 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt Helps to Take a Second Opinion: Teaching Smaller LLMs to Deliberate Mutually via Selective Rationale Optimisation
Mar 04, 2025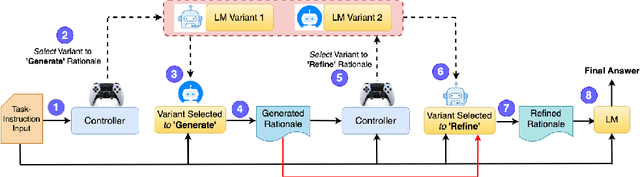
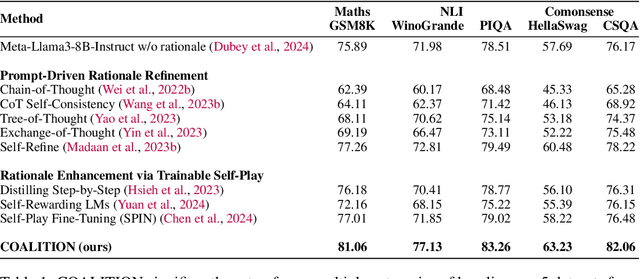
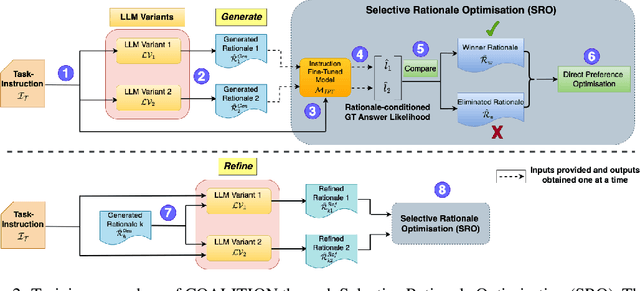

Very large language models (LLMs) such as GPT-4 have shown the ability to handle complex tasks by generating and self-refining step-by-step rationales. Smaller language models (SLMs), typically with < 13B parameters, have been improved by using the data generated from very-large LMs through knowledge distillation. However, various practical constraints such as API costs, copyright, legal and ethical policies restrict using large (often opaque) models to train smaller models for commercial use. Limited success has been achieved at improving the ability of an SLM to explore the space of possible rationales and evaluate them by itself through self-deliberation. To address this, we propose COALITION, a trainable framework that facilitates interaction between two variants of the same SLM and trains them to generate and refine rationales optimized for the end-task. The variants exhibit different behaviors to produce a set of diverse candidate rationales during the generation and refinement steps. The model is then trained via Selective Rationale Optimization (SRO) to prefer generating rationale candidates that maximize the likelihood of producing the ground-truth answer. During inference, COALITION employs a controller to select the suitable variant for generating and refining the rationales. On five different datasets covering mathematical problems, commonsense reasoning, and natural language inference, COALITION outperforms several baselines by up to 5%. Our ablation studies reveal that cross-communication between the two variants performs better than using the single model to self-refine the rationales. We also demonstrate the applicability of COALITION for LMs of varying scales (4B to 14B parameters) and model families (Mistral, Llama, Qwen, Phi). We release the code for this work at https://github.com/Sohanpatnaik106/coalition.
SERPENT-VLM : Self-Refining Radiology Report Generation Using Vision Language Models
Apr 27, 2024Radiology Report Generation (R2Gen) demonstrates how Multi-modal Large Language Models (MLLMs) can automate the creation of accurate and coherent radiological reports. Existing methods often hallucinate details in text-based reports that don't accurately reflect the image content. To mitigate this, we introduce a novel strategy, SERPENT-VLM (SElf Refining Radiology RePort GENeraTion using Vision Language Models), which improves the R2Gen task by integrating a self-refining mechanism into the MLLM framework. We employ a unique self-supervised loss that leverages similarity between pooled image representations and the contextual representations of the generated radiological text, alongside the standard Causal Language Modeling objective, to refine image-text representations. This allows the model to scrutinize and align the generated text through dynamic interaction between a given image and the generated text, therefore reducing hallucination and continuously enhancing nuanced report generation. SERPENT-VLM outperforms existing baselines such as LLaVA-Med, BiomedGPT, etc., achieving SoTA performance on the IU X-ray and Radiology Objects in COntext (ROCO) datasets, and also proves to be robust against noisy images. A qualitative case study emphasizes the significant advancements towards more sophisticated MLLM frameworks for R2Gen, opening paths for further research into self-supervised refinement in the medical imaging domain.
