the performance of three open-source small LLMs such as LLaMA 2-7B, LLama 2-13B, and Mistral 7B, using a semi-automated framework, thereby reducing human intervention, effort, and cost required to generate an instruction dataset for fine-tuning LLMs. Furthermore, we demonstrate that incorporating a Reinforcement Learning (RL) based training algorithm into this LLMs-based framework leads to further enhancements. Our evaluation of the dataset reveals that these RL-based frameworks achieve a substantial improvements in 63-66% of the tasks compared to previous approaches.
A Pointer Network-based Approach for Joint Extraction and Detection of Multi-Label Multi-Class Intents
Oct 29, 2024

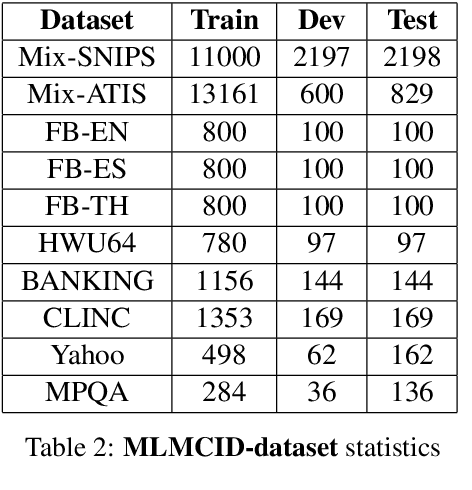
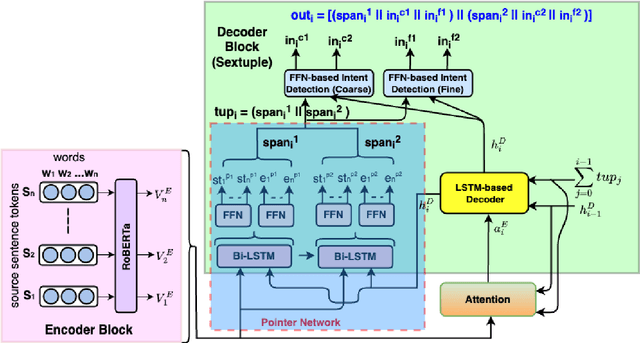
In task-oriented dialogue systems, intent detection is crucial for interpreting user queries and providing appropriate responses. Existing research primarily addresses simple queries with a single intent, lacking effective systems for handling complex queries with multiple intents and extracting different intent spans. Additionally, there is a notable absence of multilingual, multi-intent datasets. This study addresses three critical tasks: extracting multiple intent spans from queries, detecting multiple intents, and developing a multi-lingual multi-label intent dataset. We introduce a novel multi-label multi-class intent detection dataset (MLMCID-dataset) curated from existing benchmark datasets. We also propose a pointer network-based architecture (MLMCID) to extract intent spans and detect multiple intents with coarse and fine-grained labels in the form of sextuplets. Comprehensive analysis demonstrates the superiority of our pointer network-based system over baseline approaches in terms of accuracy and F1-score across various datasets.
SERPENT-VLM : Self-Refining Radiology Report Generation Using Vision Language Models
Apr 27, 2024Radiology Report Generation (R2Gen) demonstrates how Multi-modal Large Language Models (MLLMs) can automate the creation of accurate and coherent radiological reports. Existing methods often hallucinate details in text-based reports that don't accurately reflect the image content. To mitigate this, we introduce a novel strategy, SERPENT-VLM (SElf Refining Radiology RePort GENeraTion using Vision Language Models), which improves the R2Gen task by integrating a self-refining mechanism into the MLLM framework. We employ a unique self-supervised loss that leverages similarity between pooled image representations and the contextual representations of the generated radiological text, alongside the standard Causal Language Modeling objective, to refine image-text representations. This allows the model to scrutinize and align the generated text through dynamic interaction between a given image and the generated text, therefore reducing hallucination and continuously enhancing nuanced report generation. SERPENT-VLM outperforms existing baselines such as LLaVA-Med, BiomedGPT, etc., achieving SoTA performance on the IU X-ray and Radiology Objects in COntext (ROCO) datasets, and also proves to be robust against noisy images. A qualitative case study emphasizes the significant advancements towards more sophisticated MLLM frameworks for R2Gen, opening paths for further research into self-supervised refinement in the medical imaging domain.