CABINET: Content Relevance based Noise Reduction for Table Question Answering
Feb 05, 2024



Table understanding capability of Large Language Models (LLMs) has been extensively studied through the task of question-answering (QA) over tables. Typically, only a small part of the whole table is relevant to derive the answer for a given question. The irrelevant parts act as noise and are distracting information, resulting in sub-optimal performance due to the vulnerability of LLMs to noise. To mitigate this, we propose CABINET (Content RelevAnce-Based NoIse ReductioN for TablE QuesTion-Answering) - a framework to enable LLMs to focus on relevant tabular data by suppressing extraneous information. CABINET comprises an Unsupervised Relevance Scorer (URS), trained differentially with the QA LLM, that weighs the table content based on its relevance to the input question before feeding it to the question-answering LLM (QA LLM). To further aid the relevance scorer, CABINET employs a weakly supervised module that generates a parsing statement describing the criteria of rows and columns relevant to the question and highlights the content of corresponding table cells. CABINET significantly outperforms various tabular LLM baselines, as well as GPT3-based in-context learning methods, is more robust to noise, maintains outperformance on tables of varying sizes, and establishes new SoTA performance on WikiTQ, FeTaQA, and WikiSQL datasets. We release our code and datasets at https://github.com/Sohanpatnaik106/CABINET_QA.
SepHRNet: Generating High-Resolution Crop Maps from Remote Sensing imagery using HRNet with Separable Convolution
Jul 11, 2023The accurate mapping of crop production is crucial for ensuring food security, effective resource management, and sustainable agricultural practices. One way to achieve this is by analyzing high-resolution satellite imagery. Deep Learning has been successful in analyzing images, including remote sensing imagery. However, capturing intricate crop patterns is challenging due to their complexity and variability. In this paper, we propose a novel Deep learning approach that integrates HRNet with Separable Convolutional layers to capture spatial patterns and Self-attention to capture temporal patterns of the data. The HRNet model acts as a backbone and extracts high-resolution features from crop images. Spatially separable convolution in the shallow layers of the HRNet model captures intricate crop patterns more effectively while reducing the computational cost. The multi-head attention mechanism captures long-term temporal dependencies from the encoded vector representation of the images. Finally, a CNN decoder generates a crop map from the aggregated representation. Adaboost is used on top of this to further improve accuracy. The proposed algorithm achieves a high classification accuracy of 97.5\% and IoU of 55.2\% in generating crop maps. We evaluate the performance of our pipeline on the Zuericrop dataset and demonstrate that our results outperform state-of-the-art models such as U-Net++, ResNet50, VGG19, InceptionV3, DenseNet, and EfficientNet. This research showcases the potential of Deep Learning for Earth Observation Systems.