Order-Based Pre-training Strategies for Procedural Text Understanding
Apr 06, 2024



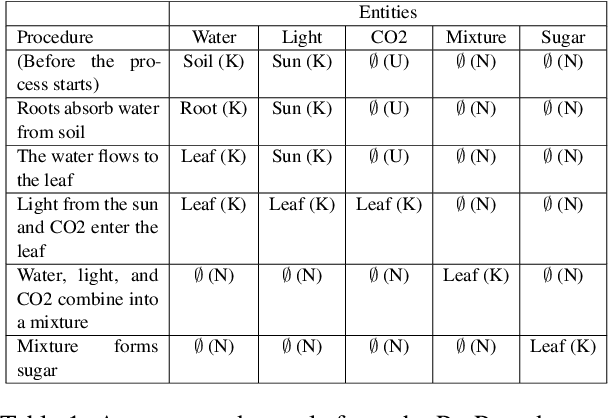
In this paper, we propose sequence-based pretraining methods to enhance procedural understanding in natural language processing. Procedural text, containing sequential instructions to accomplish a task, is difficult to understand due to the changing attributes of entities in the context. We focus on recipes, which are commonly represented as ordered instructions, and use this order as a supervision signal. Our work is one of the first to compare several 'order as-supervision' transformer pre-training methods, including Permutation Classification, Embedding Regression, and Skip-Clip, and shows that these methods give improved results compared to the baselines and SoTA LLMs on two downstream Entity-Tracking datasets: NPN-Cooking dataset in recipe domain and ProPara dataset in open domain. Our proposed methods address the non-trivial Entity Tracking Task that requires prediction of entity states across procedure steps, which requires understanding the order of steps. These methods show an improvement over the best baseline by 1.6% and 7-9% on NPN-Cooking and ProPara Datasets respectively across metrics.
CLMSM: A Multi-Task Learning Framework for Pre-training on Procedural Text
Oct 22, 2023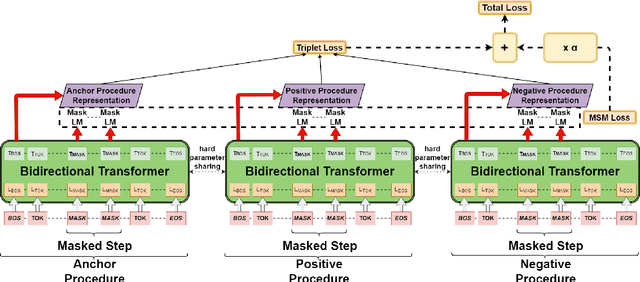
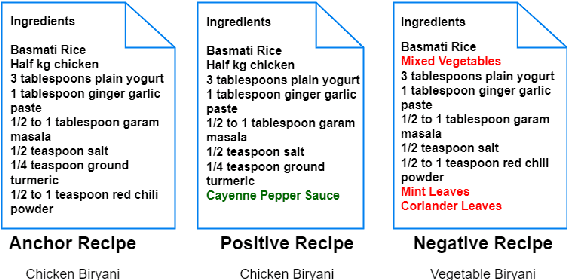
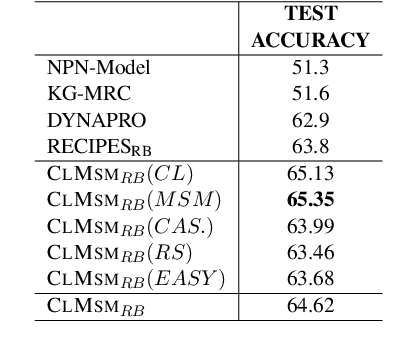
In this paper, we propose CLMSM, a domain-specific, continual pre-training framework, that learns from a large set of procedural recipes. CLMSM uses a Multi-Task Learning Framework to optimize two objectives - a) Contrastive Learning using hard triplets to learn fine-grained differences across entities in the procedures, and b) a novel Mask-Step Modelling objective to learn step-wise context of a procedure. We test the performance of CLMSM on the downstream tasks of tracking entities and aligning actions between two procedures on three datasets, one of which is an open-domain dataset not conforming with the pre-training dataset. We show that CLMSM not only outperforms baselines on recipes (in-domain) but is also able to generalize to open-domain procedural NLP tasks.