$FPDM$: Domain-Specific Fast Pre-training Technique using Document-Level Metadata
Jun 09, 2023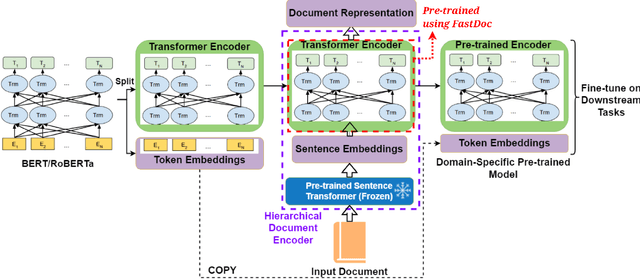

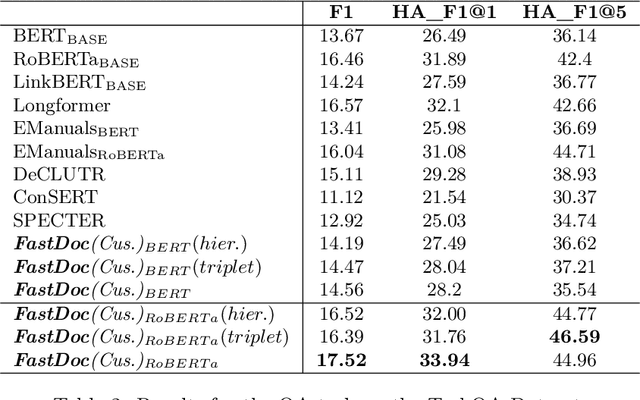
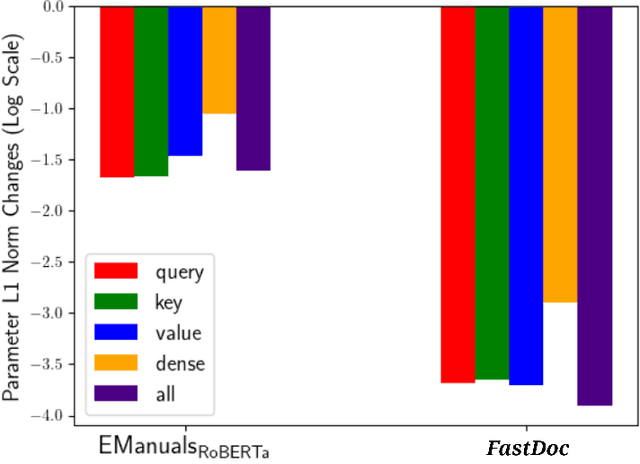
Pre-training Transformers has shown promising results on open-domain and domain-specific downstream tasks. However, state-of-the-art Transformers require an unreasonably large amount of pre-training data and compute. In this paper, we propose $FPDM$ (Fast Pre-training Technique using Document Level Metadata), a novel, compute-efficient framework that utilizes Document metadata and Domain-Specific Taxonomy as supervision signals to pre-train transformer encoder on a domain-specific corpus. The main innovation is that during domain-specific pretraining, an open-domain encoder is continually pre-trained using sentence-level embeddings as inputs (to accommodate long documents), however, fine-tuning is done with token-level embeddings as inputs to this encoder. We show that $FPDM$ outperforms several transformer-based baselines in terms of character-level F1 scores and other automated metrics in the Customer Support, Scientific, and Legal Domains, and shows a negligible drop in performance on open-domain benchmarks. Importantly, the novel use of document-level supervision along with sentence-level embedding input for pre-training reduces pre-training compute by around $1,000$, $4,500$, and $500$ times compared to MLM and/or NSP in Customer Support, Scientific, and Legal Domains, respectively. Code and datasets are available at https://bit.ly/FPDMCode.
An Evaluation Framework for Legal Document Summarization
May 17, 2022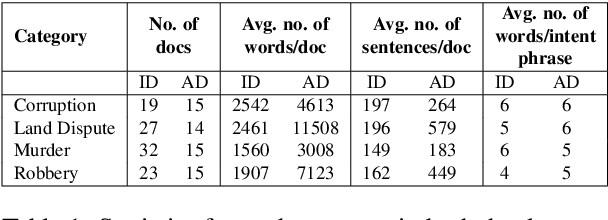
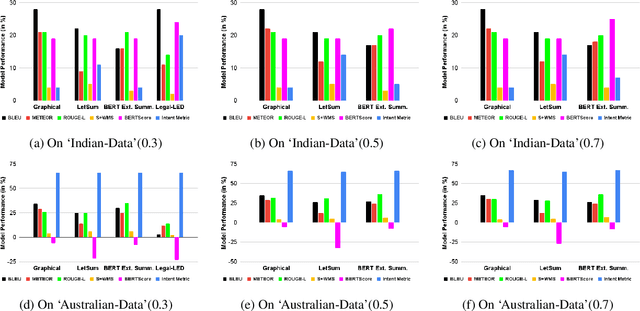
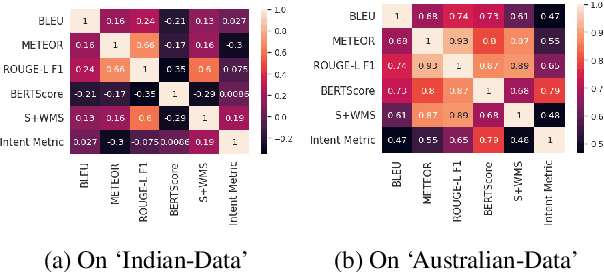
A law practitioner has to go through numerous lengthy legal case proceedings for their practices of various categories, such as land dispute, corruption, etc. Hence, it is important to summarize these documents, and ensure that summaries contain phrases with intent matching the category of the case. To the best of our knowledge, there is no evaluation metric that evaluates a summary based on its intent. We propose an automated intent-based summarization metric, which shows a better agreement with human evaluation as compared to other automated metrics like BLEU, ROUGE-L etc. in terms of human satisfaction. We also curate a dataset by annotating intent phrases in legal documents, and show a proof of concept as to how this system can be automated. Additionally, all the code and data to generate reproducible results is available on Github.