$FPDM$: Domain-Specific Fast Pre-training Technique using Document-Level Metadata
Jun 09, 2023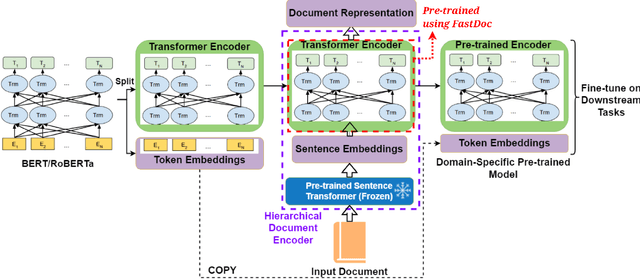

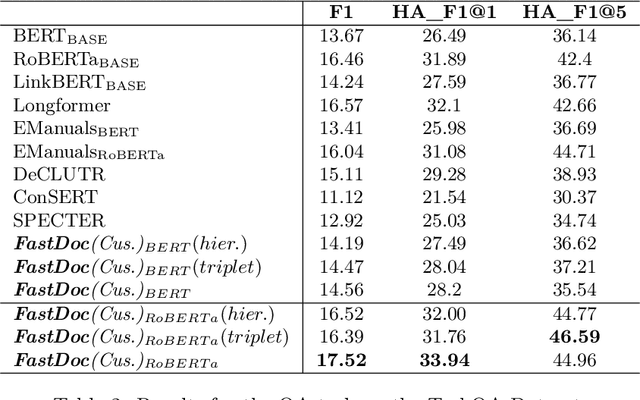
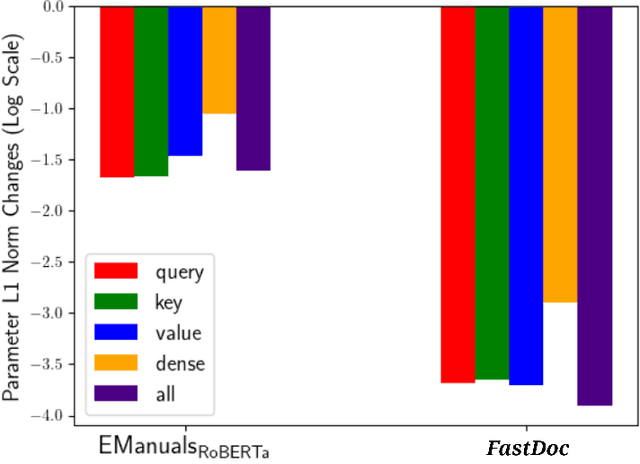
Pre-training Transformers has shown promising results on open-domain and domain-specific downstream tasks. However, state-of-the-art Transformers require an unreasonably large amount of pre-training data and compute. In this paper, we propose $FPDM$ (Fast Pre-training Technique using Document Level Metadata), a novel, compute-efficient framework that utilizes Document metadata and Domain-Specific Taxonomy as supervision signals to pre-train transformer encoder on a domain-specific corpus. The main innovation is that during domain-specific pretraining, an open-domain encoder is continually pre-trained using sentence-level embeddings as inputs (to accommodate long documents), however, fine-tuning is done with token-level embeddings as inputs to this encoder. We show that $FPDM$ outperforms several transformer-based baselines in terms of character-level F1 scores and other automated metrics in the Customer Support, Scientific, and Legal Domains, and shows a negligible drop in performance on open-domain benchmarks. Importantly, the novel use of document-level supervision along with sentence-level embedding input for pre-training reduces pre-training compute by around $1,000$, $4,500$, and $500$ times compared to MLM and/or NSP in Customer Support, Scientific, and Legal Domains, respectively. Code and datasets are available at https://bit.ly/FPDMCode.