Fine-grained Intent Classification in the Legal Domain
May 06, 2022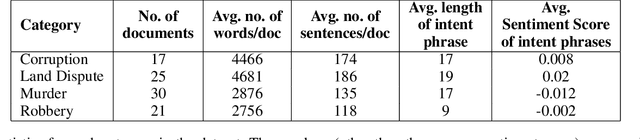

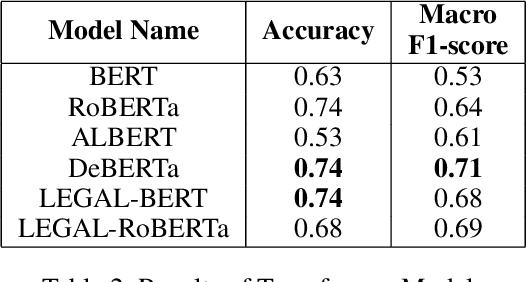
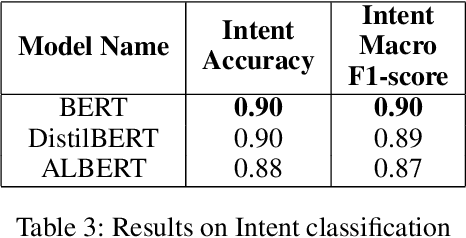
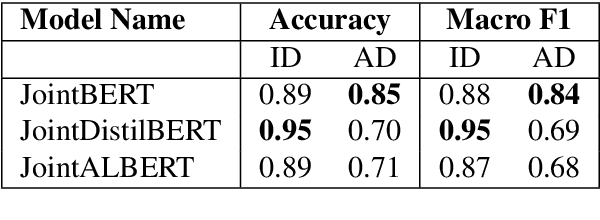
A law practitioner has to go through a lot of long legal case proceedings. To understand the motivation behind the actions of different parties/individuals in a legal case, it is essential that the parts of the document that express an intent corresponding to the case be clearly understood. In this paper, we introduce a dataset of 93 legal documents, belonging to the case categories of either Murder, Land Dispute, Robbery, or Corruption, where phrases expressing intent same as the category of the document are annotated. Also, we annotate fine-grained intents for each such phrase to enable a deeper understanding of the case for a reader. Finally, we analyze the performance of several transformer-based models in automating the process of extracting intent phrases (both at a coarse and a fine-grained level), and classifying a document into one of the possible 4 categories, and observe that, our dataset is challenging, especially in the case of fine-grained intent classification.
Team Enigma at ArgMining-EMNLP 2021: Leveraging Pre-trained Language Models for Key Point Matching
Oct 24, 2021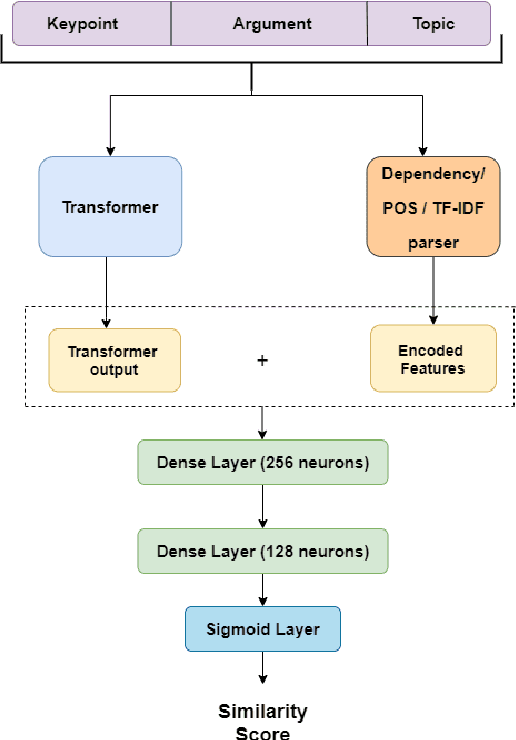
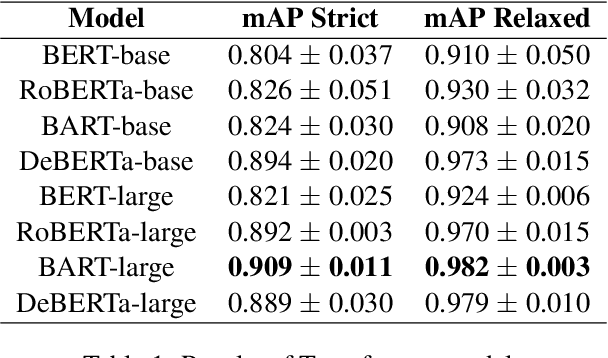
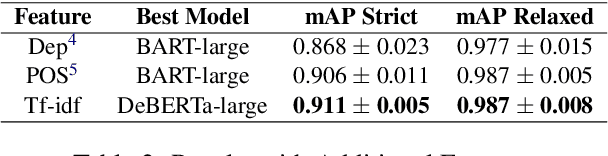
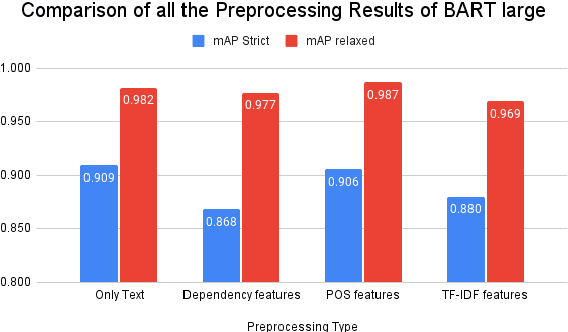
We present the system description for our submission towards the Key Point Analysis Shared Task at ArgMining 2021. Track 1 of the shared task requires participants to develop methods to predict the match score between each pair of arguments and keypoints, provided they belong to the same topic under the same stance. We leveraged existing state of the art pre-trained language models along with incorporating additional data and features extracted from the inputs (topics, key points, and arguments) to improve performance. We were able to achieve mAP strict and mAP relaxed score of 0.872 and 0.966 respectively in the evaluation phase, securing 5th place on the leaderboard. In the post evaluation phase, we achieved a mAP strict and mAP relaxed score of 0.921 and 0.982 respectively. All the codes to generate reproducible results on our models are available on Github.