An Evaluation Framework for Legal Document Summarization
May 17, 2022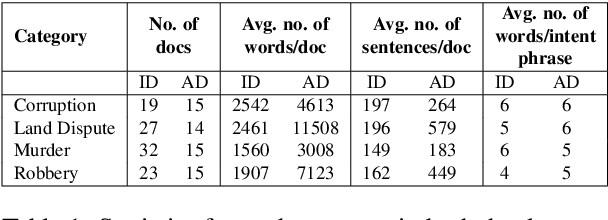
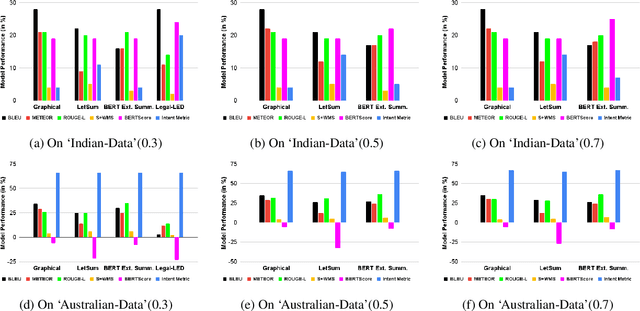
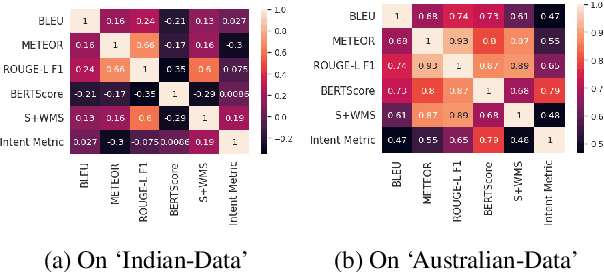
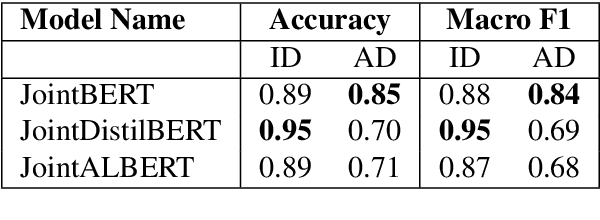
A law practitioner has to go through numerous lengthy legal case proceedings for their practices of various categories, such as land dispute, corruption, etc. Hence, it is important to summarize these documents, and ensure that summaries contain phrases with intent matching the category of the case. To the best of our knowledge, there is no evaluation metric that evaluates a summary based on its intent. We propose an automated intent-based summarization metric, which shows a better agreement with human evaluation as compared to other automated metrics like BLEU, ROUGE-L etc. in terms of human satisfaction. We also curate a dataset by annotating intent phrases in legal documents, and show a proof of concept as to how this system can be automated. Additionally, all the code and data to generate reproducible results is available on Github.
Fine-grained Intent Classification in the Legal Domain
May 06, 2022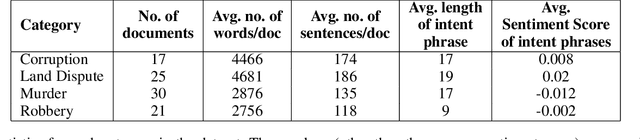

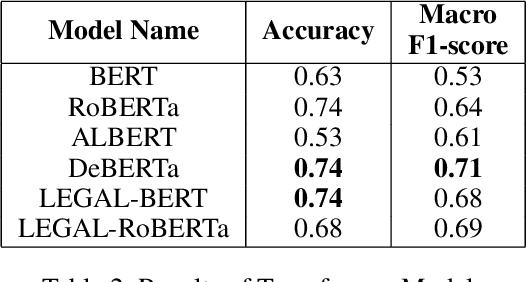
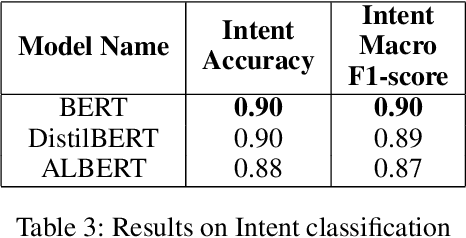
A law practitioner has to go through a lot of long legal case proceedings. To understand the motivation behind the actions of different parties/individuals in a legal case, it is essential that the parts of the document that express an intent corresponding to the case be clearly understood. In this paper, we introduce a dataset of 93 legal documents, belonging to the case categories of either Murder, Land Dispute, Robbery, or Corruption, where phrases expressing intent same as the category of the document are annotated. Also, we annotate fine-grained intents for each such phrase to enable a deeper understanding of the case for a reader. Finally, we analyze the performance of several transformer-based models in automating the process of extracting intent phrases (both at a coarse and a fine-grained level), and classifying a document into one of the possible 4 categories, and observe that, our dataset is challenging, especially in the case of fine-grained intent classification.