A data-science-driven short-term analysis of Amazon, Apple, Google, and Microsoft stocks
Jul 30, 2021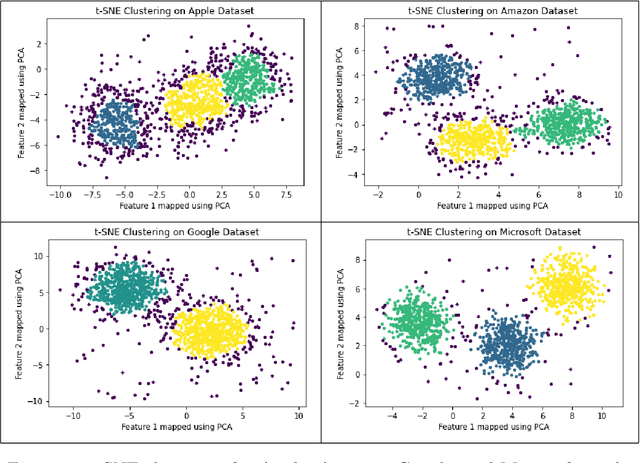
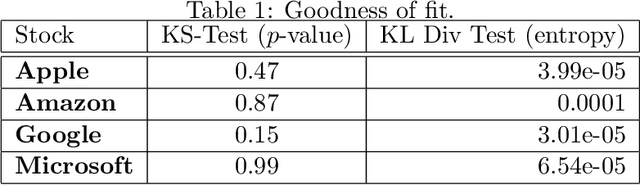
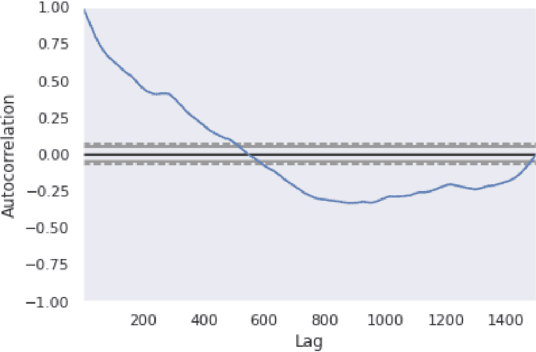
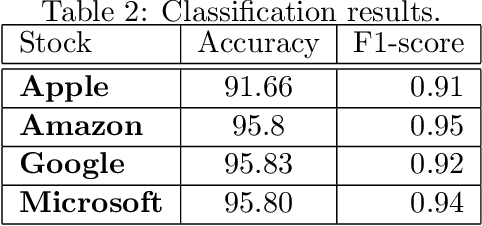
In this paper, we implement a combination of technical analysis and machine/deep learning-based analysis to build a trend classification model. The goal of the paper is to apprehend short-term market movement, and incorporate it to improve the underlying stochastic model. Also, the analysis presented in this paper can be implemented in a \emph{model-independent} fashion. We execute a data-science-driven technique that makes short-term forecasts dependent on the price trends of current stock market data. Based on the analysis, three different labels are generated for a data set: $+1$ (buy signal), $0$ (hold signal), or $-1$ (sell signal). We propose a detailed analysis of four major stocks- Amazon, Apple, Google, and Microsoft. We implement various technical indicators to label the data set according to the trend and train various models for trend estimation. Statistical analysis of the outputs and classification results are obtained.