Team Enigma at ArgMining-EMNLP 2021: Leveraging Pre-trained Language Models for Key Point Matching
Oct 24, 2021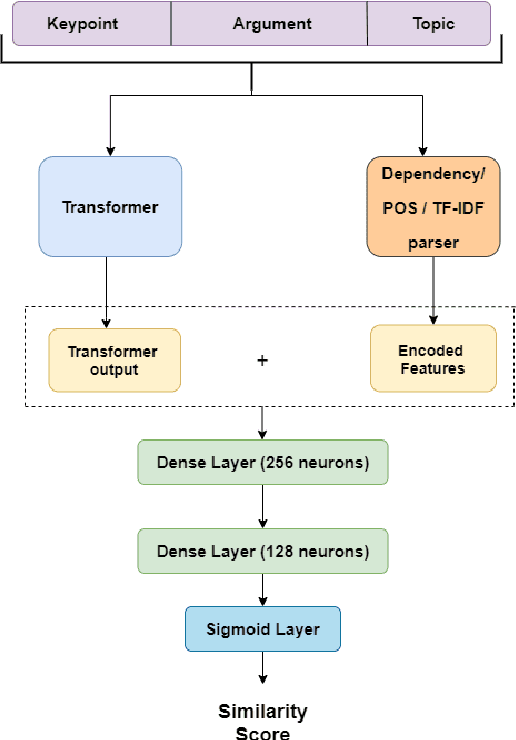
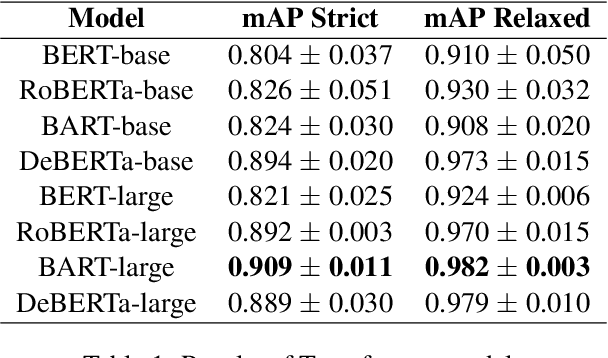
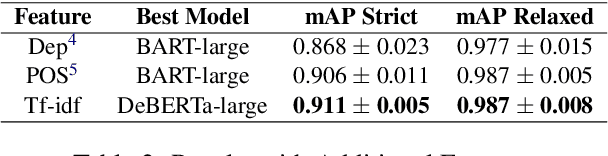
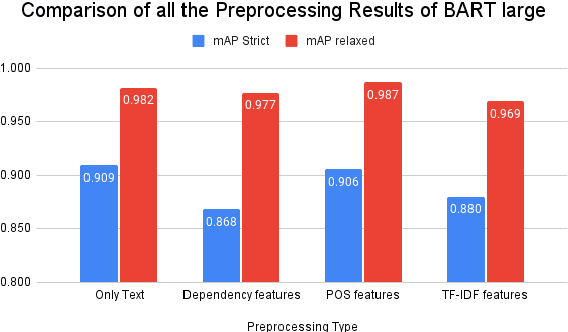
We present the system description for our submission towards the Key Point Analysis Shared Task at ArgMining 2021. Track 1 of the shared task requires participants to develop methods to predict the match score between each pair of arguments and keypoints, provided they belong to the same topic under the same stance. We leveraged existing state of the art pre-trained language models along with incorporating additional data and features extracted from the inputs (topics, key points, and arguments) to improve performance. We were able to achieve mAP strict and mAP relaxed score of 0.872 and 0.966 respectively in the evaluation phase, securing 5th place on the leaderboard. In the post evaluation phase, we achieved a mAP strict and mAP relaxed score of 0.921 and 0.982 respectively. All the codes to generate reproducible results on our models are available on Github.